昨天,vivo发布 OriginOS 4系统。
里面有个很好玩的东西,我觉得,值得跟大家聊聊,未来的摄影革新,没准就暗藏在里面。

前不久,看到过一条新闻,说vivo自研的AI大模型同时位列C-Eval、CMMLU双榜的全球中文榜单榜首,在人文、社科等领域的表现远超同级别大模型。
就在上周末,手机收到了OriginOS 4升级推送,于是有机会提前试用了一下这款大模型(预览版)。
vivo的这个大模型使用起来很简单,只需要滑动右侧屏幕,就可以调出小V助手的对话框,输入你的指令。

提到大模型,肯定绕不开chatGPT。
chatGPT在包括“对话、摘要、内容生成、问题解答、识图、数学计算与推理、代码编写”等方面。而在AIGC领域,两个比较火的软件是Stable Diffusion和Midjourney了,作为文生图的这两款软件,在国内的社交网络上,也是一路走红。
但是,因为使用上有一定的门槛(比如语言、金钱),所以,相信绝大多数人都没能体会到大模型对于我们日常生活提供的便利。
而vivo的大模型,就融合了以上的种种功能。
先简单说几个有趣的功能吧。
比如,如果你是职场人。它可以帮助你写工作总结、活动计划,业务分析。



如果你是学生,它可以帮你翻译论文、数理计算、问题解答。


对于任何一个普通人,它可以帮你在消费之后写点评,发朋友圈、小红书时写文案,逢年过节编段子。



这一切,大模型都可以为你代劳。
但作为一个摄影博主,我对于大模型感兴趣的点更在于其会对影像能力的提升提供什么样的帮助。
那聊影像,肯定离不开图片。
所以首先,先看看OriginOS 4 大模型(预览版)的拿手戏——文生图怎么样。
比如,我让它画一个“男性戴眼镜背头,然后穿着黑色西服。”

小V助手迅速就完成了图片生成。
如果希望得到指向性更强的图片,则需要将细节尽可能多地发送给它。

比如在这幅图中,我要它生成一个“男性,有络腮胡,背头,戴墨镜,年龄38岁,穿运动休闲服的半身像。”
可以看到,基本我所有的要求,大模型都完成了,好像只有“半身像”有点没能符合。
那么,这时,可以再重新生成,看看是否可以得以改进。

就像这张图片,我提的需求中“工作装、办公室、全身像”好像都没能满足,于是,我要求它重新生成。
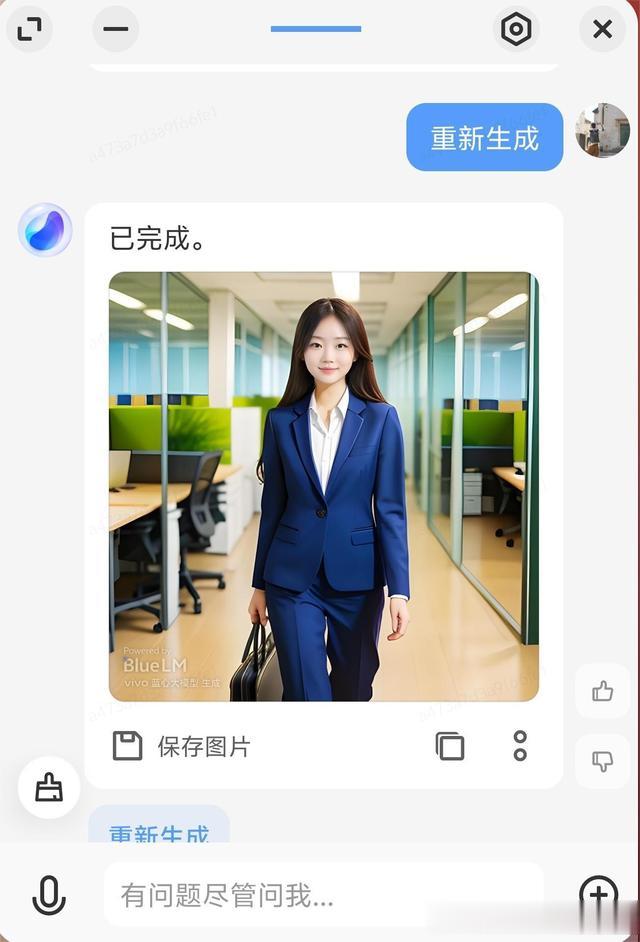
再来看,是不是完美符合了?
这个文生图功能能带给我们什么样的好处?
首先第一点,肯定是可以规避版权问题。尤其是人像的图片,在我们的日常使用中,对于像我这种会大量使用图片的自媒体博主,会规避掉很多风险。
第二,就是可以更好地、更准确地生成自己所需要的配图,比如风景图。


大模型通常会默认生成1比1的方形图片。如果有比例需求,只要把尺寸需求写上,它就会按照你的要求来输出。

当然,对于更多的人来说,这种文生图的趣味点,可能是可以帮你生成个性的头像,或者是朋友圈配图。

如果你喜欢吃汉堡,而且还喜欢哈利波特。那么,就可以将这两个元素融合在一起。
当然,喜欢吃披萨的朋友,同样可以生成自己的另类头像。

生成了配图之后,大模型还可以帮助你给图片进行相应的朋友圈文案撰写。
比如刚才那张秋日图,大模型先给配出了两句话的文案。

我觉得略微有点简单,于是让它“润色一下”,语句于是就丰满了一些。
如果觉得有点简短,那么,可以进一步地要求大模型再对话语进行“扩充”。一段小作文立刻跃然纸上。

除了文生图,大模型对于图片的处理也有一些很有趣的玩法。
比如,转变风格。
大模型可以根据你的指令将照片变成漫画、二次元、国画、印象派等不同风格。这个功能,很像很多APP的后期滤镜。但是从使用的体验感来看,大模型生成的风格,还是比APP的滤镜,要优秀很多。

比如,这张照片我使用醒图APP,在“玩法”中选择各种漫画滤镜套用,可以看到处理出来的效果很生硬,几乎都是直接换头。


而利用大模型,通过风格处理的照片则舒服很多。






当然,我觉得更有用的,是利用大模型来对照片进行后期处理。
照片后期,是一系列相当复杂的操作的结合。对于很多人来说,某一项后期处理的操作也许不难,但难的是不知道该如何入手。
所以,如果大数据可以给照片以建议,对于很多摄影初学者来说,肯定是非常受用的。
目前,OriginOS 4预览版的大模型在这方面已经体现出了一些端倪。

比如,当我导入这张照片的时候,可以看到大模型给出的处理方案中,就包含了消除路人。

点击处理,画面右侧人斑马线上的路人,就被消除掉了。且背景处理得非常完美,丝毫看不出瑕疵。

不过,除了消除路人之外,我试验的其它几张照片,还没有发现另外的后期处理建议。
比如,当我希望给照片更换天空。

大模型给出的解决方案,是用文字详细地告诉我该如何一步一步操作。而不是直接处理。
我之前专门出过一期视频,介绍vivo自带的后期软件,在某些方面甚至比snapseed的功能还要全面且智能。
而上述的识别、消除路人功能,我也曾着重讲过。所以,猜想这个大模型的处理应该是和vivo自带修图软件打通的。
那么,基于目前的OriginOS 4的大模型只是一个预览版,功能还在打磨当中,而vivo的发力点一直着重放在影像功能上。那么不难畅想,日后,随着学习和升级,大模型如果可以进一步连接手机自带的修图软件,在识别图片之后,就给予后期建议以及自动生成,那么,照片后期对于普通人来说将不再是一件难事。
另外,就是借助大模型,也可以实现一些更为复杂的后期处理,且不需要上手实操——只需要文字输入就可以。
就像PS之前推出的AI功能:智能扩图,以及复杂抠图填补,都是傻瓜式无脑的一键操作。

第三,在摄影的学习上,我发现OriginOS 4大模型(预览版)也可以借助某些功能,帮助我们提高效率。
比如,一些基础的摄影知识,直接向大模型提问,就可以得到详尽的解答。

一些比较复杂,系统性的知识,可以让大模型直接生成思维导图。


我试着提问如何提高摄影技巧,大模型便给出了一份相对详尽的思维导图。如果满意,还可以继续优化,让大模型继续细化思维导图。就可以得到内容更为充实的结果。


另外,利用大模型的提炼重点功能,还可以帮助我们更加高效地筛选出对自己有用的内容。
我试着将我之前写的一篇《天下摄影 维高不破》的文章链接发给它,然后让大模型进行提炼总结。结果发现,总结出来的要点,将我主要想分享的思路明白无误地罗列出来。

那么,利用这些功能,势必就可以帮助我们更快、更高效地学习摄影。
对了,还有一个很小的功能,我觉得,也很棒。
对于一个爱摄影的人来说,在浩瀚的手机相册里寻找到一张精确的照片,是很费时间的。
而用大模型来寻找就会变得简单许多。
比如,我想寻找这张照片。

那么,我给照片的定义是“航拍、草坪、白衣”,于是,我把这些文字输入给小V助手。
这张照片便被精准地筛选出来。

事实上,从以上的很多功能来看,OriginOS 4 大模型和其它普通 GPT 应用并无二致,主要集中在创意类文案写作、信息整理、问答聊天、文章摘要等。
但是,通过我的分享,你也不难看出,与它们不同的是,OriginOS 4 大模型的连接载体是我们的手机。这就使得它不止是一个信息的提供者,更能将信息与手机进行互联互通。
我们的很多需求在大模型那里,不再只是在数据库里寻找答案,而是借助手机自身,甚至是APP应用,来提供一系列的整理、集合、解决方案。
如今,手机已经和我们的生活日渐紧密关联,衣食住行都离不开手机的辅助。而大模型的加入,无疑让手机真正成为我们的“智能私人助理”。所以,当硬件的军备竞赛进入到一个白热化的阶段之后,大模型或许就会成为另一条赛道——甚至是一个可以弯道超车的快行道。
