引子
英特尔发布酷睿Ultra 200S桌面端处理器的节奏非常清晰,9月初德国IFA期间随LunarLake的正式发布时初次披露架构;10月10日详细解读技术架构,重新落实了P核与E核集群的分布等问题,当然,所有的期待最终等会等到10月24日的发布日。这一天,我们也会随英特尔的发布节奏正式公布我们过去数十天的评测过程与结果。
评测解秘之前,我们会首先归纳大家在10日之后向我们提出的一些问题,我们也会在评测中一一为大家回答:新处理器是x86架构向Arm架构的反击而设计的吗?为何14代酷睿不与移动端同步使用分离式模块架构,要留待酷睿Ultra 200S上才实现?性能到底有多少提升?能耗是否像宣传那样节省了一半?为何台式机处理器仅提供36TOPS的AI算力?游戏与超频表现如何?

甚至还有读者问到:英特尔未来会走什么样的路?能不能重回制程巅峰……我们很难在一篇评测文章中兼顾到所有人的好奇心,我们挑选的这部分问题都是与酷睿Ultra 200S桌面端处理器紧密相关,而且或多或少能借这颗小小的处理器给出答案的。
架构演进——先进制程与封装带来出色能效比

在发布了Arrow Lake的桌面端酷睿Ultra 200S之后,同架构的H系列标压移动端和HX高性能移动端将会留到明年的CES上再为大家披露,所以,这次是2024年PC上最后发布的一颗处理器。目前,我们收到并评测的是5款首发型号中的两款:酷睿Ultra 9 285K和酷睿Ultra 5 245K。

评测开始前,首先回答大家第一个问题,为何英特尔在桌面端才刚刚使用移动端上一代的分离式模块架构,原因其实在于当时移动端的能效取向、总线构架和硬件调度不适配桌面端处理器的性能需求,英特尔也是通过长时间的硬件调优与技术取舍,才得出了最佳的结果。正如我们10日公布的技术架构资料一样,这一代台式机处理器的取向是高能效方向的,多线程性能也有不错的提升,游戏支持上,能够提供低功耗稳帧能力,有助于主板、电源与机箱设计厂商带来更富想象力的台式游戏主机产品。

回答大家的第二个问题是:全新平台为何会取消了使用了22年之久的超线程?可以看到,所有的SKU中的P核都取消了该功能,以酷睿Ultra 9 285K为例,总共8P+16E,共24线程,而前代旗舰i9-14900K在相同核心数下则提供了32线程。但是,不管从英特尔公布的参数,还是我们测试的结果,取消超线程的酷睿Ultra 9 285K,多线程能力反而有明显的提升,这说明这一代的Lion Cove(P核)和Skymont(E核)核心本身就有相当出色的代际提升。而且一个物理核心支撑两个逻辑线程,本身在线程调度上就要消耗核心性能,在线程数满足日常需要求的今天,完全可以去掉超线程去换取更好的P核性能。

酷睿Ultra 200S与以往台式机处理器最大的不同,就是采用分离式模块架构,可以看到处理器分出了CPU、GPU、SOC和I/O四大模块,并全面采用台积电的工艺,最后在英特尔工厂中通过Foveros技术进行3D封装。以往,英特尔在制程追赶之时总想通过先进的封装工艺来弥补制程,而在这一代处理器在同时拥有更先进制程与更先进封装工艺后,展示的性能与能效是相当值得期待的。放眼半导体市场,几乎所有先进制程的芯片均已经全面实现模块化(Chiplet),英特尔未来也装利用该技术,在自有产线与代工产线间随心切换每个模块的制程工艺。

可以看到,CPU模块的DIE面积是相当大的,除总线接口外,其余部分则完全被计算核心与缓存占领。从核心以及缓存分布上可以看出两个最大的特点:
1、 核心集群分布均衡:英特尔摒弃此前大小核“分居”两地的窘况,其最大的优势之一便是大小核之间的核间延迟进一步缩短,这在核心转换涉及到的上下文切换时非常受用,我们熟知的反面案例则是采用核心CCD分离的Zen架构,其跨Die延迟不可谓不高。其次,在我们实际测试看来,P/E核心均衡放置对于积热问题有着非常大的优化,能够更容易的均分热量,这对超频或者极限装机玩家而言是一个不可忽视的优势。
2、 缓存全核共享:对于高性能计算而言,数据线路损耗或者干扰将直接影响性能和稳定性,借此英特尔提供了不错的解法,借核心均摊的契机,三级缓存也得以“均摊”,从架构图可以看到,每核心最快访问临近缓存的路径长短一致,也就带来更为均衡的线路延迟和损耗。

核心当中,各项解码、预测、指令等前后端单元也都做了对应升级换代,由此P核获得9%的代际IPC提升,而新E核在重构后,IPC提升来到了恐怖的32%,而这也是这代处理器在取消超线程后多线程性能逆势反超的关键先生。

值得一讲的是,酷睿Ultra 200S这次拥有独立的外部电源,使得核心电压调整能够精细到每一个P核以及E核簇,除电压外,基础频率也从100MHz精细到16.67MHz,这将带来极强的核心控制颗粒度,有助于极限超频玩家挖掘Arrow Lake的极限潜能。

GPU模块也是Arrow Lake带来的全新变化,当然,说是全新则是因为此前的桌面端往往忽略核显的作用,尽管Xe-LPG在Lunar Lake上我们已经见识过其强大,但搬上了桌面端,也算是一种全新的体验,当然,英特尔这次提供的Xe-LPG核显功能完整,不仅支持光线追踪,XeSS等满配功能也并没有阉割,不过在桌面端,我们认为实际更有作用的则是媒体引擎。值得留意的是,Xe媒体引擎并不是在GPU模块中,而是在SOC模块中,但调用需要Xe核显的介入。
平台升级——新特性新体验
大致架构部分我们简单介绍完,我们直接进入测试平台介绍,这次的测试不同以往,由于Arrow Lake大刀阔斧的改革了接口、芯片组,甚至支持了最新的CUDIMM内存,所以新主板、新内存我们也得简单扫扫盲。

众所周知,Arrow Lake从14代酷睿的LGA1700更新为LGA1851,那么新的为Arrow Lake配套的800系列芯片组也是一并来了,在扩展性上,除CPU直连的20条PCIe5.0通道外,芯片组还将提供24条PCIe4.0通道,最多十条10Gbps USB 3.2接口,以及14条USB2和8条SATA3。

关注英特尔的读者们都知道,酷睿Ultra桌面端处理器(第二代)同步更新了全新的LGA1851接口,首次搭载此接口的全新Z890系列主板也会随新处理器一并上市。跟随处理器,我们收到了七彩虹最新的七彩虹iGame Z890 FLOW V20主板,新的芯片组和主板设计会迎来什么重大更新,作为纯国产老牌板卡厂商,首发的Z890主板又会带给我们怎样的惊喜?

这块七彩虹iGame Z890 FLOW V20在七彩虹主板体系中隶属于顶级的iGame系列,不同于Colorfire主打年轻化的大胆配色贴花,也不同于CVN战舰系列的浓烈机甲风,iGame在外观上显得更加“精致”,也出过颜值极为逆天的角色,比如这块七彩虹iGame Z890 FLOW V20就采用独一份的波普风线条散热装甲,对于颜值党而言可称得上是“尤物”。

既然是旗舰系列,核心配置方面自然也当得起旗舰定位,装甲之下展示出的硬件水准并不低,拉满了Z890芯片组所能提供的所有接口:板载提供5个M.2插槽,除一个CPU直连PCIe 5.0 M.2外,其余四个通过芯片组连接,且统一都支持PCIe 4.0×4,无通道复用。余下PCIe通道则是物尽其用给到一个PCIe 4.0×16(x4规格)以及PCIe 4.0×1,内存方面则提供了金属加强,能够支持内存OC至8800MT。

最为核心的供电部分,七彩虹iGame Z890 FLOW V20则是毫不吝啬的给到了20+1+1+1 90A Dr.Mos供电,仔细看来,七彩虹iGame Z890 FLOW V20采用的是来自瑞萨半导体的ISL99390,而这也是旗舰主板的常用配置。

Dr.Mos配套的PWM控制器则同样是来自瑞萨半导体的RAA229130。

后置IO部分,由于得到了Arrow Lake的扩展性加持,七彩虹iGame Z890 FLOW V20也能顺理成章给到更为充沛的接口规格,4×USB2、DP、HDMI、4×USB3.2 Gen2、2×雷电4(原生)、2.5G有线网口、WiFi 7等旗舰配置都给到了,并且还同样拥有清除CMOS以及无U更新BIOS的按钮,可以说在硬件配置上,七彩虹iGame Z890 FLOW V20完全符合你对旗舰主板的想象。

显卡部分,因为主要测试处理器性能,那么更能体现出处理器差距的高端显卡也就成为必须,这里我们选择了同是七彩虹iGame旗下的iGame GeForce RTX 4080 SUPER Neptune OC 16GB,当然,将称呼换做玩家们更熟悉的“RTX4080 Super水神”,是不是如雷贯耳许多?

这块显卡作为七彩虹旗舰,全金属装甲覆盖分量十足,“亚特兰蒂斯科技”风格与七彩虹Logo相得益彰,当之无愧为显卡中的一线旗舰,用料上则采用整块铜切削,并覆盖显卡所有发热件,在供电位置还额外添加热管用于热量均衡,双滚珠轴承风扇则起到静音和延长寿命的作用,实际体验效果极为冷酷!

内存部分,由于酷睿Ultra 200S以及七彩虹iGame Z890 FLOW V20对内存超频的加持,我们也是分别找来四根16GB的Kingston FURY叛逆者DDR5 7200 RGB内存,用以插满4DIMM接口,来测试在内存插满情况下究竟能将内存超频到何种程度,而且插满四根也能唤醒这款RGB灯条的隐藏灯效,极为炫酷。Kingston FURY叛逆者DDR5 7200 RGB内存是我们测试平台上的常客,经典的外观下也有着旗舰级别的性能及用料,极为适合超频的海力士颗粒也是追求性能的不二之选。
基准测试——性能稳步前进,超频更加稳健


相信大家对酷睿Ultra 200S之前公布的性能参数已经很熟悉,P核和E核的IPC代际提升分别为9%和32%,从而使降频(P核从前代的6GHz降到了5.7GHz)、减线程的新一代处理器实现了逆势反超。

1. CPU测试
在Cinebench系列测试中,无论单多核其实都表现出近似的增长幅度,代际单多核提升达到单核平均3.64%,而多核则有着6.24%。

单核提升其实与取消超线程技术有很大关系:该技术本质上并不高深,可以简单的理解为两个线程共用一个物理核心,但绝对达不到1+1=2的效果,在某一线程进行忙碌计算时,另一线程的任务会被短暂挂起,再配合复杂的大小核、多核调度,上下文切换早就宛如一锅乱粥,所以,取消超线程看似会减少多核性能,但实际上它却能让每一个线程更顺畅的工作,再辅以前端解码、乱序执行、调度等核心架构的演进,从而让单多核都能实现逆势反超。
所以英特尔借Arrow Lake取消超线程,自然是对目前愈发复杂的计算调度环境做出的顺应时代的改变,对于我们玩家而言,能安全、有效提升性能的办法,都是好办法。

在Geekbench6.0.3版本的测试中,对比非常有意思。其中酷睿Ultra 9 285K对比i9-14900K单核成绩基本只在误差范围,多核优势也不算太明显;但酷睿Ultra 5 245K对比i5-14600K反而异军突起:单核胜过前代32.55%,多核则更是领先44.45%,这让我们不得不猜测是否是因为取消超线程+E核提频+IPC暴涨带来的调度Buff,实际上在Geekbench工况中,测试内容极为复杂,所以减少上下文切换带来的损失便能带来不俗的性能提升。

CPU渲染能力在部分工业设计领域中依旧很常用,V-Ray渲染器CPU基准测试中,两颗酷睿Ultra 200S处理器都表现出不错的代际性能提升,其中酷睿Ultra 5 245K提升更是达到44.7%。
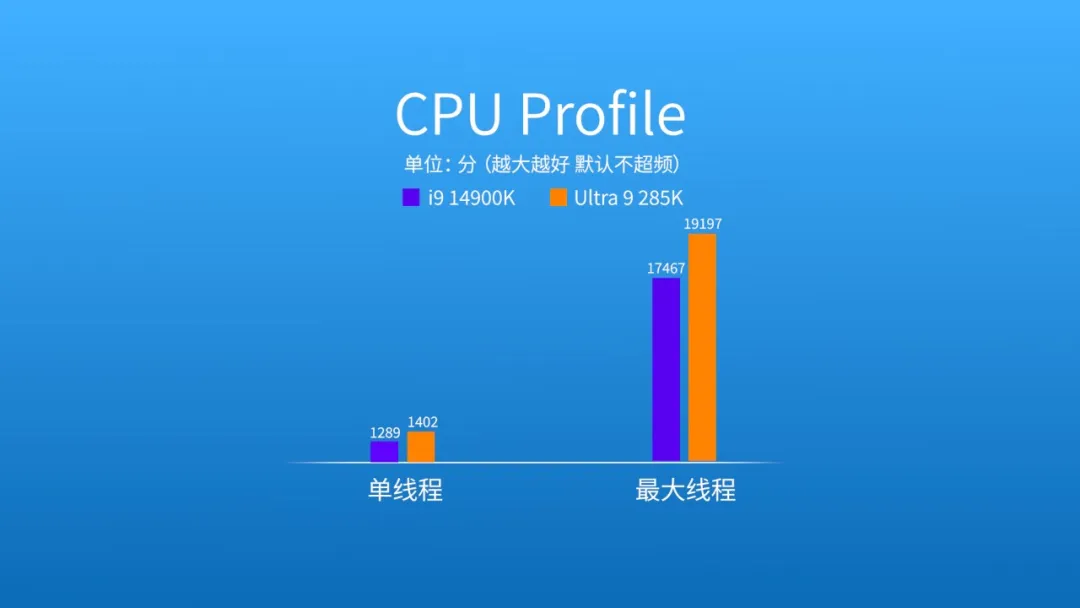
在主要测试CPU线程能力的处理器基准3DMark CPU Profile测试中,酷睿Ultra 9 285K单线程、最大线程分别领先8.7%和17%。

国际像棋虽然是一个古早的线程测试工具,仅支持16线程(平均核)的测试方式。可以看到,代际的线程提升依旧非常明显。

7-Zip压缩解压缩测试作为普通玩家最容易接触的到的应用场景,主要对处理器以及内存做出考察,实际上在换用相同内存测试后,内存造成的影响可以忽略不计,在这项测试里,两颗Arrow Lake处理器展现出轻微领先的结果,当然,实际进行测试时7-Zip并不能吃满所有核心,所以如此提升幅度倒也情理之中。

WebXPRT4测试则与其他测试大不一样,由于需要借助浏览器进行测试,所以极为依赖浏览器对于资源的调度利用,而众所周知,浏览器作为复杂程度仅次于操作系统的存在,对于单核性能极为依赖,我们使用最新24H2版本Windows11系统的最新Edge浏览器进行测试,其中整体成绩酷睿Ultra 9 285K领先上代7.81%,酷睿Ultra 5 245K则领先6.87%,一定程度上倒是符合P核代际IPC提升。
2. 整机测试
CPU代际提升与整机成绩密不可分,也能看出CPU性能成长在整机增益中占据的比重。在PCMark10中,无论是酷睿Ultra 9 285K还是酷睿Ultra 5 245K,对比上一代而言分数相差并不大,其中酷睿Ultra 9 285K对比上一代领先0.06%可算作误差范围,酷睿Ultra 5 245K则要比上一代领先6%,并且四款处理器实际上在模拟日常办公使用的测试中并不会有多大差距。

在压力更大耗时更久的PCMark 10 Extended测试中,无论是酷睿Ultra 5 245K还是酷睿Ultra 9 285K,都分别领先上一代12.68%以及13.13%,查看子项分数发现是编解码性能评分暴涨,这自然得益于Arrow Lake全系更新的Xe-LPG核显,作为Meteor Lake同款核显,其强大的编解码性能和图形性能有目共睹。
3. 处理器超频

在超频上,我们可以看到给到酷睿Ultra 9 285K的VID电压给得非常保守,与13、14代动辄1.4+V相比,运行Cinebench这样重负载场景下的电压仅有1.22V,显示相当稳健。

相应的,单核主频也给得比较保守。由于新一代处理器与新版XTU支持双BCLK调优,可逐个核心调节电压、频率等参数,而且将频率步进从100MHz降至16.67MHz,超频调节更细。简单测试了一下超频,我们可以将两颗P核超到5.816GHz,而E核则可全核超至4.8GHz以上。

超频后,Cinebench R23多核的性能提升也顺势涨了一千分,单核分数也有相应提高。
4. 内存超频

当然,既然英特尔提出内存超频的优化,我们自然也是测试了一番,测试使用的Kingston FURY Renegade DDR5 RGB 7200 C38采用目前超频潜力极强的海力士A Die颗粒,不妨看看在Arrow Lake新平台上表现如何:

我们使用200MT/s为步进的方式逐渐摸进这套平台的极限,毕竟对于新平台而言,其对内存超频的支持程度需要一套标准的流程来探索,一步一个脚印,同时,我们也尝试在每一级频率下探索最优时序。
可以看到,使用酷睿Ultra 9 285K搭配Z890吹雪,我们将这套7200MT/s的内存一路超到8600MT/s!其性能提升幅度也是来到了10GB/s,而如此高频且稳定的结果,自然离不开Arrow Lake以及主板内存的支持。

而在不断超频刷新成绩的同时,延迟也是逐渐压下来,近乎10ns的延迟下降对于不少网游而言至关重要。
iGPU升级——创作利器强势领先
当然,超频只是玩家们获取快乐的方式之一,打铁仍需自身硬,CPU部分我们简单评测完,其表现称得上合格的代际更新。但别忘了,Arrow Lake除CPU架构大改之外,也对其余硬件做出了不少的改变,其中最让我们惊喜的就是这颗搭载在Arrow Lake上的Xe-LPG核显了。

作为Meteor Lake上已经见过面的常客,强悍的图形和编解码性能确实称得上目前核显第一人,但众所周知,桌面端往往对核显并不重视,所以Arrow Lake上的这颗Xe-LPG反而更值得让人关注。

核显测游戏性能并不算一个贴合实际的好方法,但Xe-LPG优秀的编解码性能倒是能为生产力添色不少。在实际测试中,使用Handbrake转码一部H.264编码的4K AVI格式200Mbps码率电影,转为流媒体中常用的VP9格式仅需26秒,而转为AV1更是仅需13秒,相比之下上一代14900K基本需要多一倍的时间才能完成,可见这一代核显性能提升之强悍。

而在生产力中更为常用的H.264、H.265编解码测试X.264以及X.265中,酷睿Ultra 9 285K也展示出了59.66%的H.265编解码性能提升。实际上对于桌面端而言,大幅提升的核显性能可并不是用来玩游戏的,强悍的编解码性能对于视频工作者而言极为有用。
能效——自古好戏多压轴

但自古好戏多是压轴登场,如果说CPU性能以及核显性能还不足以吊起你挑剔的胃口,那么这一代Arrow Lake引以为傲的能效完全足够刷新你对桌面处理器的认知。
英特尔举了一个非常不错的例子,在相同帧数下,酷睿Ultra 9 285K要比上一代功耗低了80W。

如果你对这看似无所谓的80W没有一个准确的认知,不妨看看能效曲线,我们使用酷睿Ultra 9 285K和i9-14900K在不同功耗点分别测试了对应的Cinebench R23多核性能,能够非常直观看出多少功耗下对应的性能。
我们以100W这一常用功耗点划线进行对比,而实现i9-14900K 100W的性能,酷睿Ultra 9 285K仅需50W即可,也就是说酷睿Ultra 9 285K用一半的功耗即可实现相同性能,其能效表现极为恐怖。
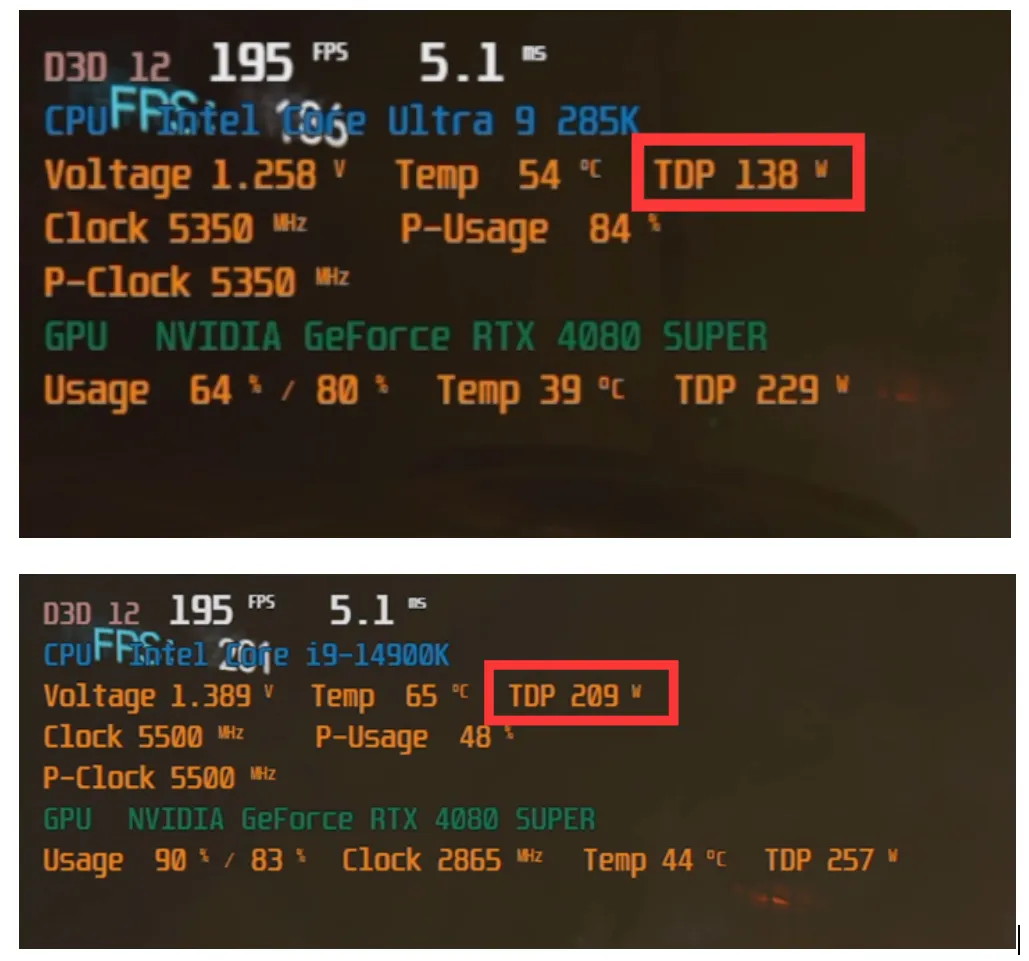
当然,在实际游戏中我们也着重观察了其游戏表现,测试均在1080P分辨率最高画质预设下进行,在《赛博朋克2077》同一场景中,酷睿Ultra 9 285K仅需138W左右即可实现i9-14900K相同的帧数,而此时i9-14900K需要209W,可见确如英特尔所说,在相同帧数下带来更优秀的能效表现。

当然,3A大作对于处理器的压力并不及网游,而在网游中,则在体现能效优势同时还能展示出Arrow Lake更优秀的缓存和单核优势,《CS2》中可以明显观察到,同一帧下酷睿Ultra 9 285K以78W的功耗达到了364FPS的瞬时帧率,而i9-14900K则为137W实现309FPS,功耗降低的同时带来性能提升,这就是能效比的生动诠释。

当然,如果善于观察,你会发现功耗下降的同时带来的则是更“冷酷”的温度表现,两者15℃的温差,足见能效的提升并非只是功耗的一枝独秀。
游戏高效能——为游戏主机带来更多想象
当然,论绝对的游戏性能,我们也测试了不少游戏供大家参考,游戏覆盖次世代3A以及常见网游,大家可以简单评判一下代际游戏性能提升究竟如何。



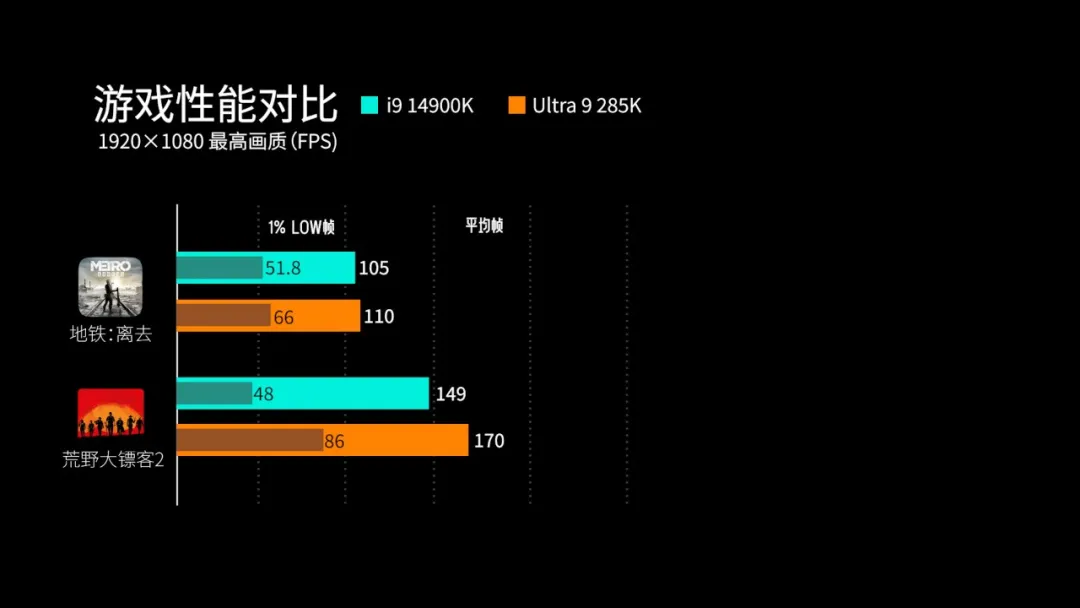

可以看到在绝大部分游戏中,酷睿Ultra 9 285K都能在平均帧以及1%Low帧中保持不小的领先。

当然,英特尔这次也为我们展示了高能效比的另一种玩法,就是在不同的功耗上限下,其游戏性能是持平的,而英特尔则是选取了125W、175W以及默认的250W PL1进行展示,我们自然也是验证了一下。

《CS2》中,由于前文展示过,满足其正常运行所需的功耗其实不足100W,所以即便是限定到125W,其平均帧以及1%Low帧也能与满功耗下保持一致。

《黑神话:悟空》中则更是如此,由于3A对处理器的压力并不及网游,瓶颈都在显卡上,所以三个上限值所展示出来的平均帧及1%Low帧都只在误差范围内。
AIPC体验——全方位硬核体验

自然,作为最新发布的PC硬件,哪能离得开AI?而英特尔这次选择为Arrow Lake配上一颗13TOPS算力的NPU,而CPU+iGPU+NPU共计36TOPS算力,显然在数值方面并不能与Lunar Lake相提并论,所以并不是英特尔没有能力给Arrow Lake配上更好的NPU,那么为何如此安排?甚至连算力都没能达到微软Copilot 40TOPS要求?

实际上NPU作为英特尔桌面平台的端侧AI敲门砖,更多的承担AI媒体、低功耗、低精度端侧模型等工作,论通用性,CPU无出其右,论高可用性以及高性能,核显甚至独显才是主角。实际上在Procyon AI测试中,这套AI硬件性能是能够完全展现出来的。

所以36TOPS的融合算力实际上已经跳出了半导体巨头们的“算力军备竞赛”,而英特尔这么做的原因上图中就可管中窥豹,那便是OpenVINO框架,作为英特尔自己主导的AI框架,对于英特尔自家硬件甚至同属X86阵营的AMD硬件都展示出了极强的亲和性,其目的便是剑指ARM,毕竟微软主导的DirectML目的便是让所有支持Windows的平台都能快速开发且适配Windows AI,X86能用,那么基于Windows on ARM的算力平台自然也能用。
事实上AIPC时代英特尔的野心并不只是制造合格优秀的PC硬件,而是想要牢牢掌握AIPC话语权,自然也就不需要为DirectML进行过多参与,所以英特尔自然也就不在乎微软的40TOPS算力需求。而基于OpenVINO框架,我们已经能有不少成熟且实用的AI工具,比如剪映很早就支持使用NPU进行智能抠图,且效率极高,体验极佳。
事实上不止剪映,在OpenVINO官网,不少项目已经成熟可用,距离普罗大众开箱即用只是临门一脚。
EF点评:
整体评测体验完,这一代处理器给我们最大的感受便是极强的能效比,在桌面处理器性能过剩且提升艰难的情况下,英特尔能够敢于跳脱出“性能军备竞赛”,大刀阔斧用“并不擅长”的能效亮剑ARM,并且实际体验完全称得上完美,或许从这一代开始,我们能够见到英特尔在半导体行业中的“华丽变身”,为X86而战。

