一、定义

大规模无监督预训练(Large-Scale Unsupervised Pre-training)指通过未标注的海量数据对深度学习模型进行初始训练,使其学习数据的内在结构、分布特征或潜在表示的过程。其核心目标是让模型在无监督条件下提取通用特征,为后续的微调(Fine-tuning)到具体任务(如分类、生成等)提供高质量的初始化参数。
二、核心术语解释
1. 无监督学习(Unsupervised Learning):机器学习的一种类型,输入数据无标签或标注,模型通过发现数据内在规律(如聚类、降维)进行学习。
2. 预训练(Pre-training):在无监督或弱监督条件下,利用大规模数据对模型进行初始训练,使其学习通用特征。
3. 自监督学习(Self-Supervised Learning):一种无监督学习的变体,通过设计自监督任务(Pretext Task),让模型从数据本身生成“伪标签”进行训练。
4. 自编码器(Autoencoder):一种无监督神经网络,由编码器(Encoder)和解码器(Decoder)组成,通过压缩输入数据到低维潜在空间,再重建原始数据。
5. 对比学习(Contrastive Learning):通过区分正样本(Positive Sample)与负样本(Negative Sample),学习判别性特征表示。
6. 生成对抗网络(GAN):由生成器(Generator)和判别器(Discriminator)组成的对抗框架,通过博弈使生成器生成逼真样本。
7. 掩码机制(Masking Mechanism):在输入数据中随机掩码(遮盖)部分元素(如文本中的单词或图像的像素),迫使模型通过上下文预测被遮盖部分。
8. 微调(Fine-tuning):在预训练基础上,使用标注数据对模型进行进一步训练,使其适应特定下游任务(如分类、目标检测)。
9. 自回归模型(Autoregressive Model):基于序列生成的模型,预测下一个元素的概率分布(如语言模型)。
10. 潜在变量模型(Latent Variable Model):通过引入潜在变量(不可观测变量)对数据分布进行建模,如变分自编码器(VAE)和生成对抗网络(GAN)。
三、背景与需求

1. 传统监督学习的局限性
数据标注成本高:监督学习依赖大量标注数据,但标注过程耗时且成本高昂(如医学影像、自然语言文本的标注)。数据稀缺性:某些领域(如小语种语音识别)缺乏足够的标注数据。模型泛化能力不足:仅依赖少量标注数据训练的模型,泛化能力有限。2. 无监督预训练的兴起
海量未标注数据:互联网、传感器等产生大量未标注数据(如网页文本、图像、音频)。深度学习的复兴:无监督预训练通过学习数据内在结构,使深度神经网络能够从无标注数据中提取通用特征,推动了深度学习的发展。关键作用:无监督预训练为后续的监督微调提供了高质量的初始化参数,显著提升了下游任务的性能。四、核心技术方法
1. 核心思想
目标:通过未标注数据学习数据的潜在结构或分布,获得通用的特征表示。方法:设计自监督任务(pretext task),迫使模型从数据中学习有用的信息。
例如:
自编码器:重建输入数据。
生成对抗网络(GAN):生成逼真的样本。
对比学习:区分相似与不相似的数据。
2. 核心技术方法详解
(1) 自编码器(Autoencoder)
 原理:通过压缩输入数据到低维潜在空间,再重建原始数据,学习数据的紧凑表示。结构:编码器:将输入映射到潜在空间(如 \( z = f(x) \))。解码器:将潜在空间映射回原始空间(如 \( \hat{x} = g(z) \))。损失函数:最小化重建误差(如均方误差或交叉熵)。
原理:通过压缩输入数据到低维潜在空间,再重建原始数据,学习数据的紧凑表示。结构:编码器:将输入映射到潜在空间(如 \( z = f(x) \))。解码器:将潜在空间映射回原始空间(如 \( \hat{x} = g(z) \))。损失函数:最小化重建误差(如均方误差或交叉熵)。\[ \mathcal{L} = \frac{1}{N} \sum_{i=1}^N ||x_i - \hat{x}_i||^2 \]
变种:去噪自编码器(Denoising Autoencoder):输入被随机掩码或噪声干扰,增强鲁棒性。变分自编码器(VAE):引入概率分布,强制潜在空间服从正态分布(通过KL散度约束)。实例:应用:图像压缩、特征提取。示例:在图像处理中,自编码器可学习图像的边缘和纹理特征。(2) 生成对抗网络(GAN)
 原理:通过生成器(Generator)和判别器(Discriminator)的博弈,生成与真实数据分布相似的样本。生成器:学习数据分布,生成假样本。判别器:区分真实样本与生成样本。目标函数: \[ \min_G \max_D \mathbb{E}{x \sim p{data}(x)}[\log D(x)] + \mathbb{E}_{z \sim p_z(z)}[\log(1 - D(G(z)))] \] 实例:
原理:通过生成器(Generator)和判别器(Discriminator)的博弈,生成与真实数据分布相似的样本。生成器:学习数据分布,生成假样本。判别器:区分真实样本与生成样本。目标函数: \[ \min_G \max_D \mathbb{E}{x \sim p{data}(x)}[\log D(x)] + \mathbb{E}_{z \sim p_z(z)}[\log(1 - D(G(z)))] \] 实例:应用:图像生成(如Deepfake)、数据增强。
示例:StyleGAN通过无监督训练生成逼真的人脸图像。
(3) 自回归模型(Autoregressive Model)
 原理:基于语言模型(Language Modeling),预测下一个词的概率分布。公式: \[ P(x_1, x_2, ..., x_T) = \prod_{t=1}^T P(x_t | x_{<t}) \]任务:最大化序列的似然概率。模型:GPT、Transformer等。 实例:
原理:基于语言模型(Language Modeling),预测下一个词的概率分布。公式: \[ P(x_1, x_2, ..., x_T) = \prod_{t=1}^T P(x_t | x_{<t}) \]任务:最大化序列的似然概率。模型:GPT、Transformer等。 实例:应用:文本生成、机器翻译。
示例:GPT-3通过预测下一个词,学习语言的长期依赖关系。
(4) 掩码语言模型(Masked Language Model, MLM)
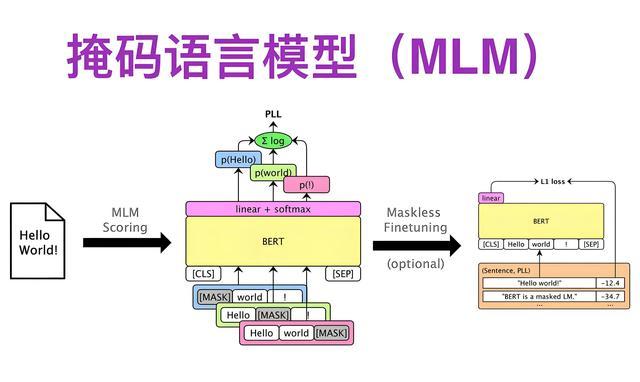 原理:随机掩码部分输入词,模型需预测被掩码的词(如BERT的MLM任务)。流程:输入序列中随机mask 15%的词。模型根据上下文预测被mask的词。优势:学习双向上下文信息。 实例:
原理:随机掩码部分输入词,模型需预测被掩码的词(如BERT的MLM任务)。流程:输入序列中随机mask 15%的词。模型根据上下文预测被mask的词。优势:学习双向上下文信息。 实例:应用:文本理解、命名实体识别。
示例:BERT通过MLM任务在未标注文本上预训练,显著提升下游任务(如问答)的性能。
(5) 对比学习(Contrastive Learning)
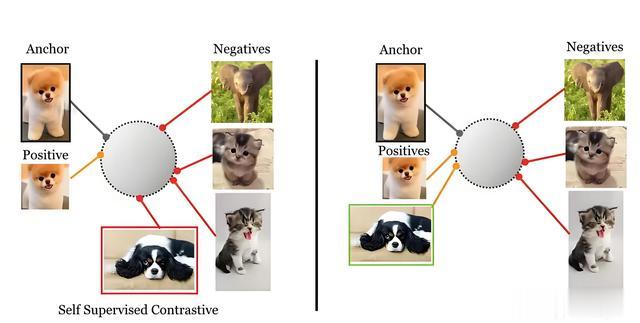 原理:通过区分相似(positive)与不相似(negative)的数据对,学习判别性特征方法:MoCo:通过动量编码器(momentum encoder)和队列(queue)存储历史特征,对比当前样本与队列中的样本SimCLR:通过数据增强(如旋转、裁剪)生成正样本对,最大化相似性。损失函数:InfoNCE损失。 \[ \mathcal{L} = -\log \frac{e^{s(z_i, z_j)/\tau}}{e^{s(z_i, z_j)/\tau} + \sum_{k \neq j} e^{s(z_i, z_k)/\tau}} \]实例:
原理:通过区分相似(positive)与不相似(negative)的数据对,学习判别性特征方法:MoCo:通过动量编码器(momentum encoder)和队列(queue)存储历史特征,对比当前样本与队列中的样本SimCLR:通过数据增强(如旋转、裁剪)生成正样本对,最大化相似性。损失函数:InfoNCE损失。 \[ \mathcal{L} = -\log \frac{e^{s(z_i, z_j)/\tau}}{e^{s(z_i, z_j)/\tau} + \sum_{k \neq j} e^{s(z_i, z_k)/\tau}} \]实例:应用:图像分类、视频检索。
示例:MoCo在ImageNet上预训练后,微调可在目标检测任务中超越有监督预训练。
五、训练流程与数学公式
1. 预训练阶段
步骤:数据准备:收集大规模未标注数据(如维基百科文本、ImageNet图像)。
预处理:分词、归一化、数据增强(如随机裁剪、旋转)。
模型初始化:随机初始化模型参数。
优化目标:通过自监督任务最小化损失函数。
迭代训练:使用梯度下降更新参数。
2. 微调阶段(Fine-tuning)
步骤:下游任务数据:加载标注数据(如分类标签、目标检测框)。
冻结/微调参数:冻结部分层或全部层进行微调。
任务适配:替换最后一层为任务特定的输出层(如分类头)。
监督训练:使用标注数据优化模型。
六、实例与应用
1. BERT(基于MLM的预训练)
结构:基于Transformer的编码器,12/24层。预训练任务:MLM:预测被mask的15%的词。
下一句预测(NSP):判断两句话是否连续。
应用:效果:在GLUE基准测试中超越人类水平。
示例:在问答任务中,BERT通过预训练的语义理解能力,直接定位答案位置。
2. GPT(基于自回归的语言模型)
结构:仅解码器的Transformer,最大支持万亿参数。预训练任务:语言建模(预测下一个词)。应用:效果:生成高质量文本(如新闻、代码)。
示例:GPT-3通过单次提示(prompt)即可完成翻译、摘要等任务。
3. MoCo(对比学习在视觉领域的应用)
结构:双编码器架构,包含动量更新的队列。预训练任务:最大化增强视图间的相似性。应用:效果:在目标检测任务中,MoCo预训练模型性能优于有监督预训练。
示例:在零样本迁移中,MoCo在不同领域(如人脸、驾驶场景)均表现良好。
七、优缺点分析
1. 优点
数据效率:利用未标注数据,降低标注成本。泛化能力:学习到的通用特征可迁移至多种下游任务。模型规模:适合训练超大规模模型(如GPT-3)。2. 缺点
计算资源需求高:预训练需要大量GPU资源和时间。评估困难:无监督任务的评估指标不直观(如重建误差、生成样本质量)。潜在平凡解:模型可能学习到简单模式(如恒等映射),需设计复杂任务避免。八、实际部署与挑战
1. 部署场景
自然语言处理(NLP):BERT、GPT用于文本生成、翻译。计算机视觉(CV):MoCo、SimCLR用于图像分类、目标检测。语音处理:XLSR-53(无监督语音模型)用于零资源语言的语音识别。2. 挑战
数据质量:未标注数据可能包含噪声或偏差。任务对齐:预训练任务需与下游任务语义相关(如目标检测需空间敏感特征)。计算成本:大规模模型训练需分布式系统(如阿里云的GPU集群)。九、未来方向
混合预训练:结合无监督与弱监督(如半监督学习)。跨模态学习:联合文本、图像、音频的无监督预训练(如CLIP)。高效模型:设计轻量级架构(如DistilBERT)以降低计算成本。十、总结
大规模无监督预训练通过未标注数据学习通用特征,解决了监督学习的标注瓶颈,成为现代AI的核心技术。其核心方法包括自编码器、GAN、自回归模型、MLM和对比学习,广泛应用于NLP、CV和语音等领域。尽管存在计算和评估挑战,但其在提升模型泛化能力和数据效率方面的优势不可替代,未来将向多模态、高效化方向发展。
