2024年12月26日,开源AI模型DeepSeek V3发布就引起了很大关注度。不仅是因为性能够好,更主要是因为它训练成本很低。随后发布的R1版本的推理性能又上了一个台阶,足以挑战OpenAI的o1,因此再次爆火。
DeepSeek V3,低成本高性能表现的国产开源大模型
DeepSeek V3是一个强大的混合专家(MoE)语言模型。它拥有6710亿参数,但在生成每个Token的时候只会激活370亿个参数。
名词解释1:混合专家语言模型
混合专家(Mixture of Experts, MoE)语言模型是一种特殊的模型设计,它的核心思想是“分工合作”。比如,让一个人从头到尾完成一项复杂工作,这个人很难擅长所有环节。于是,你决定组建一个团队,每个人都是某个领域的专家,每部分的任务交给特定的人,也就是让模型的一部分工作。比如,只让370亿个参数工作。
为了提高推理效率和训练成本的可控性,DeepSeek-V3采用了Multi-head Latent Attention (多头潜在注意力)和DeepSeekMoE架构,这些架构在DeepSeek-V2中得到了验证。
名词解释2:多头潜在注意力
多头潜在注意力(MLA)不仅可以更准确地找到重要的信息,而且还知道这些信息之间的关系。就像你和朋友们一起读一本书,每个人负责不同的部分,最后汇总所有人的发现。这样既能更快地完成任务,又能更全面地理解内容。在语言模型中,MLA 帮助模型更好地理解文本,比传统的MHA方法更省计算资源。
DeepSeek V3引入了无辅助损失负载均衡策略(auxiliary-loss-free strategy),旨在优化模型在不同任务间的负载分配,减少负载均衡可能带来的性能下降。同时,它设置了多token预测训练目标(MTP),增强了模型在处理多任务时的表现。
DeepSeek-V3在14.8万亿高质量、多样化的token上进行了预训练,随后通过监督微调和强化学习阶段进一步提升模型的能力。

经过全面评估,DeepSeek-V3超越了Llama 3.1 405B和通义千问 2.5 72B,并接近Anthropic的Claude 3.6 Sonnet和OpenAI的GPT-4o等闭源模型。这也是DeepSeek-V3发布后能快速获得关注的主要原因。
DeepSeek-V3不仅模型性能表现非常优异,而且训练过程非常高效,总共仅用了278.8万H800 GPU机时。最后成本仅为557万美元,远低于其他大型语言模型的训练成本。
事实上,DeepSeek设计了FP8混合精度训练框架,首次验证了FP8训练在极大规模模型上的可行性和有效性。
这点非常重要,如今FP32在大规模训练中的使用逐渐减少,仅在训练过程中关键的梯度计算部分使用,用的最多是FP16,更低的计算精度可以减少内存占用和计算量,从而加速训练过程,但用FP8这种精度的还是非常少的。
总之,DeepSeek通过算法、框架和硬件的共同设计,克服了跨节点MoE训练中的通信瓶颈,几乎实现了计算和通信的完全重叠,大大提高了训练效率并降低了训练成本。完成了一次漂亮的工程实践。
在278.8万H800 GPU机时当中,预训练占了266.4万。后续训练阶段用了10万GPU机时,后训练阶段主要是将DeepSeek-R1系列模型中的推理能力蒸馏到了DeepSeek-V3,显著提升了推理性能。
名词解释3:模型蒸馏
所谓蒸馏,就是将DeepSeek-R1模型作为老师模型,通过向老师模型发送一系列的提示词,得到输出数据。将提示词和回答的数据用来给作为学生模型的DeepSeek-V3做微调,就等于将DeepSeek-R1的知识传递给了DeepSeek-V3。
DeepSeek-R1,对标OpenAI o1模型的推理模型

2025年1月20日,6710亿参数的DeepSeek R1和DeepSeek-R1-Zero发布。
DeepSeek-R1是对标OpenAI o1的模型,它在数学、编程和其他推理任务上都取得了很好的成绩,其表现也超越了上个月发布的DeepSeek-V3。
DeepSeek-R1-Zero是一个通过大规模强化学习(RL)训练的推理模型,训练时没有使用传统的监督微调(SFT)。它在推理任务中展现了出色的表现,能够自发地发展出强大而有趣的推理行为。
名词解释4:强化学习
强化学习是一种让机器学习如何做出决策的方法。它通过奖励和惩罚的方式,让机器不断地学习,直到找到最优的行动策略。举个简单的例子,一只小狗学会按特定按钮,每次它按特定按钮的时候,主人都会给它好吃的。小狗通过不断的尝试和主人的奖励,学会了这个动作。这就是一个简单的强化学习的过程。
名词解释5:监督学习
监督学习(SFT) 就像你给小狗出题,然后告诉它答案。比如,你给它两根骨头,然后告诉它“两根骨头加一根骨头等于三根骨头”。你不断地给它出题并纠正它的错误,久而久之,小狗就会学会算术了。
概念区分:强化学习 vs 监督学习
强化学习:更像是在玩游戏,模型通过不断尝试和错误,根据得到的奖励来调整自己的行为。
监督学习(SFT):需要一个“老师”提供正确的答案,模型通过学习这些答案来改进。它更像是在学校里学习,有明确的教材和答案。
监督学习有明确的正确答案,而强化学习只有奖励或惩罚。监督学习的目标是让模型尽可能准确地预测或分类,而强化学习的目标是让模型在特定的环境中获得最大的累计奖励。
然而,DeepSeek-R1-Zero也遇到了一些问题,比如内容重复、可读性差、语言混合等。为了解决这些问题并提升推理性能,团队推出了改进版的DeepSeek-R1,在强化学习之前加入了冷启动数据。

这一改进使得DeepSeek-R1在推理表现上取得了显著提升,特别是在数学、编程和推理任务上,表现与OpenAI-o1模型相当。
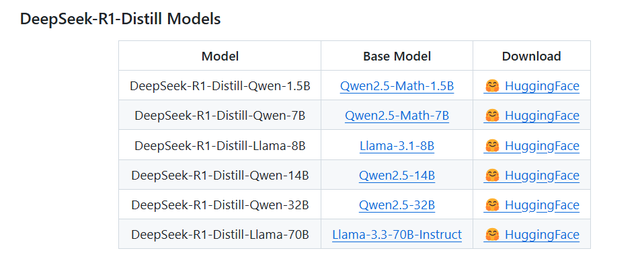
为了支持学术界的研究,开发团队将DeepSeek-R1-Zero、DeepSeek-R1以及从DeepSeek-R1中蒸馏出的六个精简模型也都开源了。其中,DeepSeek-R1-Distill-Qwen-32B在多个基准测试中超过了OpenAI-o1-mini。

DeepSeek-R1-Distill-Qwen-32B这个指的是,将DeepSeek-R1作为老师模型,它输出的知识交给作为学生模型的Qwen-32B,进行微调之后就得到了DeepSeek-R1-Distill-Qwen-32B。
换句话说,作为DeepSeek-R1学生的DeepSeek-R1-Distill-Qwen-32B,其表现都超过了OpenAI-o1-mini,你就说DeepSeek-R1强不强?更令很多大模型公司崩溃的是,它的模型不仅性能很好,而且训练成本很低。
写在最后
国内朋友的兴奋点在于,即使是没有手握最强的芯片算力资源,依然可以做出媲美最强模型的模型,这点值得欢欣鼓舞。

Meta的AI大佬杨立昆则认为,这不是中国AI超越了美国AI,而是开源的模式超越了封闭的模式。DeepSeek将V3和R1都开源给业界的做法显然也是支持这一看法的。
本文主要内容来自DeepSeek Github主页:
https://github.com/deepseek-ai/DeepSeek-V3?tab=readme-ov-file
https://github.com/deepseek-ai/DeepSeek-R1?tab=readme-ov-file
