Key Points
首次推出类o1的视觉理解模型,与Kimi旗下的K1模型对阵;
现在,即梦能控制图片中的文字生成;
李飞飞和Google之后,字节也有3D生成模型了;
豆包抢夺浏览器市场后,还要再抢占文档编辑器市场;
价格战继续:豆包最强模型价格只有GPT-4o的1/8。
作为大厂中最后两个推出大模型的公司之一,字节以短跑速度狂奔了一年。现在,它实现了在模型覆盖、产品矩阵和用户数量上的全面反超。
12月18日至19日,字节跳动在火山引擎Force冬季大会上公布了AI模型和应用层的多项更新。其中包括一款类o1模型的视觉理解模型和一个3D视频生成模型,前者使字节成为国内最早推出类o1模型的大公司,此前,国内仅有初创公司月之暗面(后简称Kimi)推出过类似模型;后者则使字节加入「世界模拟器」的参赛阵营。
对于大公司和初创公司,字节采取了不同的竞争策略。考察了各大公司的模型能力后,字节几乎将最看重的阿里大模型人才洗劫一空。而对于初创公司,第一财经「新皮层」获得的消息称,字节最为看重的对手是Kimi,从模型技术路线到产品功能,字节都紧逼Kimi。
视觉理解模型的推出只是两家公司的对战之一,此前,Kimi发起长文本、广告投流、推出AI搜索功能不久,豆包都迅速跟进了,并借助其资金实力反超。人才上,Kimi类o1模型的技术负责人刘征瀛在入职之前,字节跳动高层也曾争取其加入字节大模型团队。
语言模型能力赶上对手后,字节现在在视觉模型领域投出了更多炸弹。
12月18日的发布会上,字节剪映业务负责人张楠带队发布了即梦的一系列更新。即梦是字节在豆包之外另一款核心原生AI产品,主要功能是图片和视频生成。最新更新中,即梦开始能控制图片中的文字生成,成为国内首个能在图像中生成文字的大模型产品。

这是张楠在2月辞去抖音集团CEO、转任剪映负责人后的首次公开露面。今年2月,张楠发表内部信,称辞去抖音集团CEO一职,接下来要把精力聚焦剪映和CapCut(剪映海外版)业务。内部信中,她强调生成式AI对图像、视频领域的颠覆和机会。加入字节之前,张楠曾创办图片社区「图吧」,「图吧」被字节收购后,张楠加入字节,从0到1推出抖音、火山小视频等视频产品。即梦相当于是张楠的第3次创业。
12月18日的发布会中,张楠称,视觉模型将极大改变我们观看视频的方式——实际上,用户将不再是被动观看,而是可以在任何时刻介入、参与和影响剧情走向或者观看不同的故事分支。不仅如此,技术还可以使生物脑电波可视化,意味着我们可以探索潜意识的创作之路。「科学家估算过,人的一生可以容纳 10 亿个想法。」张楠说,如果抖音是记录「真实世界的相机」,即梦就是一款「想象力的相机」。
目前,字节还没有从其对大模型领域的大手笔投入赚钱。不过由于这些投入,字节在因生成式AI产生的云计算需求上获得了回报。国际数据公司IDC最新发布的报告显示,2024年上半年,火山引擎在GenAI IaaS市场位居第二,仅次于阿里云。12月19日有消息称,苹果公司正与腾讯、字节跳动、智谱等公司商谈,将其大模型整合到在中国销售的iPhone中。

以下是字节在这场发布会上值得关注的更新:
首次推出视觉理解模型,与Kimi旗下的K1模型对阵
据火山引擎总裁谭待介绍,豆包视觉理解模型不仅能精准识别视觉内容,还具备出色的理解和推理能力,可根据图像信息进行复杂的逻辑计算,完成分析图表、处理代码、解答学科问题等任务。
在豆包视觉理解模型推出之前两天,12月16日,月之暗面刚刚发布过同类视觉理解模型K1,月之暗面称该模型在后训练阶段采用强化学习技术,具有「推理」能力,不需要借助外部的OCR或额外的视觉模型才能理解图像。该技术路线与OpenAI推出的o1系列模型相似,豆包视觉理解模型也采用相似技术路线。
目前,该模型已接入豆包App和PC端,根据图像信息,可以分析体检报告、指正代码错误、通过动物的影子辨认出小猫、阅读微积分题目给出推理过程和解题思路,还能识别火山引擎总部位置,给出前往北京南站的出差方案。字节跳动称,在应用方面,该模型可落地图片问答、医疗健康、教育科研、电商购物、生活助手等场景。
现在,即梦能控制图片中的文字生成
即梦AI是2024年5月上线的视频创作平台,基于视频生成模型的能力,支持文生图、文生视频和图生视频。此次更新中,即梦最值得关注的更新是首次实现了相对准确的中文文字生成。在图片生成领域,文字向来是瓶颈,图像大模型一直被认为不懂文字。
这是中文领域首个能够以相对高的准确率在图像中生成文字的大模型。此前,能做到文字生成的公司仅有英国初创公司Recraft,而且仅限于英文。即梦产品经理李超在发布中称,中文生成比英文生成难度更高,因为英文仅有26个字母,中文常用字就有3000多个。

技术上,即梦的图片生成模型打通了语言模型的LLM架构和视觉模型的DiT架构。用户只需要在prompt输入时输入引号再键入文字,模型就能将引号中的文字在图像中生成。并且,即梦提供文字局部重绘功能,即如果文字生成有误,用户可以介入修正文字。
基于该能力,即梦推出「一句话生成海报」功能,用户输入一句话,即梦就可在几分钟内生成设计师水平的海报,海报既可以是平面的,也可以是动态的。
李飞飞和Google之后,字节也有3D生成模型了
发布会上,字节还推出了3D生成模型。据称,该模型与火山引擎数字孪生平台eOmniverse结合使用,可以高效完成智能训练、数据合成和数字资产制作,成为一套支持AIGC创作的「物理世界仿真模拟器」。12月初,李飞飞的空间智能公司和Google DeepMind先后发布了其最新3D生成模型,能够将2D图片直接转换为3D视频,并且,人类或者AI智能体可以控制这个3D世界中的角色。
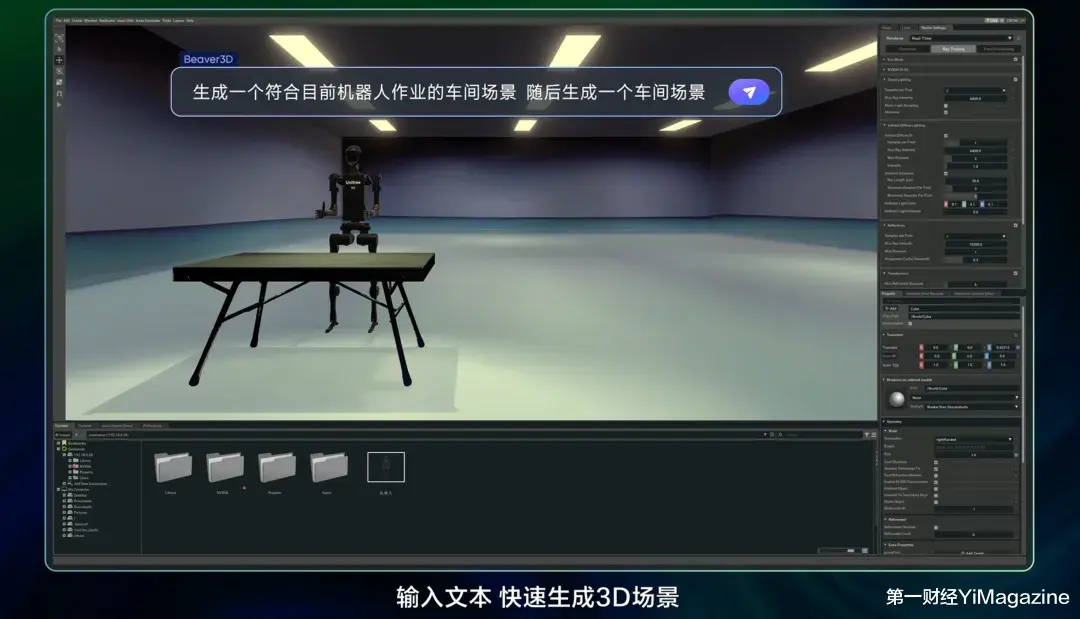
这类3D生成模型被认为是「世界模拟器」,能为具身智能体(embodied agent)提供安全且无限丰富的训练环境。英伟达科学家Jim Fan曾提出观点认为2024年是「基础世界模型」年。
此外,字节还在这场发布会中提升了豆包音乐模型的生成时长。最初,它只能生成60秒的简单音乐结构,现在可支持3分钟的完整音乐作品生成。豆包图像编辑模型SeedEdit的2.1版本支持用自然语言「一键P图」,包括换装、美化、涂抹、风格转化等指令。
豆包App抢夺浏览器市场后,还要再抢占文档编辑器市场
多项模型能力更新之外,字节还宣布了一项豆包App的重要更新,将上线「文档编辑器」功能。用户可以在豆包客户端获得一个文档编辑界面,生成文档后,用户可以在画布中自由编辑,还可以让AI针对特定词语和段落改写,或者一键全文润色、调整长度、全网搜图后直接插入文档。

这项更新相当于豆包想让用户把它也当一个Word使用。10月23日,腾讯曾推出类似的原生AI产品「ima.copilot」,除了像传统聊天机器人那样提供问答、AI搜索等功能,还提供文档功能。同样,该文档功能具有从起草大纲到翻译、智能续写、文生图等多项AI配套能力。
相较于搜索,文档可能是个更高频功能。而且,通过该功能,AI产品可以让用户在其产品内留下更多数据,从而对用户有更多了解。
价格战继续:豆包最强模型价格只有GPT-4o的1/8
基础模型方面,字节称,Doubao-pro已全面对齐GPT-4o。相比5月版本,豆包最强模型Doubao-pro能力大幅提升,面向MMLU_pro评测集,模型综合能力提升32%,和GPT-4o持平,但使用价格仅为GPT-4o的1/8。
今年5月,字节跳动发布豆包大模型的同时向B端价格挥起屠刀:豆包通用模型pro-32k版的推理输入价格仅为0.0008元/千tokens,比行业均价低99.3%,引发阿里、百度等多家厂商降价。本次冬季大会,字节在多模态大模型方面延续价格战策略:面向企业级市场,视觉理解模型的输入价格为0.003元/千tokens。字节称,一元钱就可处理284张720P的图片,比行业价格便宜85%。
