近日,热播剧《上甘岭》中男女主人公通过方言传递情报的情节,引发了网络热议。有网友表示赞叹,认为是“鬼斧神工”,让敌人无法破译。也有人吐槽,说发音“不够地道”,连本地人也没听出来。我国语言资源丰富,拥有十大汉语方言及难以计数的土语方言。中国电信万号智能客服每天接到上百万通电话,其中不小的比例都是用方言拨打。一些地区的老人更习惯说方言,甚至只会说方言。为了解决这个难题,中国电信于今年5月推出了具备超多方言识别能力的星辰语音大模型,构建了一座打通隔阂的AI之桥。
时隔不到半年,星辰语音大模型的多方言能力再次突破,不仅攻克了湛江话、宜宾话、洛阳话、烟台话等,将方言种类从30种提升至40种,并引入对英文的识别。同时,模型的参数量增加一倍,大幅提升了识别的准确率。星辰语音大模型打造了国内首个且独立通过算法和服务“双备案”的语音大模型,并在多个国际权威评比中斩获冠军佳绩。
“超多方言”大模型如何炼成?
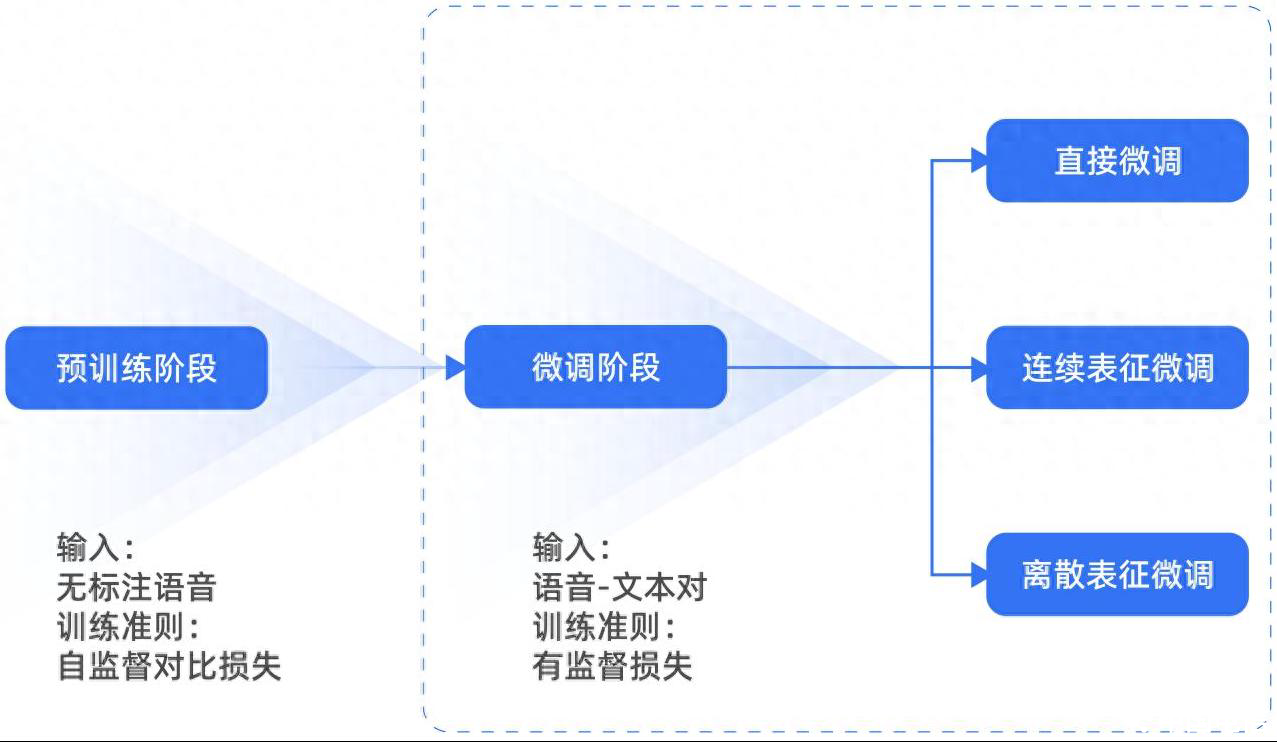
在多方言语音识别建模过程中,首先面临的问题是人工标注的方言数据非常稀缺,且成本高昂。为此,TeleAI团队采取了两条路径:一是获取更多无标注的方言数据;二是减少模型对标注数据的依赖。与传统的有标注训练方法相比,TeleAI通过预训练语音识别模型,利用海量无标注数据进行预训练,再通过少量有标注数据进行微调。由于方言语音数据普遍存在无标注数据多而有标注数据少的特点,这种“预训练+微调”的模型方案与方言场景的需求能够高度契合。
星辰语音大模型超多方言技术框架
同时,TeleAI还在模型结构和成本优化上进行了创新,实现对人工标注数据的需求量大幅缩减约50倍,且保障模型效果与有监督训练的方言模型水平相当。
第一阶段:模型预训练
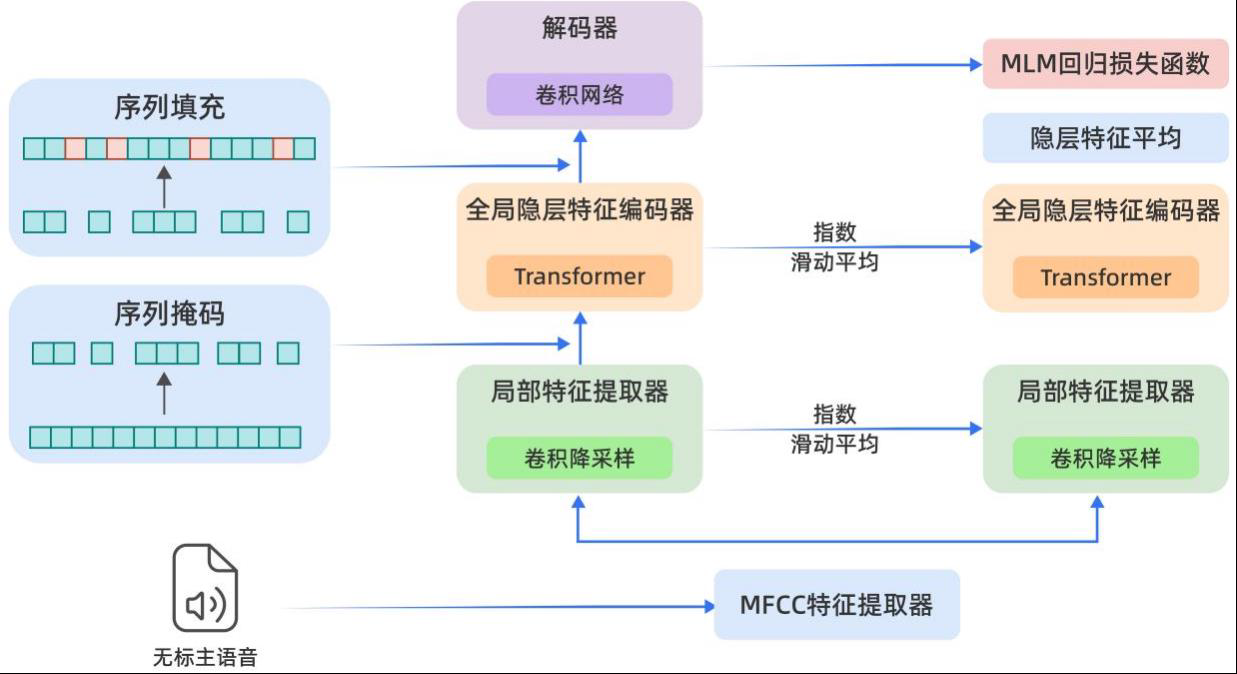
首先,在预训练模型的编码器设计上,团队采用了“老师”模型加“学生”模型的网络结构。
通过计算无标注语音的目标表征,并对输入的语音数据进行掩码,遮盖部分信息,然后使“学生”模型网络重复这一过程,预测“老师”模型生成的表征,从而最大程度利用无标注数据,学习多方言的发音规律。
第二,在优化代价方面,除了传统的对比损失和多样性损失外,TeleAI还为不同训练样本构建了包含其上下文的目标表征,并随机隐藏表征的不同部分。
然后将这些不同版本的表征输入给“学生”模型,让模型学习同一上下文下的不同掩码,从而有效分摊计算量,提升模型对掩码处理的鲁棒性。
预训练阶段模型结构
在此期间,TeleAI团队还在优化过程中剔除了训练样本中的空白部分,确保预训练模型能够更加充分地学习无标注数据的有效信息。
然而,随着参数量和数据量增大,模型的训练会越发不稳定。为解决海量多场景下大规模数据训练的不稳定性,TeleAI提出了创新的“蒸馏+膨胀”联合训练算法。
具体来说,将小参数量模型中的“老师”模型直接作为大参数量模型中的“老师”模型,进而让大参数模型中的“学生”模型蒸馏学习“老师”模型。
同时,考虑到即使使用蒸馏学习算法,大参数模型中的“学生”模型依然容易发生训练不充分问题,TeleAI引入“膨胀”算法,将小参数模型中的“学生”模型逐层复制权重,并插入新隐含层,构建出大参数模型中的“学生”模型。
基于此,TeleAI团队解决了超大规模数据和大规模参数预训练中的坍缩问题,成功实现了在50万小时数据规模和80层模型条件下的稳定训练。
第二阶段:模型微调
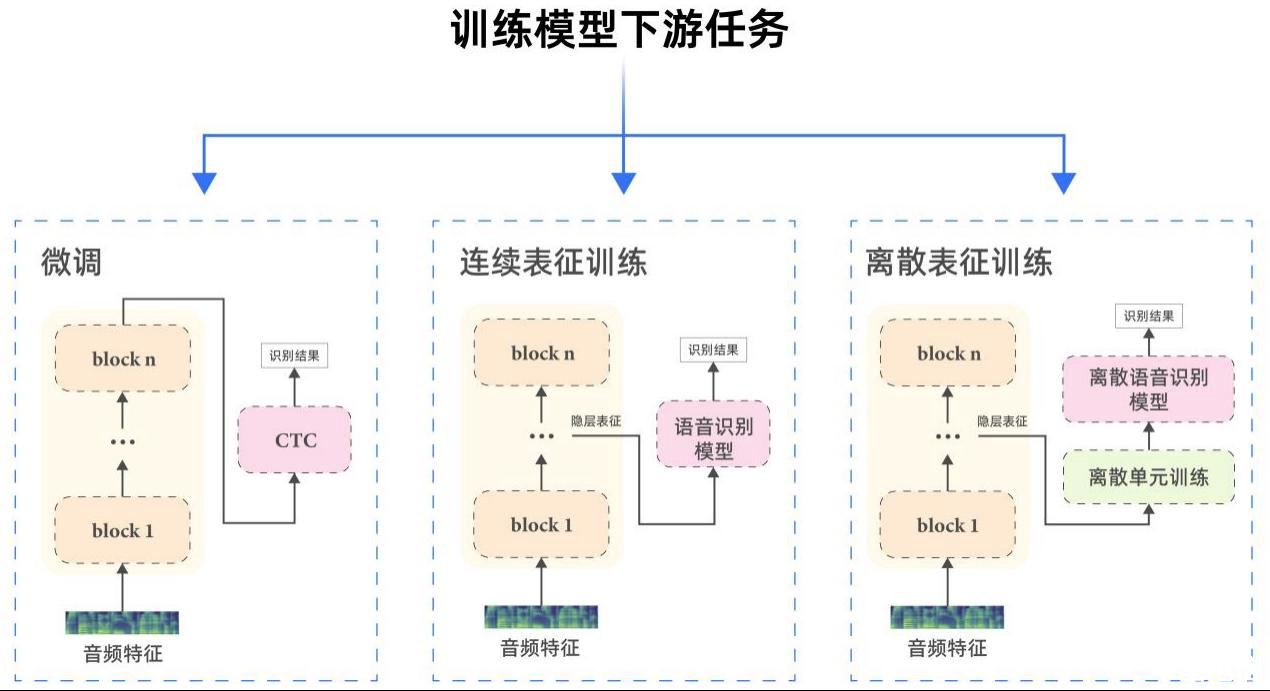
在完成模型预训练后,即进入微调阶段。TeleAI混合了多方言的有标注数据,对预训练模型进行微调。
在多方言联合建模的过程中,一些音频的识别文本看似与音频发音一致,但结果却严重错误,核心问题是发音混淆。
例如,粤语中的“八”(粤语拼音:baat3)与普通话中的“八”(汉语拼音:ba1)发音基本一致;但粤语中的“二”(粤语拼音:yi6)与普通话中的“二”(汉语拼音:er4)在发音上相差甚远,却与普通话中的“一”(汉语拼音:yi1)非常相近。
另外,某些方言在单独建模时表现良好,但一旦加入多方言联合建模,识别效果就会明显下降,背后是方言不均衡问题。
导致该问题的核心症结依然是相近方言的同字不同音问题。如果配比不合适,很可能会出现方言语音全部被识别成了近音字,但语义却完全不通。
为了解决这些问题,TeleAI团队采用“字+标签”作为新的建模单元。具体来说,单元中的“字”代表了音频中的发音信息和音频对应文本的语义信息。而“标签”则是用于区分同字不同音的附加属性,如方言标签或语言标签等。
有监督微调方案
这样既可以充分借鉴不同方言乃至语言间的发音规律,又能有效解决相似语言中的同字不同音问题。
在这个过程中,通过分析不同方言的发音规律、数据分布规律,并考虑使用人群规模等因素,最终得到量化不同方言所需训练数据的定量指标,即方言配比因子。
通过该因子,TeleAI团队动态调整不同方言间训练数据的配比以及上述拓展单元的覆盖度,从而找到了解决方言均衡问题的定量方法。
星辰语音大模型“超多方言”有多强?
通过解决这些难题,星辰语音大模型实现了单模型同时支持普通话、英文和40种方言的自由混说,并可以通过“一个”ASR(自动语音识别)能力应用于全国多个方言区域,带来更灵活的功能和服务选择,大幅改善用户体验。
星辰语音大模型的超多方言能力应用场景丰富多样,涵盖会议系统、智能客服、校园安全、助老助农等多个领域。在智能会议场景,其超多方言识别能力已上线星辰慧记智能会议系统,日均处理语音超700分钟,助力企业快速转写并总结不同地域的客户声音,提升开会效率。

星辰慧记智能会议多方言音频转写
在智能客服场景,星辰语音大模型已在北京、福建、江西、广西、内蒙古等地的中国电信万号智能客服试点应用,让万号智能客服秒懂40种方言,自然流畅地服务用户,日均处理超过200万通电话。此外,星辰语音大模型还落地多地市的12345平台,赋能客服人员更自然流畅地理解市民通过方言提出的问题和需求。

通过星辰语音大模型,方言不再成为“鸡同鸭讲”和“难以逾越”的鸿沟。只需一通电话,智能客服就能“听懂”全国各地的用户需求,并第一时间提供解答和帮助。作为最早布局并首先开源大模型技术的央企机构,TeleAI已将星辰语音大模型的超多方言预训练和微调阶段代码及相关预训练模型正式对外开源,目标加速AI技术的快速落地和应用普及。在今年9月举办的权威国际语音顶会Interspeech2024上,星辰语音大模型凭借领先的技术实力,在离散语音单元建模挑战赛中斩获语音识别赛道冠军;并在IEEESLT2024说话人溯源国际挑战赛的说话人确认赛道获得第一名。
星辰语音大模型的详细技术报告已在第十九届全国人机语音通讯学术会议(NCMMSC2024)成功发表,相关论文也已在IEEESLT2024发表。
论文及开源地址:
GitHub:Github.com/Tele-AI/TeleSpeech-ASR
