近期AI方向持续活跃。算力、DeepSeek概念股本周走强,指数方面,中证云计算与大数据主题指数上涨7.8%,中证软件服务指数上涨7.4%,中证人工智能主题指数上涨3.9%,国证机器人产业指数下跌0.6%。
《中国人工智能计算力发展评估报告》指出,大模型和生成式人工智能推高算力需求,中国智能算力增速高于预期,2024年,中国智能算力规模比上年增长74.1%,增幅是同期通用算力增幅的3倍以上。
DeepSeek应用上线20天,日活规模突破2000万,成为全球增速最快的AI应用之一,与此同时,腾讯云、百度云、英伟达NIM等云服务平台快速上线DeepSeek大模型,方便用户快速部署。
对此,财联社VIP特邀行业专家全面解读大模型与云平台合作部署模式,2月6日(周四)19:00,携手蜂网专家为您带来“AI模型上“云””主题的[风口专家会议]。
云+大模型核心逻辑
电话会议纪要
问题一:AI大模型与云平台之间有哪几种合作模式?
专家:大模型与云平台的合作模式主要分为三种:一是云厂商自主研发大模型,通过API等形式在云平台上提供服务,国内云厂商还支持私有化交付,即以私有云形式软硬一体进行交付,通过云及部分上层应用一并向客户进行交付;二是云厂商将开源模型(如Meta的Llama系列)以第三方模型形式附着在云平台上,支持用户直接部署或通过API调用;三是云厂商通过云市场转售第三方大模型产品,例如火山云平台转售智谱等大模型的API调用。此外,用户也可单独向云平台购买基础设施Infra(类似于GPU服务器),自行部署和维护自身大模型服务,在这种情况下云厂商仅提供算力资源。
总的来说,云平台既可以通过大模型形成多样化的AI应用生态,还可以为模型应用提供一系列工具和资源支持,包括搜索(如WEG)、互联网搜索接入、Agent智能体搭建等应用工具,以及计算、存储、网络等传统云服务资源,满足大模型应用的底层需求。云平台厂商以大模型为核心卖点,整合工具和资源,构建生态系统,服务于生态内的开发者。
问题二:DeepSeek出圈主要是基于哪些自身特质?
专家:DeepSeek的出圈源于技术突破和市场策略的结合。DeepSeek的基础大模型DeepSeekV3在技术上表现卓越。DeepSeek历代模型都处于领先水平,无论是V2还是V2.5,作为开源模型,其性能追平甚至超越了同期Meta的Llama系列。尽管DeepSeek在C端服务和国内市场活动较少,但其开源模型在训练成本上表现出显著优势,仅用600万美金便完成了高质量模型的训练。同时,DeepSeek在硬件算力方面表现出极致追求,其稀疏MoE模型和多头注意力机制更具独创性。在预训练成本日益攀升的背景下,DeepSeek凭借其低成本高效率的特点引起了业内广泛关注。
DeepSeek的真正爆点是R1模型的发布,R1模型是开源世界中首个追平OpenAIo1和Google顶级模型(如GPT-4和Gemini2.0)的模型,且在短时间内通过开源方式公开了其训练方法和工程细节,打破了巨头企业对强化学习技术的垄断。R1的发布不仅迅速引爆了行业关注,还因其低廉的服务价格(仅为OpenAI的3%-4%),彻底颠覆了巨头通过技术优势获取高额利润的模式。此外,R1的推理逻辑非常适合处理复杂的多步骤任务(如智能体Agent),为应用开发者提供了高效且低成本的工具,推动了大量应用的快速落地。
DeepSeek在研究方法上也进行了创新,其RO1Zero在一定程度上摒弃了传统的SFT步骤,直接采用纯粹的强化学习,仅通过奖励模型进行训练,取得了显著成果。这一方法为开源社区提供了新的研究方向,可能解锁数据飞轮的潜力,从而在商业和技术上开辟更大的空间。
综合来看,DeepSeek凭借其技术领先性、低成本高效率的训练模式、开源透明的策略以及创新的研究方法,成功在业内和普通用户中引发了广泛关注,成为同期强化学习领域的佼佼者。
问题三:此次出圈是否将加速大模型与云厂商之间的合作进展?云厂商如何受益于DeepSeek的成功出圈?
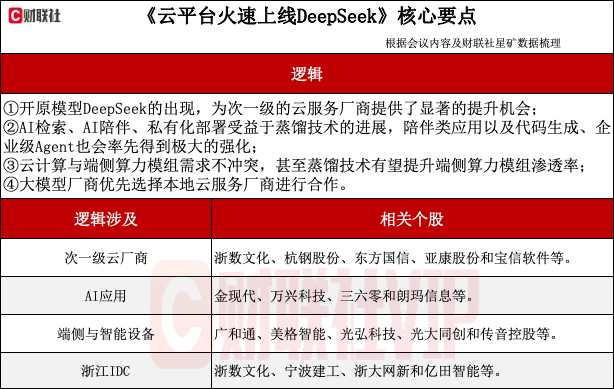
专家:DeepSeek对国内外头部云厂商(如微软Azure、AWS、GoogleCloud、阿里云的天问等)的影响较小,主要是因为头部云厂商已拥有独占的领先闭源模型。对于次一级的云厂商(如金山云、UCloud等)来说,DeepSeek的开源模型为其提供了显著的机会。这些厂商通常难以获得最先进的大模型技术,容易陷入同质化竞争和价格战。DeepSeek通过MIT许可开放其领先模型,使二三线厂商能够提供最领先的大模型产品,充分发挥其成本优势,从而在市场竞争中重新站到同一起跑线上。
此外,DeepSeek的模型能力(尤其是强化学习和推理能力)为应用开发带来了新的可能性。随着模型和开发工具逐渐成熟,2025年智能体Agent可能迎来一波应用爆发。
DeepSeek的模型通过多步推理和纠错机制,能够有效减少幻觉和错误,特别适合处理复杂的多任务场景。这种能力在延迟敏感性较低的Agent应用中尤为突出,将进一步推动应用开发和云厂商工作负载的增长。DeepSeek还通过模型蒸馏技术提升小模型的能力,解锁了更多应用场景,例如AI搜索。通过多步理解和推理,AI检索的准确性和实用性得到显著提升,这将进一步推动相关应用的普及和资源消耗的增长,从而为云厂商带来更多机会。
在端侧模型方面,DeepSeek的蒸馏技术能够快速提升小模型的能力,结合现有移动设备的强大算力,端侧AI应用的潜力正在逐步释放。尽管端侧模型的场景解锁可能需要更长时间,但随着技术的进步,更多AI能力将被集成到本地设备中,进一步扩展应用场景和用户体验。
问题四:目前国内主要有哪些云服务厂商?竞争格局如何分层?
专家:国内云市场的主要格局由阿里云、华为云、腾讯云以及运营商云(如电信天翼云、移动云、联通云)构成。其中,阿里云、腾讯云和华为云是传统公有云服务商的代表,而运营商云凭借政企类项目的扩张,市场份额和影响力近年来显著提升。
其发展路径与AWS高度相似,体现了对云原生技术的深刻理解和实践能力。阿里云:作为国内云计算的领军者,阿里云技术积累深厚,云架构设计和开发组件最为完备。阿里云的许多产品设计和技术路线都展现了其作为行业标杆的实力。
腾讯云:虽然起步较晚,但腾讯云凭借技术和价格优势,迅速占领了市场份额。近年来,腾讯云在技术上的补齐速度令人瞩目,逐渐缩小了与头部厂商的差距。
华为云:从运营商服务起家,华为云以政企项目为立身之本,快速扩展至公有云领域。目前,华为的市场份额已经超过腾讯。
华为云在特定服务上具有显著的技术优势,尤其是与其传统业务相关的领域。尽管在全盘技术上仍存在一些短板,但华为云自认是进步最快的厂商之一。此外,华为云通过自研芯片服务器等方式,在算力成本上具备差异化优势,尤其在AI加速计算等领域表现突出。
运营商云:以电信天翼云、移动云、联通云为代表的运营商云,主要依托政企市场扩张。
问题五:介绍一下第三方数据中心的市场情况?
专家:得益于地方国企、运营商以及政府直属企业的积极参与,大量智算中心相继投建,但其运营水平和能力参差不齐。部分智算中心具备较强的运营能力,能够组建和维护算力集群,提供高质量的服务。而另一些智算中心则更多依赖资源优势(如低廉的地价、能耗指标等),主要作为单纯的数据中心提供方,将服务器和计算能力的组网等任务交由用户自行处理。
过去一段时间,智算中心的建设呈现“大干快上”的特点,尤其是一些跨行业进入的国有企业,其管理相对粗放。然而,这些企业凭借自身禀赋,提供了投入产出比较高的算力资源。许多非大模型为主业的企业(如多模态或图像处理领域)会选择租用这些智算中心,通过组建小型团队进行维护,这些企业能够以较低成本获得适用于特定场景的垂类模型,无论是训练还是服务部署,都能满足其需求。
问题六:蒸馏技术的成功还会对哪些类型的AI应用形成较大的推动作用?
专家:受益于蒸馏技术的AI应用方向较多,包括AI检索、AI陪伴、私有化部署等。AI检索方面,秘塔已经上线了R1检索。但目前存在一个问题:在C端的AI应用中,获得行业共识的并不多。接下来,陪伴类应用以及一些B端应用(如代码生成、企业内替代RPA的自动化代理Agent)应该会率先得到极大的强化。
其次,很多原来私有化部署的场景也将受益。以往,通常要部署一个能力可观的私有化模型,硬件采购成本较高,对数据中心的要求也相对较高。接下来,这部分应该会通过蒸馏提供小模型的方式快速发生变化和迭代。
最后,DeepSeek将推动端侧发展,包括手机、眼镜、音箱、耳机等场景。
到目前为止,DeepSeek更多是在文本大模型方面,尚未泛化到其他更多领域。如果泛化到更多领域,车端的自动驾驶等领域都会受到后续影响。
问题七:云服务平台还涉及到边缘计算,云厂商业务的发力是否意味着端侧硬件算力模组的需求下降?
专家:不会,这本质上是两类需求。端侧需求是让原本传统设备实现智能化,若仅靠设备联网与云端大模型互动,很难形成大规模市场。以智能音箱场景为例,以往很多项目是通过大模型与云端大模型交互,将自然语言指令转化为设备执行指令再返回,经屋内智能家居中心(Hub)发给具体设备如空调。由于链路长,网络传输一旦出现抖动或不稳定等情况,就会影响使用体验。相反,若通过蒸馏技术利用端侧算力,将蒸馏好的可执行大模型推到端侧,可能引发新一波应用场景解锁。
另一类是本身自带智算功能的终端,如手机、笔记本电脑等。各厂商的AIPC都比较重,有的加显卡,轻一点的也需用高通NPU芯片等来加速计算,因为端侧模型运行需要计算设备。如果端侧模型能力有限,需要使用CPU,CPU的负载容易迅速占满。若模型蒸馏得好,可降低这部分成本,老旧设备或许仅通过软件就能具备相应能力,这也会大大解锁原有的未开拓的市场。
云端应用(互联网C端应用、助力SaaS软件的应用)本身不属于端侧市场。模型能力提升后,其推理需求会极大扩展,解锁新场景,但对原有推理情况影响不大。可能原推理场景中原本需8张H100才能推理,现在缩到4张、2张甚至1张H100就能实现,可能会节约计算资源,但从场景解锁角度看,端侧不会侵蚀云端。
问题八:近几年云计算厂商的盈利情况发生了怎样的变化?在大模型逐渐成熟的2025年,其利润是否有望出现大幅增长?
专家:总体来看,目前云厂商处于投资阶段,虽然面临诸多不利,但也存在一定的有利条件。不利条件:盈利情况方面,国内云厂商(特别是上市公司)整体盈利状况不太好,以阿里云为例,其盈利时间不长,与国外同行(AWS、Azure、GCP)相比利润情况不佳。国内云市场中阿里云、腾讯云、华为云价格战不断。成本投入方面,海内外厂商投入大量资金和成本训练模型以确保技术领先,而目前大模型应用尚未真正爆发,靠卖Token改善盈利还难以预见。
有利条件:DeepSeek模型(特别是蒸馏小模型)出现后会大量盘活原有计算资源,大模型时代,之前用于计算机视觉推理的如V100、T4等卡提及较少,若蒸馏小模型验证成功,像B100之类的卡会被再次盘活,云厂商的固定资产能发挥更大价值,有更多新应用可能选择性价比更优的产品。
问题九:第三方云厂商的服务是否存在地域优先性?
专家:确实存在一定的地域性,比如杭州的客户可能优先选择杭州的数据中心。从技术角度看,数据中心距离更近时,面临的数据吞吐和传输压力更低,数据延迟也会更低。一旦出现各种情况,能采取的措施相对更便捷。政策因素上,各地政府对本地企业使用本地算力中心等情况有一定的扶持、补贴政策,比如发放算力券或其他优惠政策,所以企业选择本地的数据中心能够更好地享受这些扶持优惠。
问题十:DeepSeek是否会成为今年的最强模型,还是说后半年可能会冲出另一匹黑马?
专家:到2025年年底,无论是在全球还是国内范围,DeepSeek依然是最强模型之一,但独占霸主地位比较困难。在全球范围内,DeepSeek的R1与OpenAI的o1、Gemini2.0的Flashthinking都处于同一级别,无明显压倒性优势。OpenAI可能因盈利目的将价格拉高,但Google新推出的Flashthinking推理模型虽未正式标价,但推测价格不会比DeepSeek贵很多甚至可能更便宜,这表明R1只是将自己与世界领先厂商拉到同一水平线上,难以确定DeepSeek是否能碾压式超过OpenAI和Google,可能长期处于并跑状态。
从DeepSeek的论文可知,大模型的强化学习还处于非常初期的阶段,Scalinglaw与预训练相比处于陡峭曲线的前半段,后续竞争是爬坡能力的比拼,在这种情况下,谁能快速获取成果难以确定,所以DeepSeek很难在全球范围内确定成为最强。
在国内,DeepSeek公开部分技术路径后,很多国内厂商可快速复现,比如阿里的QWQ、智谱的GLM、Kimi的k1.5、阶跃星辰的step系列。之前就有不少厂商推出过自己的强化学习模型,在已有积累基础上叠加DeepSeek的线路,各厂商追赶速度较快,DeepSeek可能面临类似OpenAI的创新者窘境,而字节、阿里等资源优势厂商全情投入时,其先发优势能保持多久也不好说。不过,凭借其强悍的工程能力和对业务的专注,DeepSeek保持在第一梯队应该没有问题。
本文源自:财联社早知道
