出品|虎嗅科技组
作者|余杨
编辑|苗正卿
头图|Figure
2月21日凌晨,BrettAdcock在X上发布了Figure“历史上最重大的人工智能更新”——Helix。

这是Figure与OpenAI终止战略合作后核心技术成果的首次展示,半个月前,BrettAdcock即预告过这项“人形机器人上前所未有的技术”。
Helix是一种用于通用人形机器人控制的“视觉-语言-动作”(VLA)模型,能够将感知、语言理解和学习控制统一起来,这意味着对机器人技术领域多项长期挑战的克服。
根据官网消息,Helix实现了一系列首创,包括整个上身控制、多机器人协作、拿起任何东西(即使是从未见过的东西)、同一神经网络、已做好商业准备等创新点。

在官方发布的视频中,实验人完全使用语言交流控制,从纸袋中拿出了机器人第一次见的物品,要求机器人通过思考,把眼睛所看到的东西归置到它们应该在的位置,并且要求两个机器人共同协作去放好。

随后,从视频中看来,两个机器人(左A右B)通过识别、推理,机器人分别打开了抽屉柜和冰箱,机器人A将密封物品放进了抽屉柜,机器人B将需要保鲜的物品放进了冰箱。接着,机器人A又将看起来需要保鲜的食物递给机器人B,机器人B接过食物,看了看机器人A,又看了看手中的食物,转手丝滑地放进了冰箱。稍后还有机器人B将物品交给机器人A归置到抽屉柜以及协作将苹果放进左下角黑色圆盘的操作。
也就是说,Helix是第一款对整个人形上身(包括手腕、躯干、头部和各个手指)进行高速率连续控制的VLA,可以同时在两个机器人上运行,使它们能够使用从未见过的物品解决共享的、远程操作任务,配备了Helix的Figure机器人只需按照自然语言提示,就能拿起几乎任何小型家居物品,包括数千种它们从未遇到过的物品。
并且,与之前的方法不同,Helix使用一组神经网络权重来学习所有行为(如挑选和放置物品、使用抽屉和冰箱以及跨机器人交互),而无需任何针对特定任务的微调。由于是第一款完全在嵌入式低功耗GPU上运行的VLA,它还能够迅速实现商业化。
事实上,去年1月,Figure和宝马就建立了合作关系,宝马在其位于南卡罗来纳州的工厂部署了Figure机器人,人们对人形机器人进入家庭解放双手的期待不断高涨。
听起来简单,但却是机器人技术面临的一大挑战。与受控的工业环境不同,家里堆满了无数的物品——精致的玻璃器皿、皱巴巴的衣服、散落的玩具——每件物品都有不可预测的形状、大小、颜色和纹理。为了让机器人在家庭中发挥作用,它们需要能够按需产生智能的新行为,尤其是对它们从未见过的物体。
对于这个难题,以往的机器人技术有两种解决方案:要么通过N小时的博士级专家手动编程来教机器人一种新行为,要么是N千次演示。然而,家庭问题的样本变化多端,这两种方法的成本都太高了。
Figure大方介绍了自己的模型思考原点。即:如果能简单地将视觉语言模型(VLM)中捕获的丰富语义知识直接转化为机器人动作,这种新功能将从根本上改变机器人的扩展轨迹(如下图所示),曾经需要数百次演示的新技能只需用自然语言与机器人交谈即可立即获得。

不过,关键问题在于:如何从VLM中提取所有这些常识性知识并将其转化为可泛化的机器人控制?这就涉及到了Figure的突破——Helix。
过去的方法面临着一个根本性的权衡:VLM主干是通用的,但速度不快,而机器人视觉运动策略是快的,但不通用。Helix通过两个互补的系统解决了这一权衡,即“系统1、系统2”VLA模型,这两个系统经过端到端的训练,可以进行通信:
系统2(S2):一个机载互联网预训练的VLM,以7-9Hz的频率运行,用于场景理解和语言理解,从而实现跨对象和上下文的广泛概括。
系统1(S1):一种快速反应的视觉运动策略,将S2产生的潜在语义表征转化为200Hz的精确连续机器人动作。
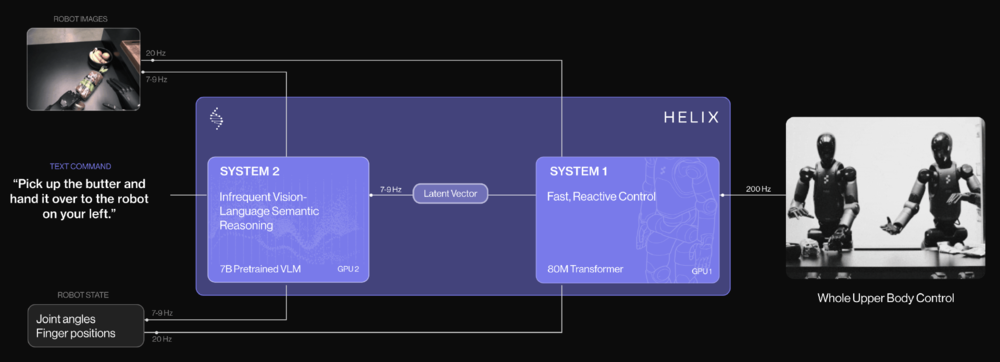
这种解耦架构允许每个系统在其最佳时间尺度上运行。S2可以“慢慢思考”高级目标,而S1可以“快速思考”以实时执行和调整动作。例如,在协作行为期间,S1可以快速适应伙伴机器人不断变化的动作,同时保持S2的语义目标。

总结Helix技术上的创新点就是:
速度和泛化:Helix匹配专门的单任务行为克隆策略的速度,同时将零样本推广到数千个新颖的测试对象。
可扩展性:Helix直接输出高维动作空间的连续控制,避免了先前VLA方法中使用的复杂动作标记方案,这些方案在低维控制设置(例如二值化并行夹持器)中已取得一些成功,但在高维人形控制中面临扩展挑战。
架构简单:Helix使用标准架构-用于系统2的开源、开放权重VLM和用于S1的简单的基于变压器的视觉运动策略。
关注点分离:将S1和S2解耦,我们可以分别在每个系统上进行迭代,而不受寻找统一的观察空间或动作表示的限制。
具体来说,Helix能够控制从单个手指运动到末端执行器轨迹、头部注视和躯干姿势等一切。视频演示中,机器人用头部平稳地跟踪双手,同时调整躯干以获得最佳触及范围,同时保持精确的手指控制以进行抓握。
从机器人技术更迭历史看,在如此高维的动作空间中实现这种精度水平被认为是极具挑战性的,即使对于单个已知任务也相当困难,因为一般来说,当头部和躯干移动时,它们会改变机器人可以触及的范围和可以看到的范围,从而产生反馈循环,而这种反馈循环在过去会导致不稳定。之前没有VLA系统能够展示这种程度的实时协调,同时保持跨任务和对象泛化的能力。

两个Figure机器人之间的协作零样本杂货存储的过程中,机器人成功地操作了全新的杂货(训练期间从未遇到过的物品),展示了对各种形状、大小和材料的稳健泛化。此外,两个机器人都使用相同的Helix模型权重进行操作,无需进行针对机器人的训练或明确的角色分配。它们通过自然语言提示实现协调,例如“将一袋饼干递给你右边的机器人”或“从你左边的机器人那里接过一袋饼干并将其放在打开的抽屉里”。
并且,通过简单的“拾起[X]”命令拾起任何小型家用物品。在系统测试中,机器人成功处理了杂乱无章的数千件新物品(从玻璃器皿和玩具到工具和衣物),无需任何事先演示或自定义编程。

尤其值得注意的是,Helix一定程度上弥补了互联网规模语言理解与精确机器人控制之间的差距。例如,当被要求“捡起沙漠物品”时,Helix不仅能识别出玩具仙人掌符合这一抽象概念,还能选择最近的手并执行安全抓住它所需的精确运动命令。

不仅如此,从训练成本来看,Figure总共使用约500小时的高质量监督数据来训练Helix,这仅仅是之前收集的VLA数据集的一小部分(
