图解传统RAG与REFRAG差别一图解释Meta新RAG方法
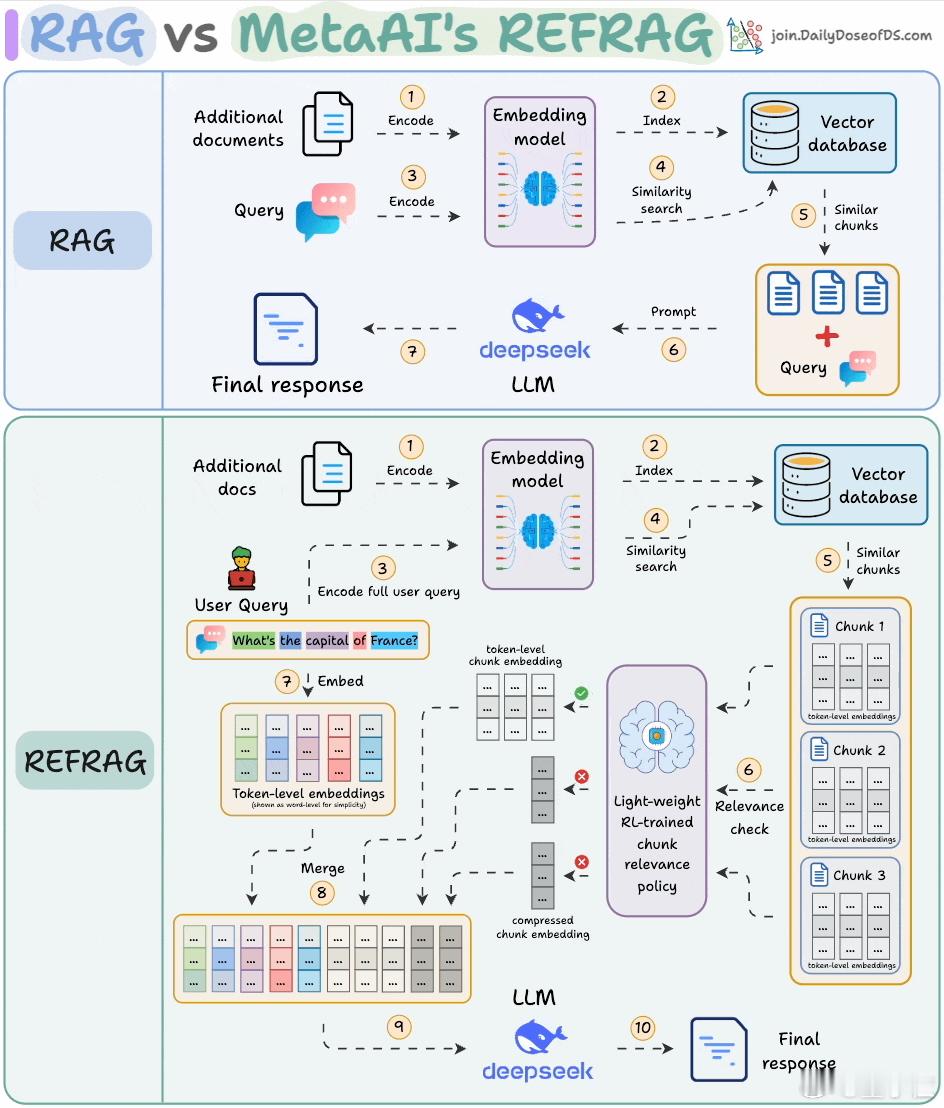
这张图直接揭示了传统RAG和Meta新方法REFRAG()的本质区别。
先看上半部分,是传统RAG流程:
1. 当用户提问后,系统会先将问题编码成向量;
2. 然后去数据库里搜索相关文档的相似向量;
3. 找到后,就把这些“相似”的原始文本直接丢给大模型处理。
问题在于,一口气给模型扔一堆原文,其中大部分其实没啥用,于是就造成:
- 延迟高(每段都要处理),
- token数量爆炸(又慢又贵),
- 模型容易被无关信息干扰,影响准确率。
再看下半部分,是Meta提出的REFRAG流程:
1. 还是先编码文档和用户提问,并从向量库搜索相关内容;
2. 但不同的是:每段文档提前被压缩成一个embedding(例如16个token压成一个向量);
3. 接着,一个强化学习训练出的筛选器(图中小脑袋图标)会评估每段内容的相关性;
4. 只保留“重要的”内容做完整展开(恢复成原始token,让大模型精读);
5. 不重要的内容就保持压缩格式,仍可以提供背景线索,但不会影响模型主视角;
6. 全部拼好之后再丢给大模型回答。
这样做的好处是:
- 模型只看关键信息,不用每句话都精读;
- token使用量更少、速度更快;
- 背景知识依然保留,但不会抢位置;
- 加速度的同时确保准确率、不丢信息。
可以理解为传统RAG是“大段投喂”,而REFRAG更像是“智能做摘要”,只喂核心内容,其他信息做压缩处理备用。
总结一下:
传统RAG:检索→全量拼接→硬塞给模型
REFRAG:检索→压缩编码→选重要信息→部分展开→智能拼接→送给模型




![索尼手机[哭哭][哭哭][哭哭]](http://image.uczzd.cn/14266120549548014004.jpg?id=0)

![Mate70Air[吃瓜]浑圆的机身,硕大的摄像头模组,实体Sim卡,背面一眼](http://image.uczzd.cn/5642633122303516979.jpg?id=0)

