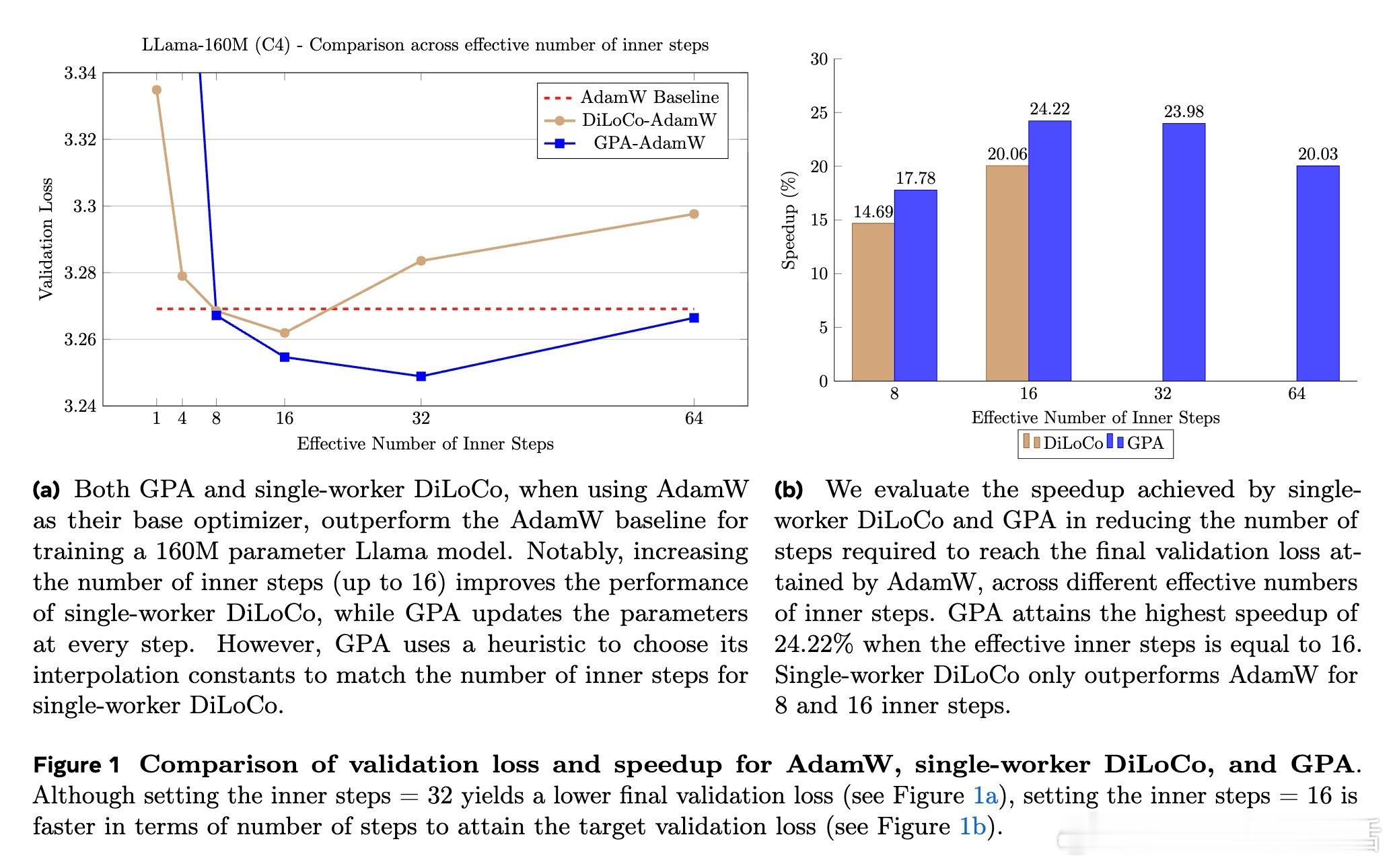
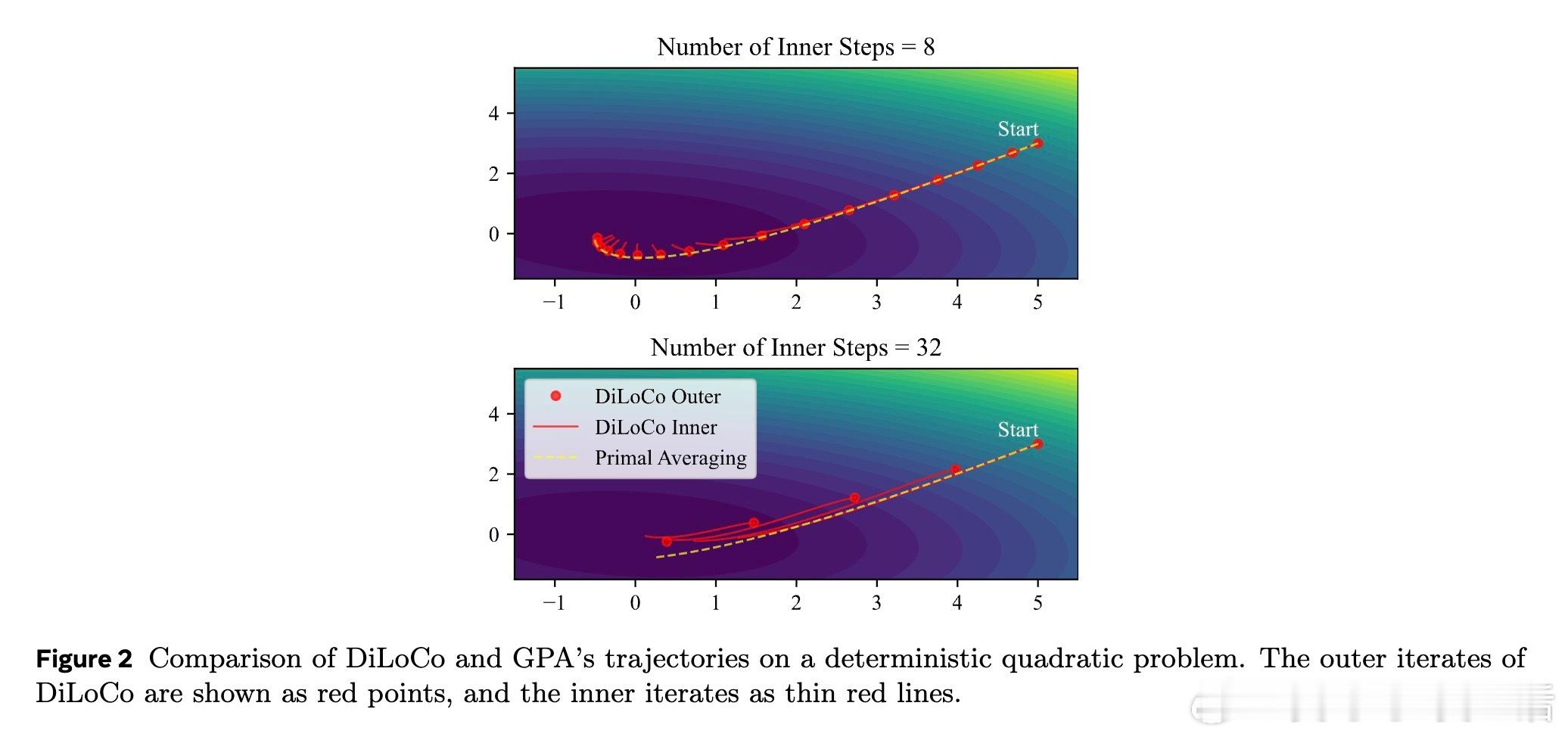
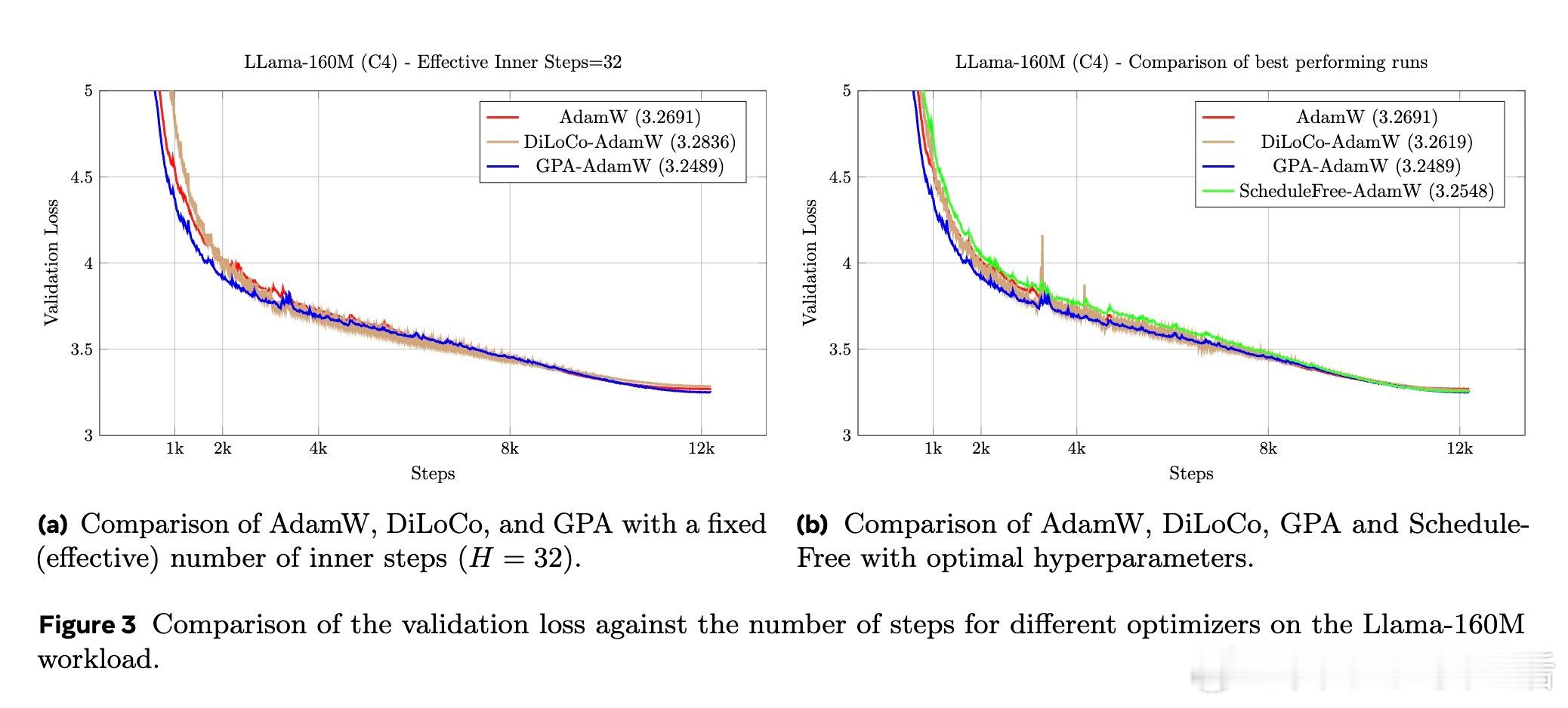
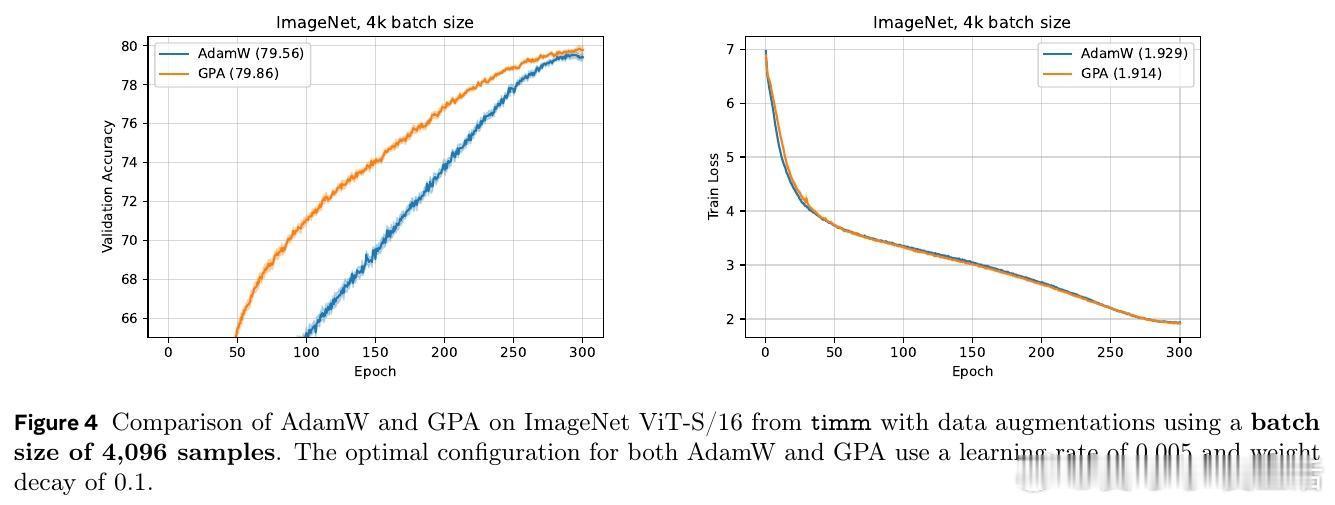
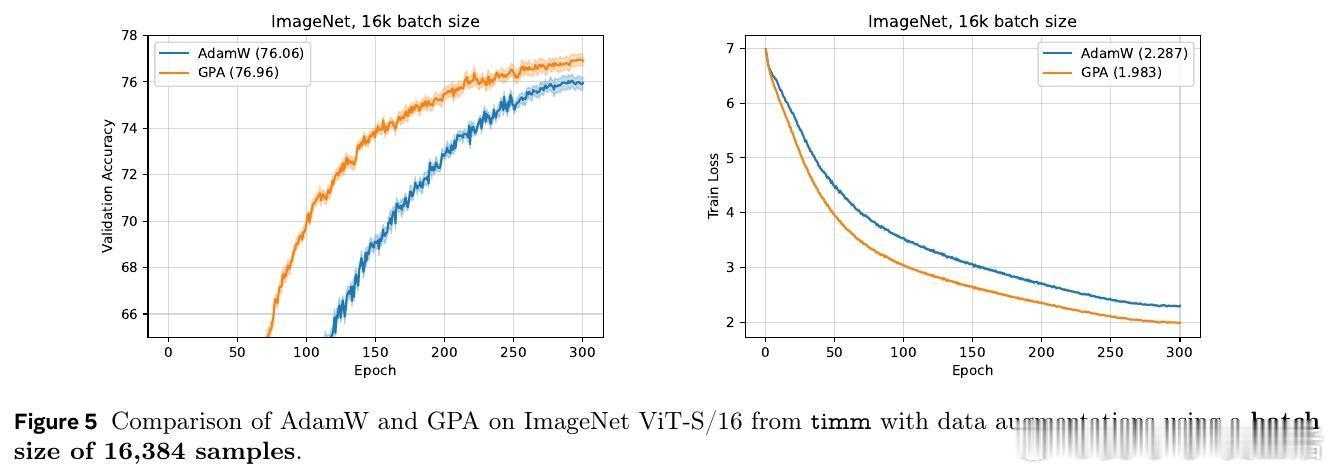
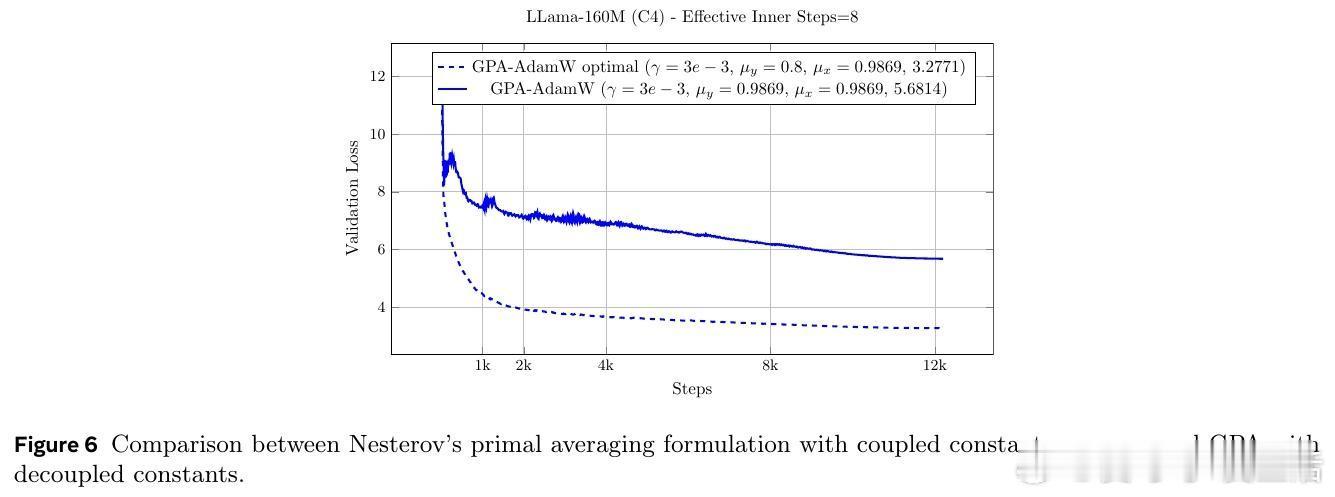
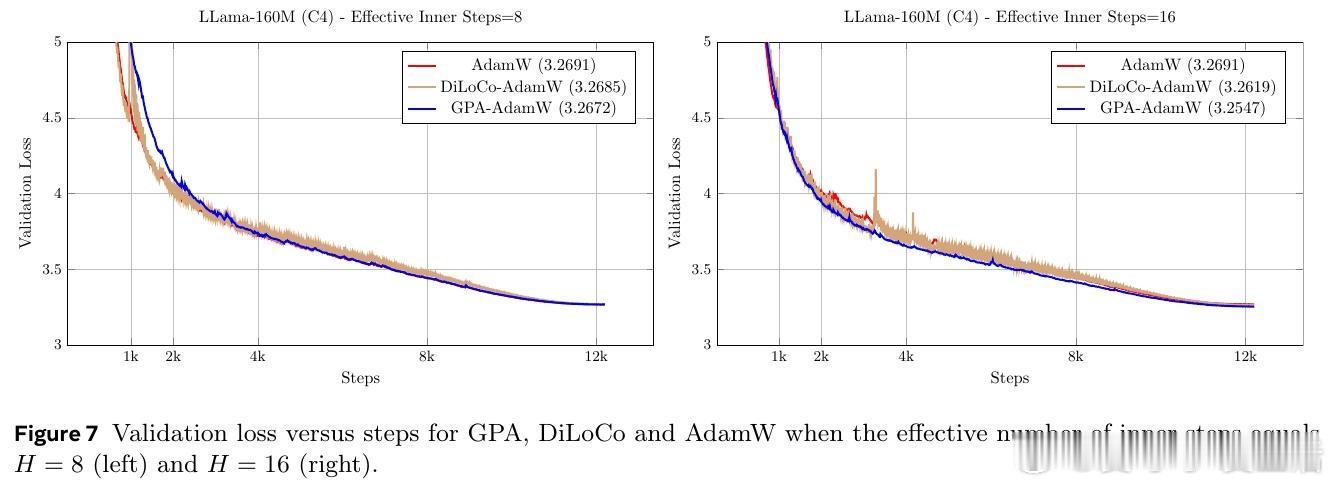
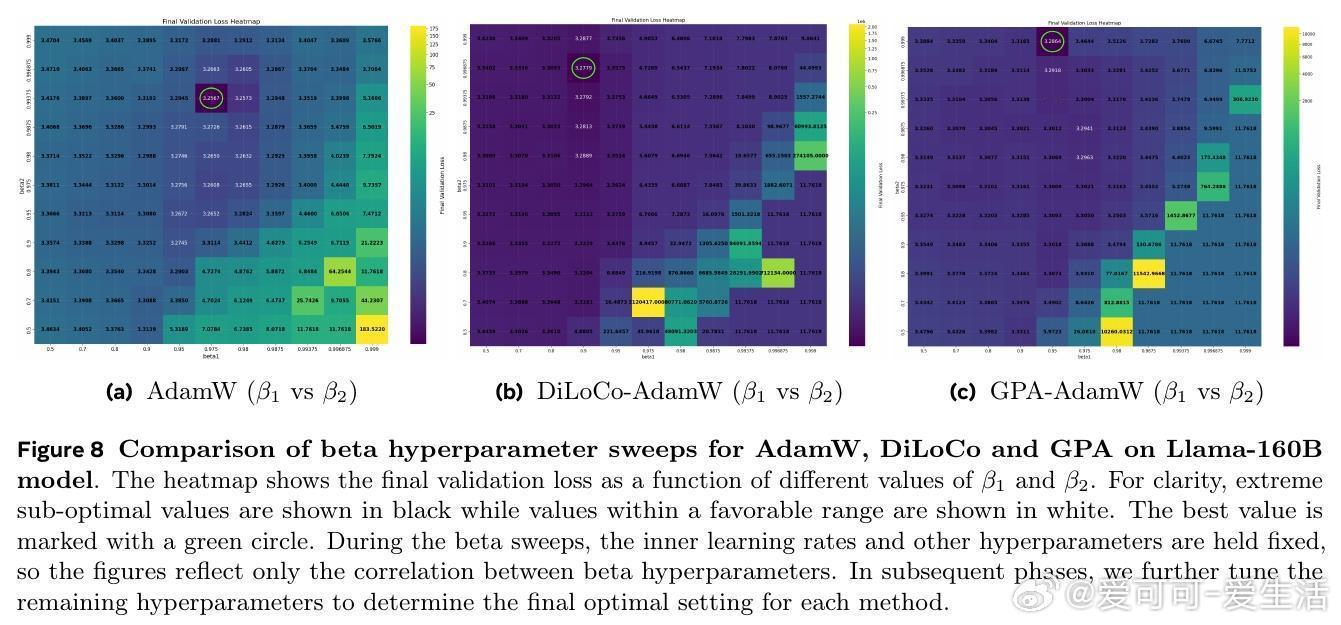
[LG]《Smoothing DiLoCo with Primal Averaging for Faster Training of LLMs》A Defazio, K Mishchenko, P Raman, H M Shi... [Meta Superintelligence Lab] (2025) 大语言模型的预训练是一场与成本和时间的赛跑。Meta Superintelligence Labs 最近提出了一种名为 GPA(Generalized Primal Averaging,广义原对偶平均)的新型优化框架,旨在解决当前主流优化器在效率与内存占用上的痛点。这不仅是一个算法的改进,更是对模型训练“平滑性”与“收敛速度”关系的深刻重构。1. 寻找优化器的最大公约数在分布式训练领域,DiLoCo 是目前的标杆,它通过周期性聚合轨迹来提升性能。而在非分布式场景下,Schedule-Free 优化器则通过权重平均实现了无需学习率调度的突破。然而,DiLoCo 的双层循环结构导致内存开销大且调参复杂,而 Schedule-Free 的统一平均策略又限制了其灵活性。GPA 的出现,正是为了吸取两者的长处,并跳出它们的局限。2. 解耦:优化的艺术在于精细控制GPA 的核心贡献在于对 Nesterov 动量公式的“解耦”。传统方法中,平滑参数同时控制着模型评估点和梯度计算点。GPA 引入了两个独立的插值常数:一个负责模型权重的平滑平均,另一个负责梯度计算点的定位。这种解耦让模型能够以“丝滑”的方式在每一步进行迭代平均,而不是像 DiLoCo 那样断续地跳跃。金句:真正的优化不是在震荡中寻找平衡,而是在平滑的流动中保持敏锐。3. 性能跃升:24% 的时间红利实验数据令人印象深刻。在 Llama-160M 模型上,GPA 相比 AdamW 基准实现了 24.22% 的训练加速。在 ImageNet 的 ViT 训练任务中,大批量设置下的加速甚至达到了 27%。更重要的是,GPA 抛弃了 DiLoCo 复杂的两层循环结构,将内存开销降至仅需一个额外缓冲区,极大地简化了超参数调优。4. 理论支撑:从在线学习到批量转换GPA 不仅仅是经验主义的产物。研究团队通过在线到批量转换理论证明,只要基础优化器的遗憾界(Regret Bound)受限,GPA 就能匹配甚至超越原优化器的收敛保证。理论分析揭示了一个关键点:当目标函数在连续迭代间表现出非线性变化时,GPA 的这种平滑机制能比基础优化器更有效地捕获收敛路径。5. 深度思考:平滑性即速度长期以来,深度学习界有一种直觉:增加训练的“噪声”或“跳跃”有助于跳出局部最优。但 GPA 的成功提供了一个相反的视角:在参数空间进行持续且平滑的平均,反而能带来更稳定的训练行为和更快的收敛。这种“以静制动”的策略,或许正是大规模模型训练走向成熟的标志。6. 开启分布式训练的新可能GPA 的意义不仅限于单机训练。它为重新设计跨地域、低带宽环境下的分布式训练奠定了基础。通过将平滑参数与通信频率解耦,开发者可以更自由地调整计算与通信的比例,而不再受限于 DiLoCo 那种耦合的超参数逻辑。原文链接:arxiv.org/abs/2512.17131