面向对象有三大特性:封装、继承、多态。
在前面的几篇文章中,我们重点介绍了封装特性,同时稍微发散了一下,讲解了Python中对象的生命周期管理。
今天开始讲解面向对象的第二大特性——继承。
复制与复用 & DRY原则在介绍Python中的继承之前,我们先来看一下勤奋的程序员与懒惰的程序员的区别,以下仅为个人观点,不喜可喷。
勤奋的程序员总是准点下班、很少加班;
懒惰的程序员总是忙忙碌碌、一直加班。
勤奋的程序员大多数时间在思考、然后才运指如飞;
懒惰的程序员似乎一直在噼噼啪啪、但时不时卡壳、停下来。
勤奋的程序员写的代码很少,言简意赅;
懒惰的程序员写的代码很多,长篇累牍。
当然,前面只是夸张的修辞,在某些血汗工厂里,勤奋的程序员也总要加班、始终有干不完的活。
其实,在我看来,两者的区别只在于是否践行DRY原则。
所谓的DRY原则,是Don't Repeat Yourself,即“不要重复自己”的意思。是软件开发中的一项很关键的原则,主旨在于减少系统中的代码冗余与信息重复。其基本思想在于,每一段知识(逻辑或者功能)都应该在系统中有且只有一个明确的表示。
遵循DRY原则的好处有很多,比如:
1、提高代码的可维护性,减少重复代码,修改某一个逻辑、功能时,只需要在一处修改,降低了出错的概率。
2、增加代码的可读性,没有重复代码,代码的结构更加清晰、易读。
3、降低代码荣誉,减少了代码量,一定程度上可以优化资源的使用与性能提升。
4、逻辑清晰,简化错误排查与测试的工作量。
帕斯卡说,“人是一根会思考的芦苇”,践行DRY原则的关键在于思考。简单的复制、粘贴组合,其实是放弃了思考的表现。一个事情、一个功能如果要出现超过3次,就应该思考如何优化设计、如何实现代码的复用、如何降低人工成本提高自动化的程度。
所以面向对象、或者编程本身的难点或者说竞争优势,不在于代码的堆砌,因为那样做只会成为一个合格的“码农”;而在于写代码实现前的思考与设计,因为这样做才能称之为“工程师”。
之所以“离题万里”,来聊DRY原则,是因为在Python中,继承是实现代码复用、践行DRY原则的一个很好的实践(还有一个很好的实践,叫做函数重用,之前的文章中已经提到),只有理解了这个原则,才能更好地使用继承特性。
继承说到继承,一定会涉及两个概念,一个是父类,一个是子类。在进入语法与代码的讲解之前,对继承的概念稍微再多说几句。
在不同的语境下,会有一些不同的表达方式,但是本质都是一样的。
1、子类继承父类的属性和方法。
2、父类是子类的泛化,子类是父类的特化,两者是一般与特殊的关系。
3、父类是对子类的抽象,子类是对父类的扩展。
在Python中如何使用继承呢,我们还是以打工人的代码为例,简化来说,打工人的属性有姓名、性别、年龄、薪资等,方法有上班打卡、工作、下班打卡。每个打工人的属性大部分都一样,上下班打卡也一样,但是工作方式会有所区别,则可以通过继承实现复用相同的属性和方法,仅重写不同的部分,代码如下:

执行结果:
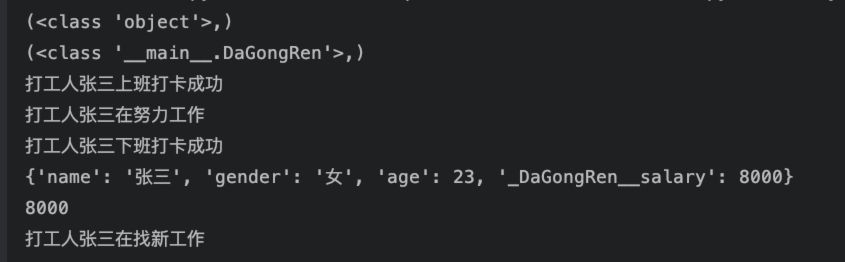
从上面代码中可以看出:
1、继承的语法非常简单:class 子类名(父类名)即可,上面的Programmer类,直接完全继承了父类的属性及方法。
2、在Python 3中,一个自定义的类,如果没有写明继承的父类,则其父类为object,通过类的属性__bases__可以获取到一个类继承的所有父类(也称作基类),返回一个元组,可以看出,Python是支持多继承的。
3、有些教材或者大牛说,子类会把父类的所有非私有属性和方法继承下来,其实是不太严谨的,我们通过__dict__属性,可以看到,其实是继承了混淆后的私有属性的,而且我们通过混淆后的私有方法名,也是可以调用到对应的方法的。
在上面的例子中,我们的子类直接照搬了父类的所有属性和方法,但是,通常情况下,子类会在继承父类属性和方法的同时,重写父类的部分方法,或者新增一些方法,这就是扩展的部分。尤其重写父类的同名方法时,一定要注意,这是实现后续会介绍的面向对象的“多态”特性的一个常用的实现方式。
我们以具体的代码来看,子类重写及扩展父类的情况:

执行结果:

需要注意的是:
1、一旦子类自定义了__init__魔法函数,则在实例化子类对象时,不会再调用父类的__init__方法函数。
2、在子类的方法中,可以通过super()的方式,调用父类中的同名方法。所以,在子类的__init__方法中,可以把通过调用父类的__init__方法,实现name、gender、age、salary属性的初始化,而不用将4个属性再写一遍。
3、需要区分的是,super是一个自定义类,而不是有些人所说的内置函数。
接下来,稍微介绍一下内置类super的使用。
super首先看下super的帮助文档:
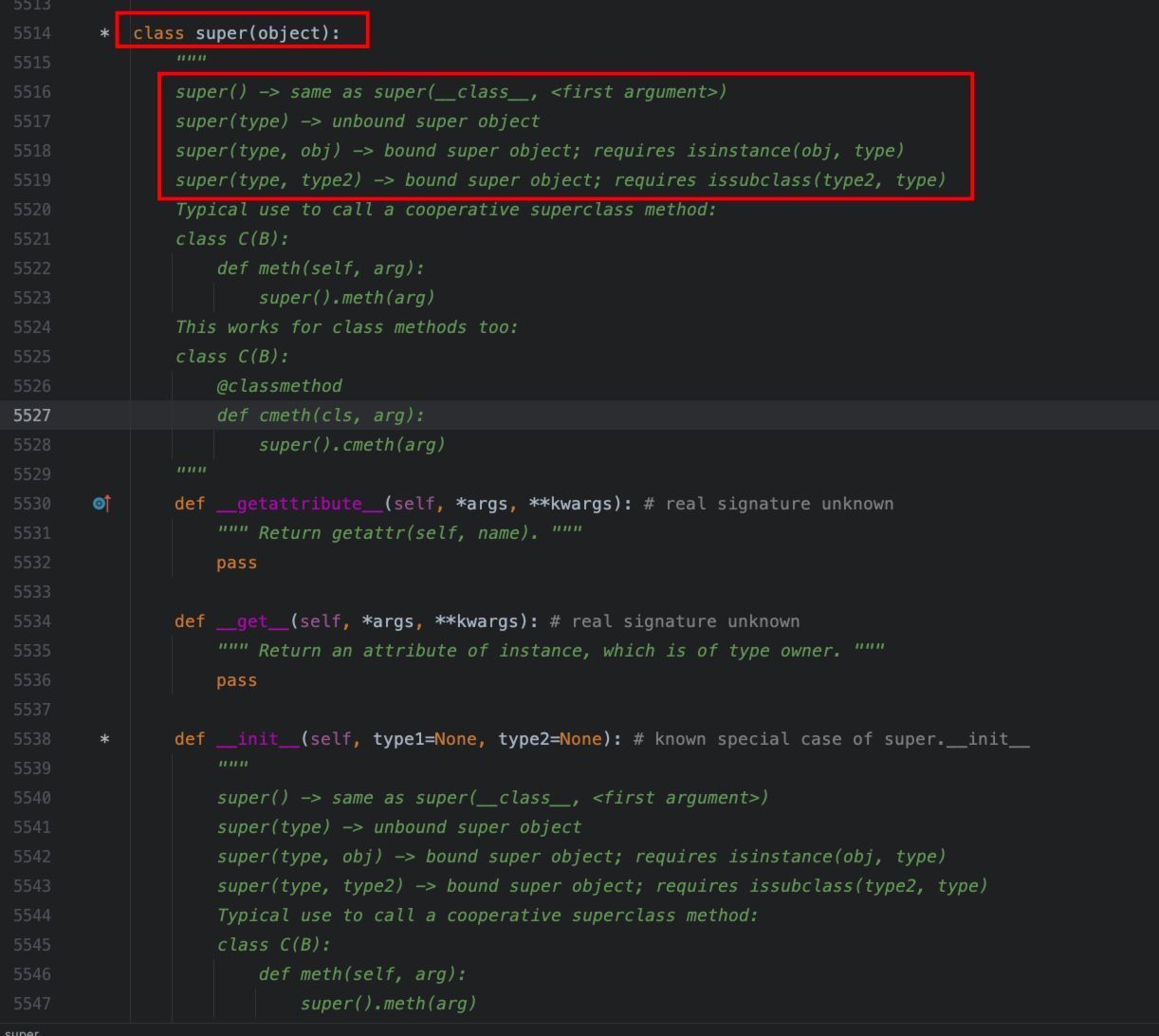
从文档中,可以看出:
1、super是一个内置类,显示继承自object。
2、super的使用场景是,用于在继承链路中,访问父类的属性或者方法。
3、无参的实例化super,相当于super(self.__class__, self)。
4、super(type, obj)可以在继承链上访问任意一个祖先类的方法。
以代码实例来看:
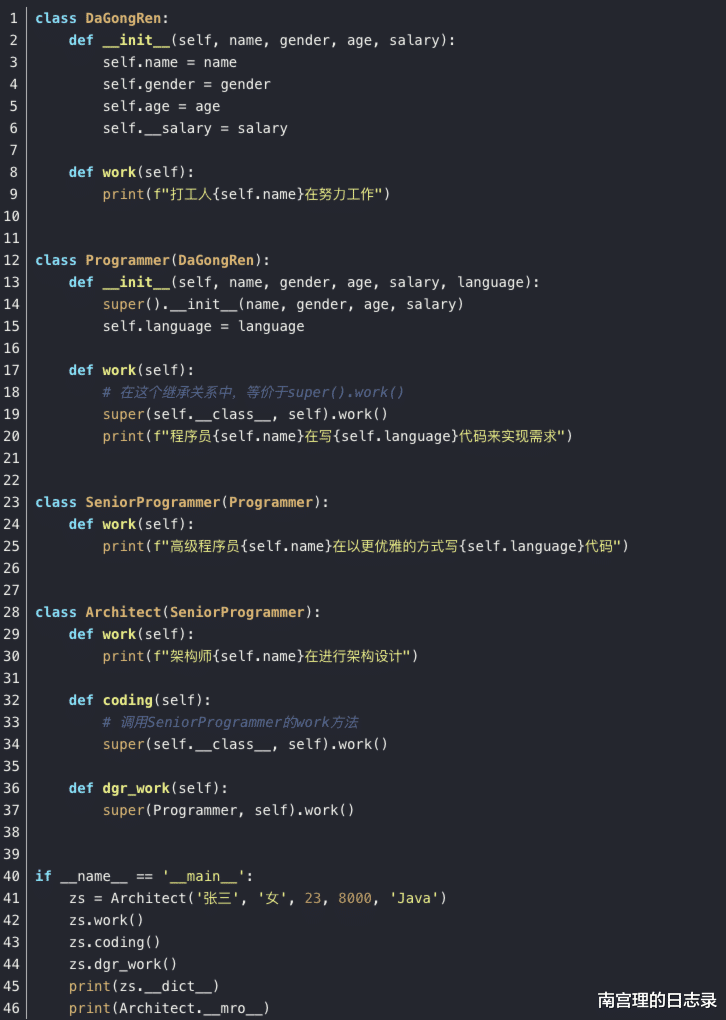
执行结果:

从代码的执行中,可以看出:
1、super(cls, self)可以调用cls的父类的方法或属性,所以在一条继承连路上,子类可以向上溯源,调取任意一个层级的父类的方法或属性。
2、通过类属性__mro__可以查看继承链路中的方法解析熟悉(Method Resolution Order, MRO),也可以通过mro()方法来查看类的MRO。这里只是简单看一下,其实这个顺序就是在子类对象调用一个方法时,在继承路径上的查找顺序,找到了就停止,否则就一直按顺序查找。
type & isinstance & issubclass从上面super内置类的定义中,可以看到,super()实例化的参数,需要符合一定的条件(isinstacne、issubclass),否则会报错。
接下里,通过代码来看下type、isinstance和issubclass的使用:

执行结果:

从代码的执行结果可以得出如下结论:
1、type(obj) == cls的比较,不考虑继承关系的,所以,跟类对象比较是True,而跟父类对象比较则是False。
2、isinstance(obj, cls),则会考虑继承关系,实例对象与任何一个父类对象比较,均会返回True。
3、issubclass(cls1, cls2),适用于比较一个类对象cls1是否是cls2的子类,可以是间接子类。
总结今天的文章中,以DRY原则及关于代码的复用,引入关于Python中继承的使用的介绍。
其实,继承可以理解是用功能增强的点(.)运算符实现的。具体来讲,如果搜索一个属性时未在实例或实例的类中找到匹配项,将会继续搜索基类。这个过程会一直继续下去,直到没有更多的基类可供搜索为止。
此外,Python中还支持多继承,虽然一般不建议使用多继承,但是,关于多继承的简单使用,还是可以稍微介绍一下的,从而稍微理解相关的设计实现思路。所以,下一篇文章中,我们会简单聊下多继承。
感谢拨冗阅读!
