(文章翻译自CNBC,作者:加内什·拉奥)
本周,我在CNBC配发的一台三年旧的笔记本电脑上运行了一个名为DeepSeek-R1的强大人工智能模型。
这个新模型由中国人工智能实验室DeepSeek开发,并于上周发布,引发了美国科技股的大幅下跌。这个极具竞争力且成本可能低得惊人的AI模型让投资者开始质疑大型科技公司目前投入的数十亿美元。
虽然我短暂尝试DeepSeek-R1只是为了满足自己的好奇心,但世界各地数百万其他人可能也出于更具生产性的目的做了同样的事情。

在尝试使用DeepSeek的公司中,很可能包括印度科技公司,它们将首次能够为客户提供一个功能强大的推理人工智能模型,该模型在公司内部进行训练和托管,无需依赖大型科技公司。
中国的DeepSeek发布了其免费供商业使用的模型,并公开了从零开始构建此类模型的技术诀窍。该公司表示,开发该模型仅花费了600万美元的AI芯片成本。
尽管有人对这一数字提出了质疑,但与美国科技公司花费的数亿甚至数十亿美元相比,这一数字仍然较低。
这一发展可能标志着印度国内AI模型开发的开始,因为以往训练大型语言模型的方法需要数千个能耗高且昂贵的AI芯片。这也可能成为印度科技公司(如Infosys)的一个重大转折点,它们此前不得不依赖美国科技公司(如Meta的Llama)创建的AI模型。
WNS公司业务转型首席执行官凯沙夫·穆鲁盖什表示,DeepSeek的AI模型对印度科技公司来说是“关键性的进步”。他认为,较低的开发成本将使印度能够用地区语言训练新的AI模型,并使以往认为不经济的用例成为可能。
目前,绝大多数先进的大型语言模型,如OpenAI的GPT和Anthropic的Claude Sonnet 3.5,只能输出少数几种语言的文本。穆鲁盖什告诉CNBC:“通过利用DeepSeek背后的创新,这些公司可以显著降低成本,并加快上市时间。”在纽约证券交易所上市的WNS在其本月早些时候的第三季度电话会议中透露,该公司将很快在一家美国保险公司(该公司的前十大客户之一)启用生成式AI用例。
行业调查显示,数据隐私和实施大型语言模型的高成本是企业抵制AI采用的原因之一。如果DeepSeek-R1的优势得到确认,将迅速消除十大担忧中的两个,并可能开始解决许多其他问题。印度政府还开始补贴对AI芯片(即图形处理单元)的访问,以使该国的学术界和初创企业能够开始开发AI模型。
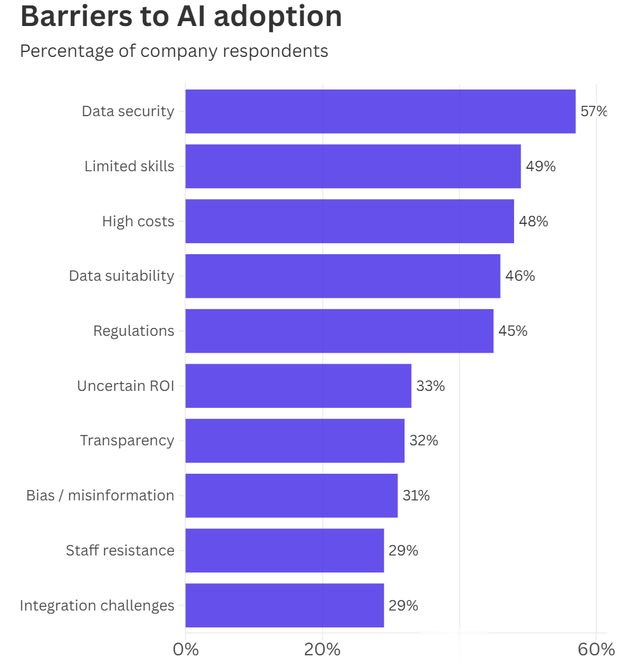
来源:毕马威,《金融中的人工智能》
印度IT服务公司也可能以更间接的方式从DeepSeek中受益。分析师预计,IT公司的大型企业客户将把预算从AI支出转向其他与IT相关的支出。
瑞银(UBS)由沙琳·库马尔领导的股票分析师团队在致客户的报告中表示:“在我们看来,DeepSeek对印度IT服务是有利的。虽然现在还为时过早,无法全面评估其影响,但成本更低、速度更快的AI开发应该有助于释放IT预算,从而增加其他领域的IT支出。”
然而,这可能并不全是好消息。印度券商Anand Rathi的分析师表示,与微软、亚马逊、谷歌和甲骨文等云计算巨头“有大量业务往来”的国内公司“可能会面临短期逆风”,因为更灵活的公司通过转向DeepSeek的低成本AI模型来超越它们。
美国银行的分析师也警告称,服务提供商进入门槛的降低会加剧该领域的竞争,尽管这些风险目前仍处于“非常初步的阶段”。因此,在这个全球化和互联互通的世界中,中国的突破有可能惠及竞争对手印度。
然而,DeepSeek的R1有可能比许多人预期的更早变成一把双刃剑。
美国大型电信运营商AT&T拥有超过1.5亿用户,得益于AI,该公司在一年内将接到的客户支持电话数量减少了30%。该公司在软件开发方面也提高了效率。
AT&T首席执行官约翰·斯坦基在与分析师的电话会议中表示:“我们现在内部开发新代码的成本更低,但收获更多。这是通过应用AI和技术,以及我们利用生成式AI所能做到的。”
虽然使用美国开发的AI模型实施起来成本高昂,但与美国的高工资相比仍然较便宜。鉴于对失业的担忧日益加剧,印度政府将希望更便宜的AI模型不会最终导致低成本工作岗位的流失。
