
清晨的咖啡店,阳光洒落在桌面上,窗外是一片忙碌的街景,人们匆匆走过,而角落里的两个程序员却在低声讨论着一篇新出的论文。
没错,就是那篇引发争议的OpenAI论文。
有人说,这篇论文将改变未来竞技编程的面貌。
而更让人好奇的是,它到底讲了些什么?

我们一起来看看吧!
o系统三兄弟的竞赛成绩在近期的国际信息学奥林匹克竞赛(IOI 2024)和CodeForce比赛中,OpenAI家的o1、o1-ioi和o3三个推理模型展现出了惊人的实力。
o3在IOI 2024中以395.64分夺得金牌,而在CodeForce上,它的得分更是达到了2724分,接近顶级人类选手的水平。

想象一下,一个AI模型在极其严格的规则下能够取得这样的成绩,是多么令人震撼的事情。
提到o1、o1-ioi和o3,相信熟悉编程的人都不陌生。
o1是个经过强化学习训练的大模型,能够处理复杂的推理任务;o1-ioi在o1的基础上进行了专门为竞赛编程设计的训练;而o3,则是在没有人为干预的情况下,依靠自身的学习达到了顶尖水平。
强化学习推动AI自主推理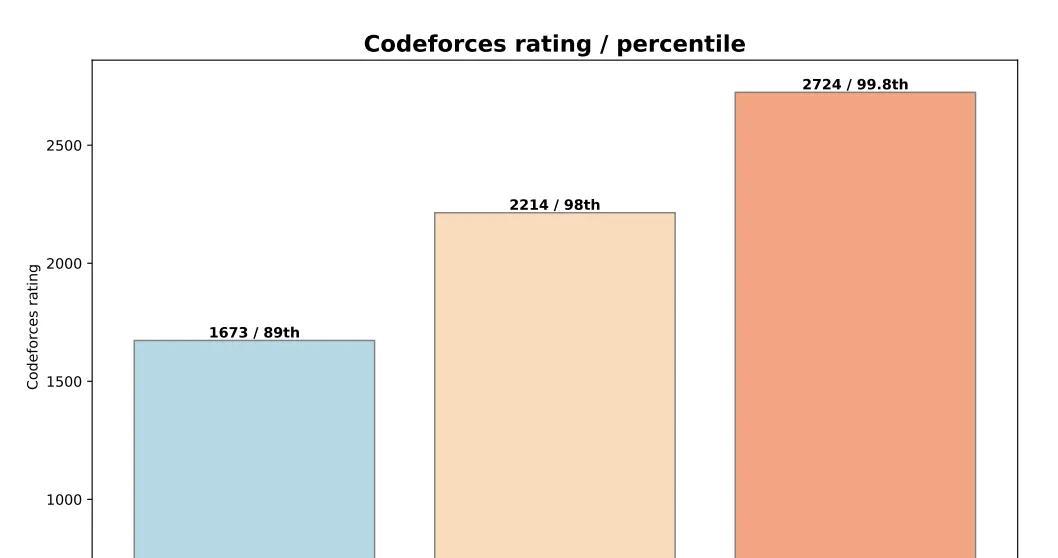
o3的表现让人们不得不重新看待AI推理模型的潜力。
OpenAI的研究证明,o3通过大规模的端到端强化学习,学会了自主推理策略,而不再依赖于人类设计的测试策略。
听起来有些玄乎,但通俗点说,就是o3自己学会了如何在编程比赛中优化解题步骤,这可是个了不起的进步。
强化学习,听起来高大上,其实就是让AI通过不断地尝试和错误积累经验。
就像我们学骑自行车一样,一次次摔倒再一次次爬起来,最终学会保持平衡。
而o3在这种过程中特别擅长,甚至能在有限提交次数的竞赛中频频得高分,这种能力无疑展示了无人工干预的巨大潜力。
推理模型在实际软件工程任务中的应用说到这里,有朋友可能会问:“这些模型在竞赛中那么厉害,那在实际的软件工程任务中又如何呢?

”别急,我们来看看到底是怎么回事。
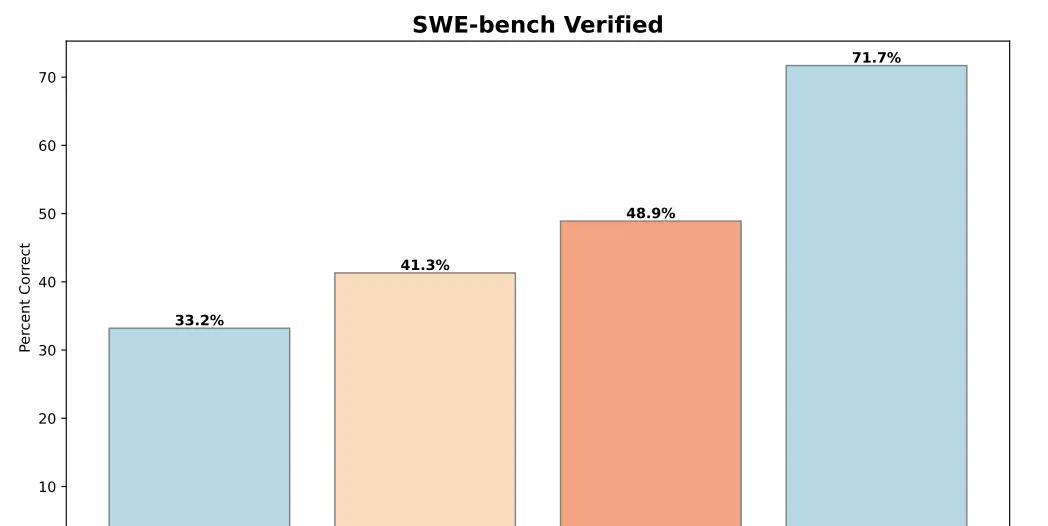
在测试中,OpenAI选用了两个数据集,HackerRank Astra和SWE-bench,来评估o1、o1-ioi和o3三个模型的表现。
结果显示,这些推理模型在真实的软件工程任务中同样表现出色。
HackerRank Astra的数据集中,o1-preview、o1和o3都展示了它们解决复杂编码任务的能力。

特别是在SWE-bench中,o3的表现更加令人瞩目,比起之前的模型有了大幅提升。
真是不看不知道,AI推理模型竟然在实际开发任务上也能表现得如此出色。
未来展望:AI模型单次提交解决问题网友们对o3在IOI和CodeForce比赛中的表现纷纷表示“impressive”,也对未来的AI模型充满了期待。

有人说,或许不久之后,我们就能见到单次提交就能解决每个问题的AI模型了。
毕竟,AI技术的发展一日千里,谁知道明天会带来哪些惊喜呢?
不过,也有一些保留意见的声音。
他们认为,尽管AI在某些方面可以表现得比人类还要优秀,但仍需谨慎看待其应用范围。

毕竟,AI的决策和推理能力在某些特定场景下仍需人类的指导和监督。
文章写到这里,也许你已经对这篇引发热议的论文有了更多的了解。
o3凭借其自主推理策略,在竞赛和实际软件工程任务中崭露头角。
不仅为我们展示了AI推理模型的巨大潜力,也让我们对AI技术的发展有了更多的思考。

回顾那些年,我们躲在电脑前写代码的日子,那时候的我们或许从未想过,有一天,AI能在编程比赛中以如此傲人的成绩出现,甚至有可能超越最顶尖的人类选手。
未来,我们和AI的合作也许将成为常态。
或许,AI不会取代我们,但一定会和我们一起,开启全新的科技篇章。
希望这篇文章能引发你的思考,无论你是程序员、AI研究者,还是对未来感兴趣的普通读者,都能从中找到一些启发和共鸣。

一如既往,科技的进步源于人类的好奇心和不懈追求,让我们带着这份好奇,去迎接更多未知的挑战吧。
这是一次技术与人类智慧的碰撞,是一场充满期待和挑战的旅程。
感谢阅读,期待下一次科技的惊喜与变化。
