每天早上,打开手机,刷刷新闻,突然看到一条:“李开复预言,大模型市场将只剩DS、阿里和字节。”这让人不免心生疑惑:国内AI领域百花齐放的景象,如今怎么只剩这三家了呢?
这不禁让人大开脑洞,想着背后到底有什么样的玄机。
回顾一下李开复,这位曾经的微软全球副总裁、谷歌大中华区总裁,张口闭口都是未来科技发展的大佬,他的预测往往掷地有声,影响力巨大。
那么,这次他关于大模型的观点是什么呢?
AI六小虎与大模型的选择要搞清楚李开复的逻辑,我们可以先看看AI六小虎的故事。
曾经,这些被称作“AI六小虎”的公司在科技圈可是风光无限,个个志在必得,纷纷投入巨资搞大模型。
特别是李开复领导的零一万物,早早就选择DeepSeek的大模型。
人们不免有疑问,他为什么这么笃定地做出这个选择呢?
其实,这与李开复对技术和市场的观察有关。
他认为大模型的研发需要巨大的成本和技术支持。
零一万物放弃自己做大模型,转而拥抱DeepSeek,因为DeepSeek的高效低成本策略让人刮目相看。
另外,在AI领域,技术并不代表一切,能否商业落地才是真正的决战点。
零一万物选择务实的路线,目标明确,深得李开复的心。
不仅仅是零一万物,其他AI六小虎也在技术热潮中逐渐回归理性。
从某种意义上说,2023年的“百模大战”更像是一场资本的狂欢,终有一天要回归常态。
现在,除了得到资本青睐的智谱,其他公司暂缓大模型迭代,也不难理解了。
ChatGPT引发的“百模大战”还记得ChatGPT吧,它可是AI领域的超级明星。
这款产品的出现,彻底点燃了AI市场的激情。
从投资机构到科技公司,大家纷纷涌入这个看似光明的赛道,掀起了所谓的“百模大战”。
为什么会这样呢?
无非是各方都想抢占AI的制高点,希望能分一杯羹。
AI大模型和互联网的路子可不一样。
互联网是轻资产,而大模型是个烧钱的技术活,不仅需要顶尖的技术,还要有充足的资金。

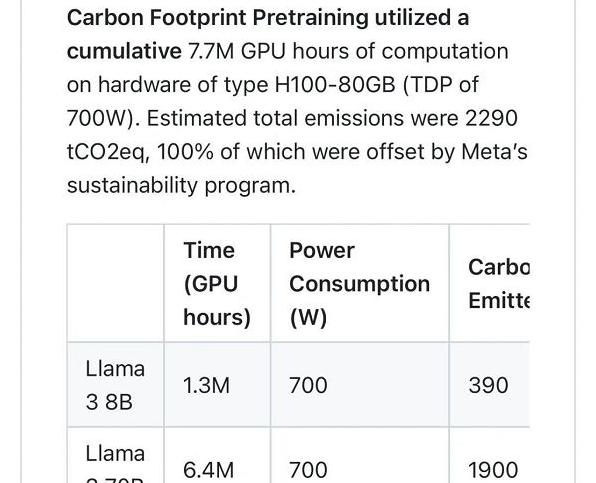
拿Meta的LLama3举个例子,训练它的8B和70B模型消耗了数百万个GPU训练时长,对小厂商而言,简直是难以想象。
结局如何呢?
大模型市场走到了瓶颈。
巨额的资金投入和技术要求,让许多科技小厂商望而却步。
特别是当DeepSeek在市场上以低成本和开源策略脱颖而出,大家终于意识到,这游戏不是谁都能玩的。
巨头之间的角逐既然入局的是巨头,那么他们都是怎么博弈的呢?
DeepSeek凭借开源战略和技术优势,一时间成为行业新标杆,而阿里的Qwen模型也在开发者之间拥有极高的口碑,深得技术流的青睐。
字节跳动的AI模型虽然不以技术见长,但其背靠强大的用户平台——抖音。

这个平台上的用户流量,为他们提供了巨大的优势。
2024年春,抖音一宣布接入豆包的AI能力,马上让豆包获得了大量用户。
这种有流量、有数据的优势,让其他AI厂商都自愧不如。
正是这种种因素,让李开复最终坚定地认为,未来的大模型市场会由DeepSeek、阿里和字节三分天下。
一个技术领先,一个资本雄厚,还有一个流量称王,这样的组合,不得不让人信服。
未来的AI市场:三足鼎立?
还是新变局?
到这里,朋友们可能心里还是会有个问号:未来是不是就真的会只有这三家了?
结局真的如此板上钉钉吗?
其实科技领域,变化是常态。
DeepSeek现在虽然强势,但也难保证不被后来居上。
阿里的技术策略、字节的流量优势,也都存在潜在的变数。
市场竞争,不可能永远一成不变。
重要的是,我们要看到技术发展带来的机遇,不管是巨头还是小厂商,只要能找到自己的优势,就有希望在市场中站稳脚跟。
未来谁会成为AI霸主,还需要时间的证明。
用李开复的一句话来结尾:“技术发展是没有终点的,竞争让我们不断进步。”希望这次关于大模型的讨论,能让大家对AI的未来有更多的思考,也期待更多有识之士,共同推动技术进步。

