R语言通常用于数据分析的一种开发语言,它通常被用在医疗、科研等多个领域的数据分析统计工作,除此之外Python也是常用的数据分析工具之一,著名的的数据分析三剑客Pandas、Numpy和Matplotlib撑起了目前的整个数据分析的半壁江山。Pandas就是我们今天的主角,它是有AQR Capital Management于2008年4月开发,并于2009年底开源出来的,属于PyData项目的一部分。Pandas最初被作为金融数据分析工具而开发出来的。
 安装使用和查看版本安装
安装使用和查看版本安装安装pandas是非常简单的一件事,因为Python为了实现万金油特性的功能特性,开发了包管理工具--pip,安装Pandas只需要执行一行命令即可。
pip install pandas查看版本import pandas as pdnp.__version__pandas的有哪些用途?pandas最主要的功能就是对分析数据前的准备功能,简单来说收集来的数据不是那么完善需要对数据进行清洗、去空、转换成可以使用的数据集,为此pandas提供了Series和DataFrame两种基本对象;由于pandas在Numpy基础上开发而来的,所以pandas结合Numpy可以用于基础的数据计算和统计工作。Series和DataFrameSeries并不是什么神奇的技术,你可以把它想象成一个一维数组。而DataFrame就是我们常使用的多维数组
Seriesimport pandas as pdpd.Series(data=["Red","Green","Yellow"],index=[5,6,1],name="Do you have a favourite colour?") 通过图表直观的展示出来import matplotlib.pyplot as pltimport pandas as pdseries = pd.Series(data=["Red","Green","Yellow"],index=[5,6,1],name="Do you have a favourite colour?")x = list(series.values)y = list(series.index) plt.plot(x,y)plt.title("Do you have a favourite colour?")plt.xlabel("x-axis")plt.xlabel("y-axis") plt.show()
通过图表直观的展示出来import matplotlib.pyplot as pltimport pandas as pdseries = pd.Series(data=["Red","Green","Yellow"],index=[5,6,1],name="Do you have a favourite colour?")x = list(series.values)y = list(series.index) plt.plot(x,y)plt.title("Do you have a favourite colour?")plt.xlabel("x-axis")plt.xlabel("y-axis") plt.show()
这种数据结构就是构建一个一维的数据结构,并不是很直观,如果需求发生了改变把序号改成具体人员名称,那么对于Series来说,就没办法实现了,就需要两个Series结合而来了,这样倒不如直接使用DataFrame方便的多。
DataFramepd.DataFrame(data={ "total":[5,6,1], "color":["green","red","yellow"]},index=[1,2,3])
数据统计分析的参数一般不可能只有一个也不能简单的以下标为主,因此在数据分析中DataFrame这种方式的数据处理方式是经常被用到的。
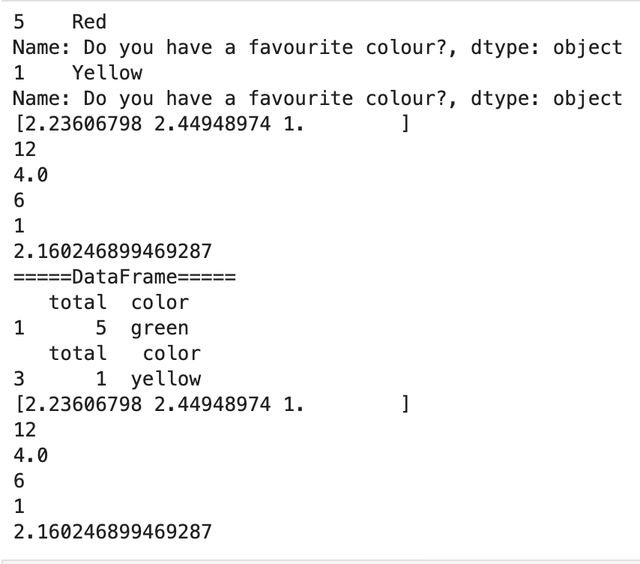
通过图表直观的展示出来import matplotlib.pyplot as pltimport pandas as pddf = pd.DataFrame(data={ "total":[5,6,1], "color":["green","red","yellow"]},index=[1,2,3])x = list(df.color)y = list(df.total) plt.plot(x,y)plt.title("Do you have a favourite colour?")plt.xlabel("x-axis")plt.xlabel("y-axis") plt.show() pandas的数据处理pandas结合numpy实现数据统计import pandas as pdimport numpy as npseries = pd.Series(data=["Red","Green","Yellow"],index=[5,6,1],name="Do you have a favourite colour?")series.loc[5] # 获取index的某行数据print(series.head(1)) # 获取前一行的数据print(series.tail(1)) # 获取后一行的数据num = list(series.index)print(np.sqrt(num)) # 计算num数值的平方根print(np.sum(num)) # 计算num的总和print(np.mean(num)) # 计算num的平均值print(np.max(num)) # 计算num的最大值print(np.min(num)) # 计算num的最小值print(np.std(num)) # 计算num的标准偏差print("=====DataFrame=====")df = pd.DataFrame(data={ "total":[5,6,1], "color":["green","red","yellow"]},index=[1,2,3])df.loc[1] # 获取index的某行数据print(df.head(1)) # 获取前一行的数据print(df.tail(1)) # 获取后一行的数据number = list(df.total)print(np.sqrt(number)) # 计算num数值的平方根print(np.sum(number)) # 计算num的总和print(np.mean(number)) # 计算num的平均值print(np.max(number)) # 计算num的最大值print(np.min(number)) # 计算num的最小值print(np.std(number)) # 计算num的标准偏差
pandas的数据处理pandas结合numpy实现数据统计import pandas as pdimport numpy as npseries = pd.Series(data=["Red","Green","Yellow"],index=[5,6,1],name="Do you have a favourite colour?")series.loc[5] # 获取index的某行数据print(series.head(1)) # 获取前一行的数据print(series.tail(1)) # 获取后一行的数据num = list(series.index)print(np.sqrt(num)) # 计算num数值的平方根print(np.sum(num)) # 计算num的总和print(np.mean(num)) # 计算num的平均值print(np.max(num)) # 计算num的最大值print(np.min(num)) # 计算num的最小值print(np.std(num)) # 计算num的标准偏差print("=====DataFrame=====")df = pd.DataFrame(data={ "total":[5,6,1], "color":["green","red","yellow"]},index=[1,2,3])df.loc[1] # 获取index的某行数据print(df.head(1)) # 获取前一行的数据print(df.tail(1)) # 获取后一行的数据number = list(df.total)print(np.sqrt(number)) # 计算num数值的平方根print(np.sum(number)) # 计算num的总和print(np.mean(number)) # 计算num的平均值print(np.max(number)) # 计算num的最大值print(np.min(number)) # 计算num的最小值print(np.std(number)) # 计算num的标准偏差