
参数高效微调技术应运而生,为科研人员和开发者提供了微调大模型的机会。
用 LoRA 微调 2.7B 参数的 blip2-opt 模型,提升图生文能力,带来高效的视觉语言对齐。
数据集和模型准备该虚拟数据集提供 6 位足球运动员的图像,附有详细文字说明,可用于微调图像描述模型。
访问数据集:huggingface.co/datasets/ybelkada/football-dataset

由 OPT-2.7B 训练的 BLIP-2 模型,包含三个强大组件:
* 视觉 Transformer:提取图像特征
* 语言模型:生成丰富描述
* 联合嵌入器:关联视觉和语言
此模型已在 Hugging Face 上提供,可通过以下链接下载:/huggingface.co/Salesforce/blip2-opt-2.7b
BLIP-2 简介BLIP-2 是一种多模态 AI 模型,凭借预训练优势,在视觉和语言任务上表现卓越。
该模型的架构包括一个图像编码器(提取视觉特征),一个大型语言模型(生成语言)和一个可学习的 Q-Former(融合视觉和语言表征)。
BLIP-2 融合了视觉和语言理解,提供强大的多模态能力。它的预训练机制降低了训练成本,提升了模型效果,使其在各种任务中大显身手。
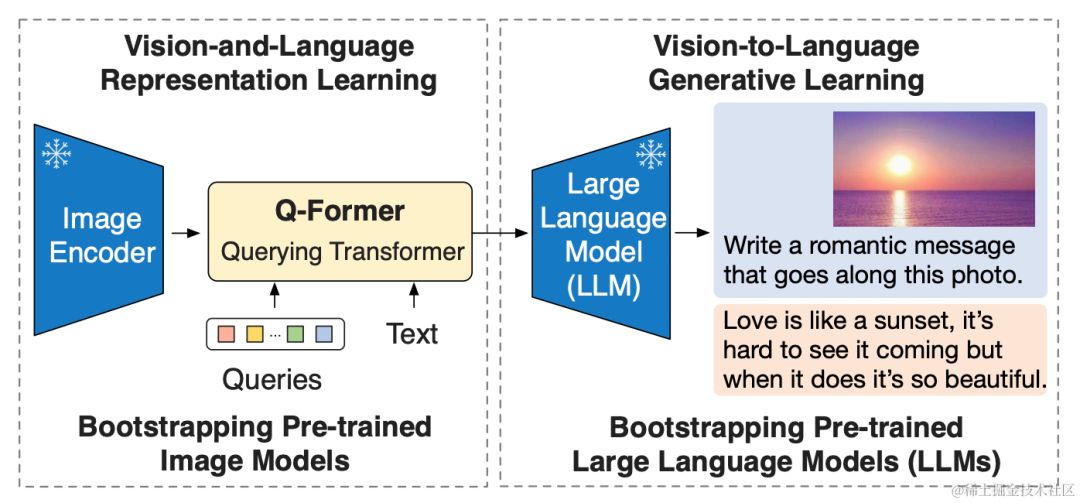

BLIP-2 使用了一种两阶段预训练方法,称为 Q-Former,以克服冻结预训练模型导致视觉和语言特征不一致的问题。在表示学习阶段,模型学习对齐视觉和文本特征的表示。接续的生成学习阶段利用这些表示来生成文本描述,从而加强跨模态对齐。
表示学习阶段
Q-Former模型创新性地将冻结的图像编码器连接到学习阶段,利用图像-文本对进行训练。通过优化预训练目标,该模型采用差异化的注意力掩码策略,控制图像和文本 Transformer 之间的交互。这种方法使 Q-Former 能够更有效地捕捉图像和文本之间的联系,从而在学习阶段取得卓越的性能。
生成学习阶段
Q-Former 通过连接到 LLM,利用其语言生成能力。预训练阶段中,全连接层将视觉表示投影到与 LLM 文本嵌入相同的维度,并将其添加到输入文本嵌入中。Q-Former 的预训练使其能够过滤视觉信息,提取与语言相关的关键特征,充当信息瓶颈。这简化了 LLM 学习视觉语言对齐,提高了模型效率。

先预先准备Processor、模型和图像输入。
from PIL import Image
import requests
from transformers import Blip2Processor, Blip2ForConditionalGeneration
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
model = Blip2ForConditionalGeneration.from_pretrained(
"Salesforce/blip2-opt-2.7b", load_in_8bit=True, device_map={"": 0}, torch_dtype=torch.float16
) # doctest: +IGNORE_RESULT
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
对于图像描述生成任务示例如下:
inputs = processor(images=image, return_tensors="pt").to(device, torch.float16)
generated_ids = model.generate(**inputs)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
print(generated_text)
# two cats laying on a couch
对于视觉问答任务(VQA)示例如下:
prompt = "Question: how many cats are there? Answer:"
inputs = processor(images=image, text=prompt, return_tensors="pt").to(device="cuda", dtype=torch.float16)
generated_ids = model.generate(**inputs)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
print(generated_text)
# two
LoRA 简介LoRA 技术巧妙利用低秩分解模拟模型参数变更,以极少参数量间接训练大模型。详细技术原理和实战教程请参考过往文章。
大模型参数高效微调技术原理综述(五)-LoRA、AdaLoRA、QLoRA大模型参数高效微调技术实战(五)-LoRA模型微调优化代码,改进精度!
我们的微调代码现可从 GitHub 的 llm-action 项目获取,具体位于 blip2_lora_int8_fine_tune.py 文件中。关键步骤包括:
- 将模型精度调整为 8 位整数。
- 微调模型以提升性能。
访问 GitHub 即可获取详细代码并提升您的模型表现。
第一步,加载预训练Blip-2模型以及processor。
from transformers import AutoModelForVision2Seq, AutoProcessor
# We load our model and processor using `transformers`
model = AutoModelForVision2Seq.from_pretrained(pretrain_model_path, load_in_8bit=True)
processor = AutoProcessor.from_pretrained(pretrain_model_path)
通过 LoRA 微调策略创建自定义配置,并利用 get_peft_model 方法扩展基础 Transformer 模型,提升微调性能,量化模型参数,优化模型大小。
from peft import LoraConfig, get_peft_model
# Let's define the LoraConfig
config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
)
# Get our peft model and print the number of trainable parameters
model = get_peft_model(model, config)
model.print_trainable_parameters()
第三步,进行模型微调。
# 设置优化器
optimizer = torch.optim.AdamW(model.parameters(), lr=5e-5)
device = "cuda" if torch.cuda.is_available() else "cpu"
model.train()
for epoch in range(11):
print("Epoch:", epoch)
for idx, batch in enumerate(train_dataloader):
input_ids = batch.pop("input_ids").to(device)
pixel_values = batch.pop("pixel_values").to(device, torch.float16)
outputs = model(input_ids=input_ids, pixel_values=pixel_values, labels=input_ids)
loss = outputs.loss
print("Loss:", loss.item())
loss.backward()
optimizer.step()
optimizer.zero_grad()
if idx % 10 == 0:
# 根据图像生成文本
generated_output = model.generate(pixel_values=pixel_values)
# 解码
print(processor.batch_decode(generated_output, skip_special_tokens=True))
最后,保存训练的Adapter模型权重及配置文件。
model.save_pretrained(peft_model_id)
模型推理使用 LLM-Action,轻松实现图生文!
只需运行 CUDA_VISIBLE_DEVICES=0 python blip2_lora_inference.py,即可使用先进的 LLM-Action 模型进行图生文,为您提供准确而有创意的文本描述。
代码详情请访问 GitHub 上的 llm-action 项目,了解 blip2_lora_inference.py 文件中的详细说明。
结语基于 LoRA 微调,优化 BLIP-2 多模态大模型的文本生成能力,提升文本流畅性和信息丰富度,助力文本创作提质增效。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-
