
01、DeepSeek爆火后的算力缺口
“服务器繁忙,请稍后再试。”——这或许是DeepSeek这段时间里最常收获的答案。
DeepSeek在春节期间由于产品更新迅速走红,用户量在短时间内飙增。根据统计,DeepSeek应用上线20天,日活跃用户数(DAU)已突破2000万。这种用户量的激增带来了巨大的算力需求,导致服务器资源紧张,DeepSeek不得不暂停API服务充值以优先保障现有用户的使用体验。

随后,DeepSeek对此发表声明称,“当前服务器资源紧张,为避免对您造成业务影响,我们已暂停API服务充值。存量充值金额可继续调用,敬请谅解!”此外,DeepSeek还提到,暂停充值是为了优先保障现有用户的使用体验,并非永久性决策。
DeepSeek的暂停充值消息一经发布,便引发了用户的担忧和讨论。
02、算力缺口会有多大
这个问题恐怕很难估计,毕竟算力可以通过购买、租赁动态解决,但我们却可以通过用户量和竞品估算DeepSeek对算力的需求量以及运营时需面对的成本压力。
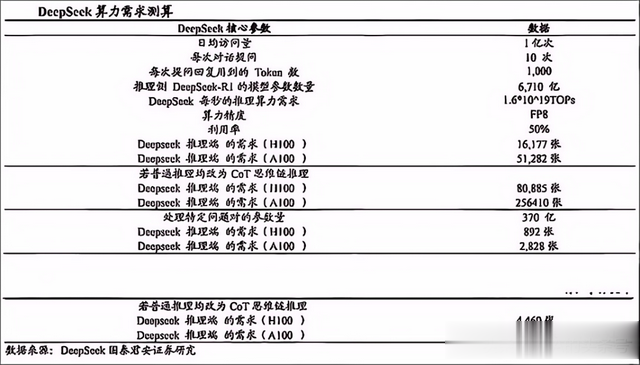
根据国泰君安证券分析师舒迪、李奇的测算,假设DeepSeek的日均访问量为1亿次、每次提问10次,每次提问的回复用到1000个token,1000个token大概对应750个英文字母,则DeepSeek每秒的推理算力需求为1.6×1019TOPs。在这种普通推理情境下, 假设DeepSeek采用的是FP8精度的H100卡做推理,利用率50%,那么推理端H100卡的需求为16177张,A100卡的需求为51282张。
DeepSeek有多少算力这个显然无法得知,但从“DeepSeek-V3模型在训练过程中使用了2048张H800 GPU,这些GPU的总计算能力为3.97 exaFLOPs(3.97百亿亿FLOPs)”“DeepSeek母公司幻方量化作为国内的私募资产管理巨头,早在2021年便储备了超过1万块英伟达A100/H100 GPU集群”等新闻线索中,可大致推测DeepSeek手上的算力。
成本方面则可以参考“前辈”豆包,机构预计豆包在2025年的MAU有望接近ChatGPT达到2亿,并针对这个用户量对豆包大模型算力需求(非字节全部业务算力需求)对应产业链各环节需求进行了测算。

豆包背后有字节跳动支持,DeepSeek作为一家初创企业,面对这样的成本,显然需要时间来获得融资和成长。
点评:DeepSeek-R1的惊艳之处是通过重新设计训练流程、以少量SFT数据+多轮强化学习的办法,在提高了模型准确性的同时,也显著降低了内存占用和计算开销。Deepseek-R1提供了一种低成本训练的方法,而不是说只能通过低成本来进行训练。从这个角度看,“成本创新”≠“削减算力”,DeepSeek强调的始终是“性价比”的训练路径,算法创新在AI大模型发展过程中的比重或话语权变重了而已。
03、多管齐下填补缺口
早期,DeepSeek主要依赖自建数据中心,与ChatGPT背后的微软Azure云服务相比,算力储备存在明显差距,其特殊模型架构(如MOE架构)在推理阶段需要更高算力,但上线前的优化准备不足,导致资源占用过高。

短期来看,DeepSeek联合云服务商(如华为昇腾云、腾讯云)提供算力支持等方式缓解压力是最快速有效的办法。华为云作为官方唯一合作伙伴,不仅提供大规模算力支持,还协助优化网络攻击防御和用户需求响应。
除了直接租赁算力外,DeepSeek可以与云服务商进行联合研发,针对DeepSeek的特定需求进行算力资源的优化和定制。这有助于提升算力资源的利用效率,同时降低算力成本。

而长远来看,技术突破才是解决算力缺口最有效的手段。DeepSeek可以与云服务商进行联合研发,DeepSeek可以与云服务商进行联合研发,借助云计算的弹性扩展能力,DeepSeek在用户访问激增时动态调配算力,从而实现针对DeepSeek的特定需求进行算力资源的优化和定制。
前不久,清华大学KVCache.AI团队联合趋境科技发布的KTransformers开源项目公布更新:一块24G显存的4090D就可以在本地运行DeepSeek-R1、V3的671B“满血版”。预处理速度最高达到286 tokens/s,推理生成速度最高能达到14 tokens/s。KTransformers的更新发布后,不少开发者也纷纷在自己的设备上进行测试。他们惊喜地发现,本地运行完全没有问题,显存消耗甚至比github里的技术文档中提到的还要少,实际内存占用约380G,显存占用约14G。
点评:从云计算到本地部署,相信多种途径并行一定可以解决DeepSeek算力缺口问题,而反过来,DeepSeek开源策略降低了云厂商的部署门槛,使其能够快速整合模型能力。金山云、优刻得等通过开源模型轻松部署“杀手级应用”,同时反哺DeepSeek的算力需求。国产算力厂商(如华为昇腾)与DeepSeek适配,最终推动“国产算力+国产大模型”的闭环生态,加速云计算国产化进程。
