【TechWeb】4月15日消息,OpenAI推出专为开发者打造的全新模型系列——GPT-4.1。该系列包含三个新成员:旗舰级GPT-4.1、高速的GPT-4.1 Mini,以及最小、最快、最经济的 GPT-4.1 Nano。
据介绍,GPT‑4.1系列模型在编码能力、复杂指令遵循、长文本处理(首次支持高达一百万 Token 上下文,且无额外费用)以及多模态理解方面均实现了显著提升,性能全面超越 GPT-4o,并在关键指标上比肩甚至超越 GPT-4.5。
值得注意的是,GPT-4.1系列仅通过 API 提供。
此前,OpenAI刚刚出台了一项针对未来新的大模型AIP调用的规定,要求AIP调用组织完成身份验证流程,才能解锁访问OpenAI平台最先进模型和功能。也就是说“不通过验证就不让用最新模型”。尽管OpenAI 的AIP组织验证支持200多个国家和地区,但中国大陆开发者仍面临资格限制。
另外,OpenAI史上最贵大模型将被“淘汰”。
OpenAI称,将在API中弃用GPT-4.5预览版,因为GPT-4.1在许多关键功能上提供了改进或相似的性能,且成本和延迟更低。GPT-4.5预览版将在三个月后,即2025年7月14日关闭,以便开发者有足够的时间进行过渡。
GPT-4.1三大模型
旗舰模型GPT‑4.1性能优化集中于编码、指令遵循、长文本理解上:
1、最强编码:GPT‑4.1在SWE-bench Verified上的得分为54.6%,比GPT‑4o提高了21.4个百分点,比GPT‑4.5提高了26.6个百分点。

2、指令遵循:在Scale的MultiChallenge上,GPT‑4.1的得分为38.3%,比GPT‑4o提高了10.5个百分点。

3、长上下文:在Video-MME上,GPT‑4.1取得了新的SOTA——在长视频、无字幕类别中得分72.0%,高于GPT-4o的65.3%。

GPT-4.1 mini 在小型模型性能方面取得了重大飞跃,甚至在许多基准测试中超越了 GPT-4o。它在智能评估中与 GPT-4o 相当或超过,同时将延迟减少了近一半,成本降低了 83%。
对于需要低延迟的任务,GPT-4.1 nano 是最快且最便宜的模型。它以其 100 万个标记的上下文窗口,在小型尺寸下提供卓越的性能,并在 MMLU 上得分 80.1%,在 GPQA 上得分 50.3%,在 Aider 多语言编码上得分 9.8%——甚至高于 GPT-4o mini。它非常适合分类或自动补全等任务。
API定价
GPT-4.1、GPT-4.1 mini 和 GPT-4.1 nano 现在对所有开发者开放,仅通过API提供。

价格方面,GPT‑4.1比GPT‑4o便宜26%,输入、输出分别是每百万token 2美元和8美元。
GPT‑4.1 nano是OpenAI迄今为止价格最低、速度最快的模型,输入、输出分别为0.1美元和0.4美元。
对于重复使用相同上下文的查询,这些新模型的提示词缓存折扣已从之前的50%提高至75%。
最后,长上下文请求已包含在标准的按Token计费内,无需额外费用。
今年2月,OpenAI发布了自己有史以来最贵的大模型GPT-4.5,GPT-4.5的API定价高达75美元/百万tokens输入、150美元/百万tokens输出,被开发者吐槽“用不起”!
这次GPT-4.1的价格,你觉得如何?
通过视频,OpenAI 团队成员介绍了GPT‑4.1系列模型模型的性能优势、基准测试结果,并通过实时演示,如现场编写功能完善的前端应用、处理超长日志文件等,展现了它们的实际能力。
一起看看:
编码能力显著优于 GPT-4o
GPT-4.1 在各种编码任务中显著优于 GPT-4o,包括主动解决编码任务、前端编码、减少不必要的编辑、可靠地遵循差异格式、确保一致的工具使用等。
在SWE-bench Verified(一个衡量现实世界软件工程技能的指标)上,GPT-4.1完成了54.6%的任务,而GPT-4o完成了33.2%(2024-11-20)。这反映了GPT-4.1模型在探索代码库、完成任务以及生成既可运行又可通过测试的代码方面的能力提升。

对于希望编辑大型文件的API开发者来说,GPT-4.1在多种格式下的代码差异方面更加可靠。Aider的多语言差异基准测试中,GPT-4.1的成绩是GPT-4o的两倍多,并且甚至比GPT-4.5高出8个百分点。
GPT-4.1专门训练以更可靠地遵循diff格式,这使得开发者只需让模型输出更改的行,而不是重写整个文件,从而节省成本和延迟。
对于喜欢重写整个文件的开发者,GPT-4.1的输出token限制提高到了32,768个(相比GPT-4o的16,384个tokens有所增加)。

GPT-4.1 在前端编码方面也显著优于 GPT-4o,能够创建功能更强大、外观更美观的网页应用。在对比测试中,评分人员80%的时间更喜欢 GPT-4.1生成的网站,而不是 GPT-4o生成的网站。
除了上述基准测试之外,GPT-4.1 在更可靠地遵循格式方面表现更佳,并且更少进行不必要的编辑。在OpenAI内部评估中,代码中的不必要的编辑从 GPT-4o 的 9% 降至 GPT-4.1 的 2%。
指令遵循
GPT-4.1 更可靠地遵循指令,我们在各种指令遵循评估中测量到了显著的改进。GPT-4.1在困难提示方面的表现相较于GPT-4o有了显著提升。
多轮指令跟随对于许多开发者来说至关重要——模型需要能够在对话的深层保持连贯性,并跟踪用户之前告诉它的信息。OpenAI训练了GPT-4.1,使其能够更好地从对话中的过去消息中提取信息,从而实现更自然的对话。
在Scale的MultiChallenge基准测试中GPT‑4.1虽然不及o1和GPT-4.5,但已经可以追上o3-mini,并且比GPT‑4o提升了10.5个百分点之多。
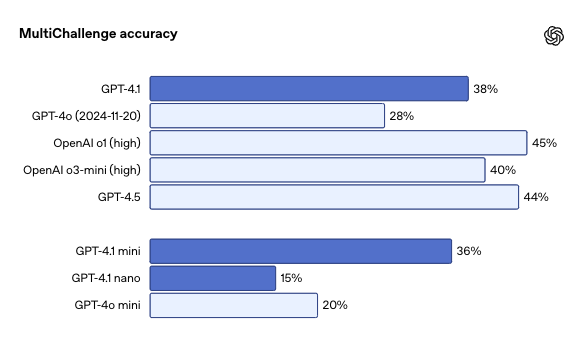
GPT-4.1在IFEval上的得分也为87.4%,而GPT-4o的得分为81.0%。IFEval使用带有可验证指令的提示(例如,指定内容长度或避免某些术语或格式)。

长文本
GPT-4.1、GPT-4.1 mini 和 GPT-4.1 nano 可以处理多达 100 万个上下文标记——比之前的 GPT-4o 模型多 128,000 个,非常适合处理大型代码库或大量长文档。
OpenAI展示了GPT-4.1在上下文窗口内不同位置检索一条隐藏的少量信息(即一根 “针”)的能力,也就是“大海捞针”的能力。
OpenAI还发布了用于评估多跳长上下文推理的数据集Graphwalks。这是因为,许多需要长上下文的开发者用例需要在上下文中进行多个逻辑跳跃,例如在编写代码时在多个文件之间跳转,或者在回答复杂的法律问题时交叉引用文档等。
Graphwalks需要模型跨上下文多个位置进行推理,其使用由十六进制散列组成的定向图填充上下文窗口,然后要求模型从图中的一个随机节点开始进行广度优先搜索(BFS),然后要求它返回一定深度的所有节点。
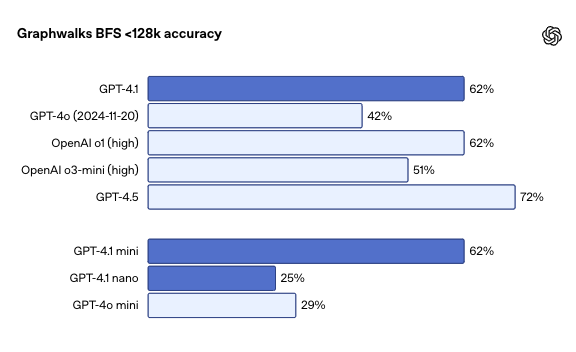
GPT-4.1在上下文长度达到128K个token时优于GPT-4o。
