前言:本文教你在本地电脑上使用LLama3+ComfyUI+OpenWebUI搭建一个多模态AI会话助理,轻松使用AI生成图象。
Llama3:Meta Llama 3是由Meta开发并开源的一系列新型模型,具有8B和70B两种参数大小(预训练或指令调整)。
Llama 3指令调优模型针对对话/聊天用例进行了微调和优化,在通用基准测试中优于许多可用的开源聊天模型。
Comfy UI:一个开源强大、模块化的Stable Diffusion GUI后端。Comfy UI将允许用户基于图形/节点/流程图的界面设计和执行高级Stable Diffusion Pipeline流程生成图片。
Open Web UI:一个开源的、可扩展、功能丰富、用户友好的自托管Web UI,可以完全离线运行。它支持在本地电脑各种LLM大模型,包括与Ollama和ApenAI兼容的API。

一、Window环境配置
PC配置:Windows 10 专业版,版本22H2;32G RAM ;NVIDIA GeForce CTX1060 6GB;

二、安装Llama LLM环境
下载OllamaSetup地址:https://ollama.com/download
本地双击安装Ollama环境:OllamaSetup.exe
安装Llama3(phi3安装类似)
ollama run llama3ollama run phi3安装完后可以测试:which country is the bigest in the world?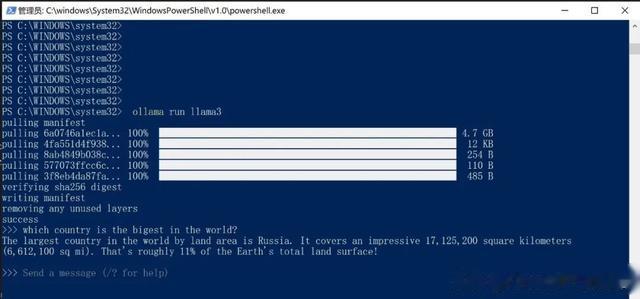
三、安装Comfy UI绘图环境
3.1 工具下载
源码开源的地址:https://github.com/comfyanonymous/ComfyUI
Window建议使用一键安装包:https://github.com/comfyanonymous/ComfyUI/release
说明:一键安装包Windows独立构建应该可以在Nvidia gpu上运行,不需要配置虚拟环境,直接下载就可以运行:
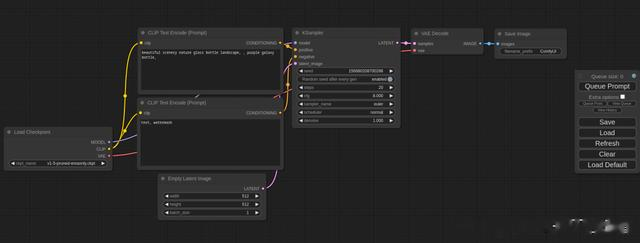
cd ComfyUI_windows_portableComfyUI_windows_portable>run_nvidia_gpu.bat浏览器打开:http://127.0.0.1:8188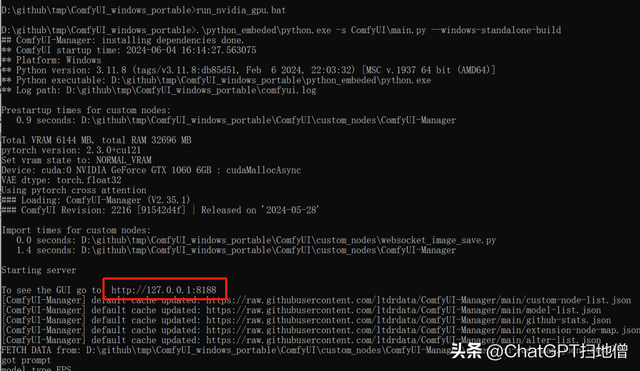
3.2下载模型checkpoints
模型放置位置:ComfyUI_windows_portable\ComfyUI\models\checkpoints
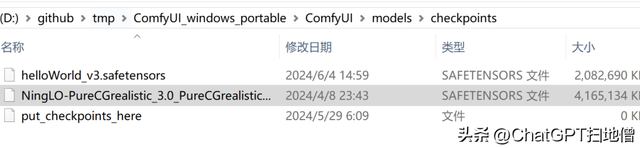
ComfyUI也可以和另外的绘图UI软件(比如Stable Diffusion)共享模型,配置方法如下:
#comfyui:# base_path: path/to/comfyui/# checkpoints: models/checkpoints/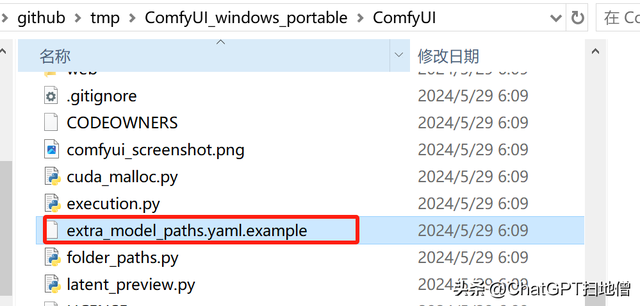
3.3安装ComfyUIManager
cd \ComfyUI\custom_nodesgit clone https://github.com/ltdrdata/ComfyUI-Manager.git安装完成之后重启ComfyUI:ComfyUI_windows_portable>run_nvidia_gpu.bat
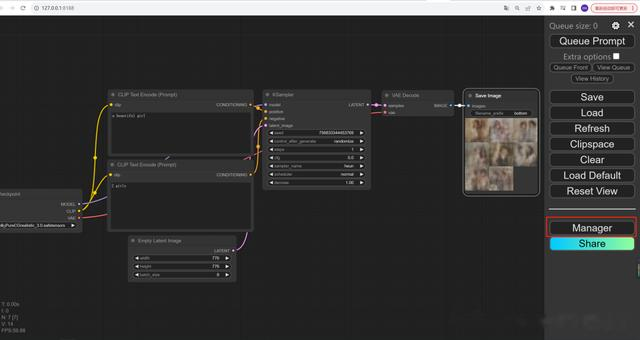
四、安装Open WebUI
源码地址:https://github.com/open-webui/open-webui
目前安装方式有两种,下面我们介绍两种方式的安装方法。
4.1方式1-在conda环境中安装
环境需求:python=3.11+nodejs=20.12.2
https://docs.openwebui.com/# 安装环境conda create --name openwebui python=3.11conda activate openwebuiconda install conda-forge::nodejs#克隆代码git clone https://github.com/open-webui/open-we...cd open-webui/#配置OPENAI_API_KEY等Copying required .env fileChange the .env.example to .envBuilding Frontend Using Nodenpm inpm run buildServing Frontend with the Backendcd ./backendpip install -r requirements.txt -Ustart_windows.bat --listen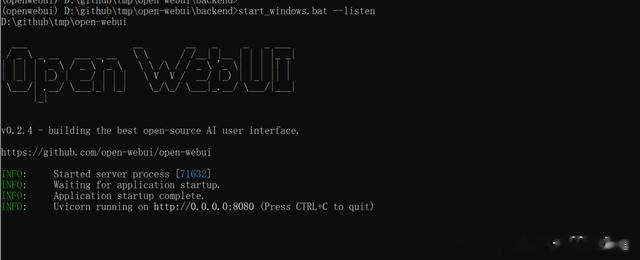
安装成功之后可以在浏览器中访问OpenWebUI: http://localhost:8080/

4.2方式2-在docker环境中安装
OpenWebUI可以用如下一键启动命令
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main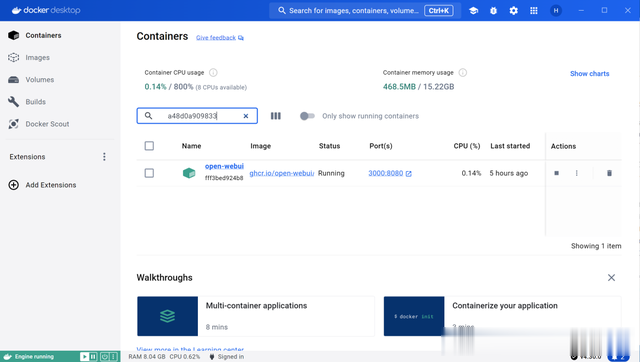
运行成功之后可以在浏览器中访问本地的OpenWebUI: http://localhost:3000/
五、配置Open WebUI
5.1 配置Llama3 模型-Ollama API
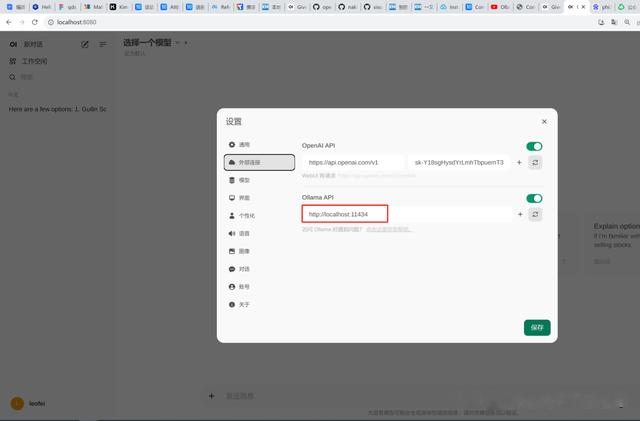
5.1 配置Llama3 关联ComfyUI
http://127.0.0.1:8188模型选择:helloWorld_v3.safetensors (可以下载自己喜欢风格模型)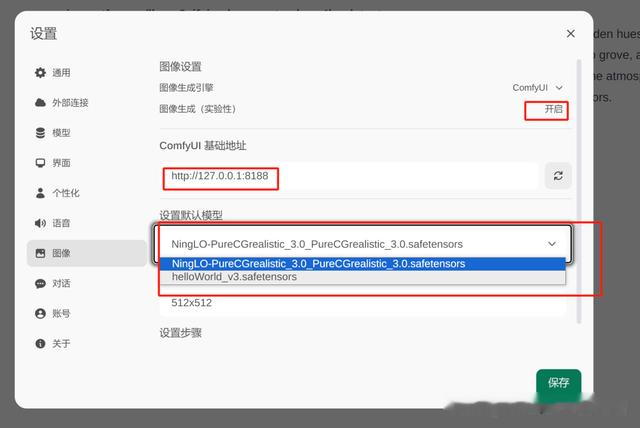
六、配置Open WebUI
6.1 使用llama3的SD微调模型绘图
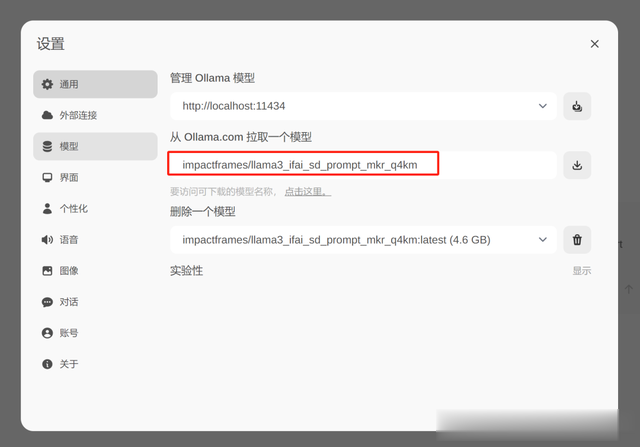
在OpenWebUI的设置界面,输入模型名字,这次使用llama3的Stale Diffusion微调模型(impactframes/llama3_ifai_sd_prompt_mkr_q4km)该模型的链接如下:https://ollama.com/impactframes/llama3_ifai_sd_prompt_mkr_q4km
在OpenWebUI的设置-->模型界面,输入模型名称点击下载按钮,下载过程十分钟左右,如下图:
 在OpenWebUI里边新建一个聊天,模型选择"impactframes/llama3_ifai_sd_prompt_mkr_q4km",在输入框中输入:桂林山水画,OpenWebUI就会返回画图的提示词,然后点击画图按钮,这个提示词就会调用后端的ComfyUI进行画图。如下图所示:
在OpenWebUI里边新建一个聊天,模型选择"impactframes/llama3_ifai_sd_prompt_mkr_q4km",在输入框中输入:桂林山水画,OpenWebUI就会返回画图的提示词,然后点击画图按钮,这个提示词就会调用后端的ComfyUI进行画图。如下图所示: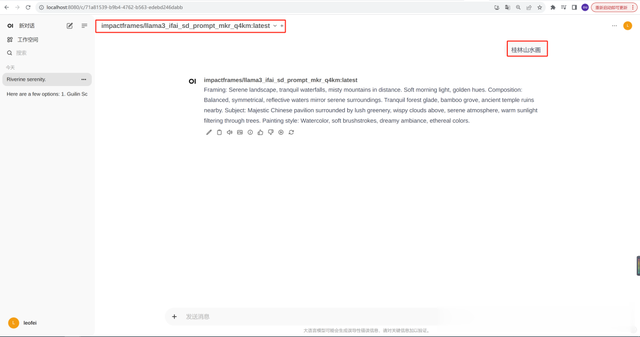
点击图象图标,可以看到ComfyUI生图进度情况。
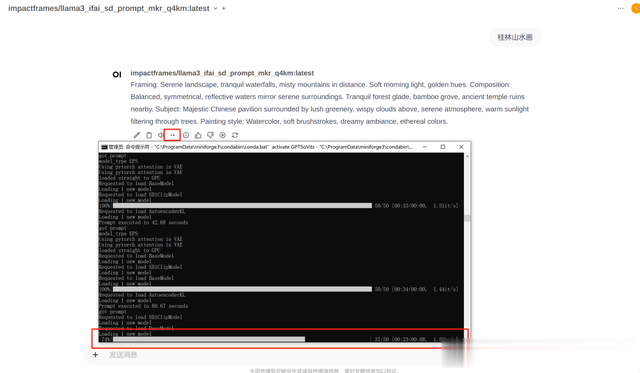
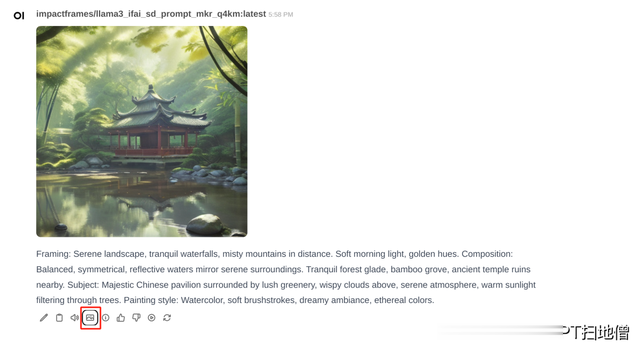
生成结果如下:
6.2 使用提示词指令方式安装
这种方式不需要使用为画图单独微调的llama3模型,可以使用任何模型(以下示例中我用了llama3:latest模型),使用指令提示词的功能即可实现,这样的好处就是可以同时和模型聊天和画图。
登录网址:https://openwebui.com/p/gaborkukucska/image

登录之后:点击Get按钮->Import to webUI就可以把提示词插件安装到本地的UI, 如下图所示:
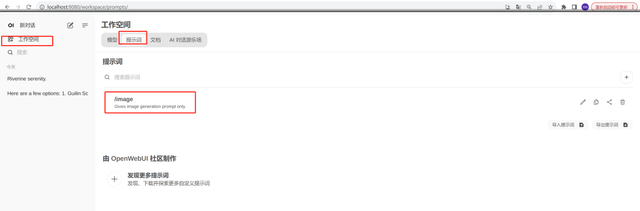
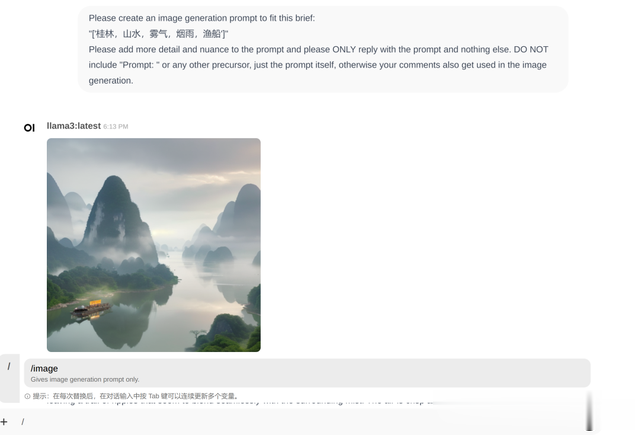
使用方法:在新建聊天中输入所建的提示词指令,例如刚才新建的/image, 如下图,输入提示词就可以直接生成图象。


生成结果:
七、总结
优势:
用户友好的界面:该工具提供了一个简洁直观的用户界面,使得用户可以轻松上手。多功能集成:它巧妙地结合了语言模型聊天和绘图功能,使得用户能够以低成本快速验证绘图想法。上下文保持:在聊天界面中绘图时,系统能够很好地保存对话上下文,包括图片和提示词等,这有助于维持连贯性。自然语言支持:用户可以使用中文进行绘图,简化了绘图流程,避免了复杂的提示词工程。不足:
集成深度有限:尽管与comfyui的集成提供了基础功能,但目前还不能自定义工作流程,限制了实现更高分辨率图像、使用特定模型(如lora)以及充分利用comfyui生态系统的能力。功能限制:与市场上其他高级绘图工具相比,如midjourney或dalle3,该工具在绘图能力上可能存在差距。总结:
两种模式各有其适用场景:第一种模式适合那些专注于绘图、追求一键生成图像的用户;第二种模式则适合在聊天中需要绘图功能,并且希望与模型进行交互以迭代绘图提示的用户。使用自然语言和中文进行绘图提供了一种新颖且便捷的体验。为了获得更高质量的图像,建议使用一些优质的sdxl模型。虽然该工具在某些方面可能不如市场上的领先产品,但它的便利性和易用性仍然为特定用户群体提供了价值。
通过这种方式,我们保留了原文的主要观点,同时以更清晰和客观的方式呈现了信息。
敲码不易,欢迎点赞和转发!
