
生成式 AI 加速发展,GPT-5 等模型变革行业,赋能 AI 软件工程师。AI 技术的进步对国家竞争和个人职业道路至关重要。把握机遇,迎接 AI 时代。
最近有两则新闻:
GPT-5重大升级,不容小觑!OpenAI CEO萨姆·阿尔特曼预告,GPT-5将带来颠覆性的提升,任何轻视它的企业都将面临碾压。此外,阿尔特曼暗示 OpenAI将于今年推出改变历史的产品。准备好迎接由GPT-5开启的新时代吧!人工智能 (AI) 软件工程师横空出世,表现不俗。具备全面规划、DevOps 和全项目扫描能力,其表现已接近真正的程序员。虽然一切都在意料之中,但是还是感觉来得快了点。
个人觉得,当前AI技术的进展,未来 2-5 年,AI 将颠覆生产模式,个人饭碗面临革命。为避免降维打击,码农应积极学习 AI 底层原理或参与 AI 实践。把握 AI 趋势,把握机遇,方能立于不败之地。
打破 AI 黑盒迷思
AI 并非不可理解的“黑盒”,其运作机制可通过确定的程序员友好方式解释。
本篇文章将深入浅出地阐述 AI 原理,包括神经网络和深度学习,涵盖以下三个关键部分:
通过一个非常简单的网络解释神经网络和深度学习的基本原理。再通过一个真实的神经网络实操给大家一些体感。最后通过一个常见问题引出后面文章要介绍的复杂神经网络。神经网络基本原理
本章重点提示:
神经网络通过“学习”并存储训练集的一般规律,来解决训练集外的问题。神经网络以其参数的形式存储知识。每个神经元具有 N+1 个参数(N 为输入数量),这些参数共同编码着学习到的规律。多层神经网络中的众多神经元共同构建了一个记忆库,存储着复杂且抽象的知识。神经网络的学习过程是一种确定性优化,通过逐步调整参数寻找损失最低的点。模型编译时,每个神经元每个参数的调整公式由偏导数的传递性唯一确定。因此,只要优化算法确定,学习过程就具有确定性。
▐ 神经网络能做什么▐ 为什么神经网络能解决复杂问题复杂问题无法穷尽,因此没有一刀切的解决方案。关键在于抽象出它们的通用模式。这些模式揭示了这些问题的内在结构,从而为制定解决问题的有效策略奠定基础。
文本嵌入是一种利用向量记录单个单词或标记的模式,而不是记录所有可能的文本组合。这允许机器学习模型理解单词之间的相似性和关系。
每个向量的值代表语言元数据,描述单词的特征。通过比较向量的相似性,模型可以推断单词在特定上下文中共享的特征,从而增强自然语言处理任务的性能。
假设经过训练,得到king的向量表征是[0.3, 0.5, ..., 0.9],queen是[0.8, 0.5, ..., 0.2],prince是[0.3, 0.7, ..., 0.5],在某一个上下文中,比如 xx is ruling the kingdom,xx可以被king或者queen填充,那它们有可能就是由向量的第2个元素,那个共同的0.5决定的,在另一个上下文,比如 xx is a man,xx可以king或者prince填充,这有可能是由第一个元素决定的。
神经网络通过抽象模式计算和存储复杂信息,使其擅长解决涉及抽象概念的难题,有效处理高达 80% 的图像识别任务。
▐ 神经网络如何实现就像我上面说过的,AI不是黑盒。神经网络和一般程序一样,也是由数据和计算构成,并且它的存储和计算都是非常确定的。
举个例子,我们要解决一个通过x推导y的线性回归问题。观察到x=1时y=3,x=2时y=5,现在要求x=3时y=多少。问题本身比较简单,我们甚至可以直接算出回归方程式为y = mx + b,其中m = 2, b = 1。(线性回归链接:http://www.stat.yale.edu/Courses/1997-98/101/linreg.htm)
问题是,如果我们通过一个单一输入是x、只有一层、该层只有一个神经元、神经元的输出是y的神经网络,会以怎样的方式和过程来“学出”这个结果呢?
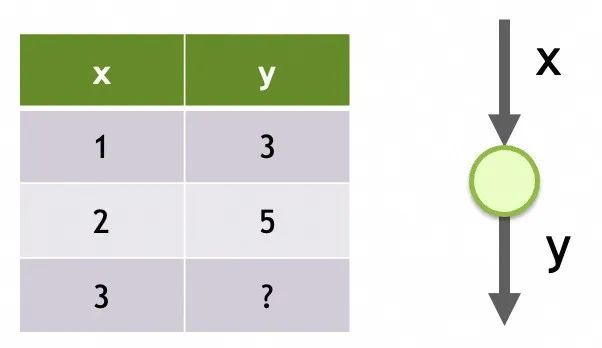
网络1
神经网络的存储结构在了解“学习”过程前,我们先来看看神经网络的存储结构,即什么是模型(model)。
上面的[网络1],它的模型就是由它的结构+它的参数组成。
它的结构是单个输入、只有一层、这层只有一个神经元。
它的参数就是每个神经元上被训练的数据,这里只有一个神经元,它上面有m和b两个参数。
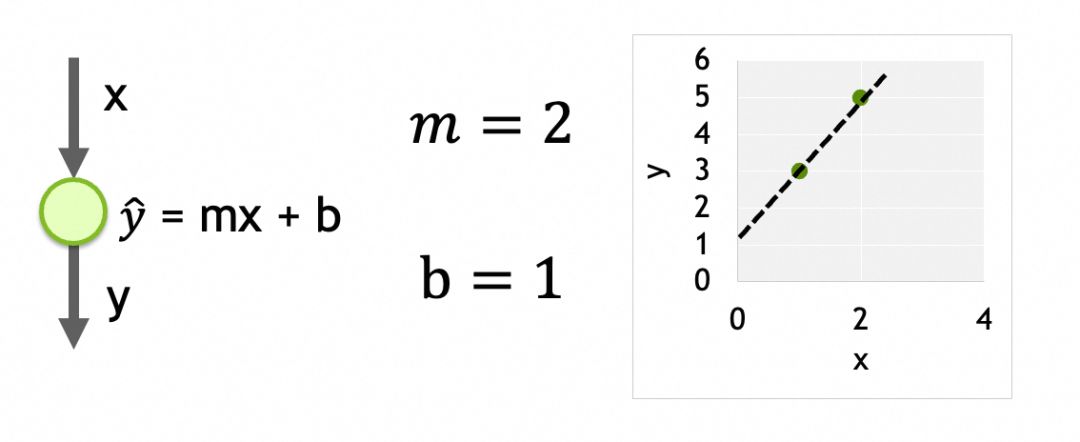
一个各层紧密相连(Dense)的网络,每个节点都和上一层所有节点相连,上层所有节点是下层每个节点的输入。每个节点的输出是其输入的加权和,经过激活函数处理后的结果:output = activation_function(W * X + b),其中,X是输入向量[x1, x2, ..., xn],W是各输入的权重(weights)向量[w1, w2, ..., wn],b是偏置(bias)常量,activation_function是激活函数。当激活函数是linear时,output = W * X + b。当节点有n个输入时,节点有[w1, w2, ..., wn, b]共n+1个参数。网络不同层之间是链的关系,结果会向下传递,直到最后一层输出层。任意层的任意一个神经元的任意一个参数,都会影响最终结果。所以这些参数就是神经网络的存储单元,用来存储抽象出来的模式。
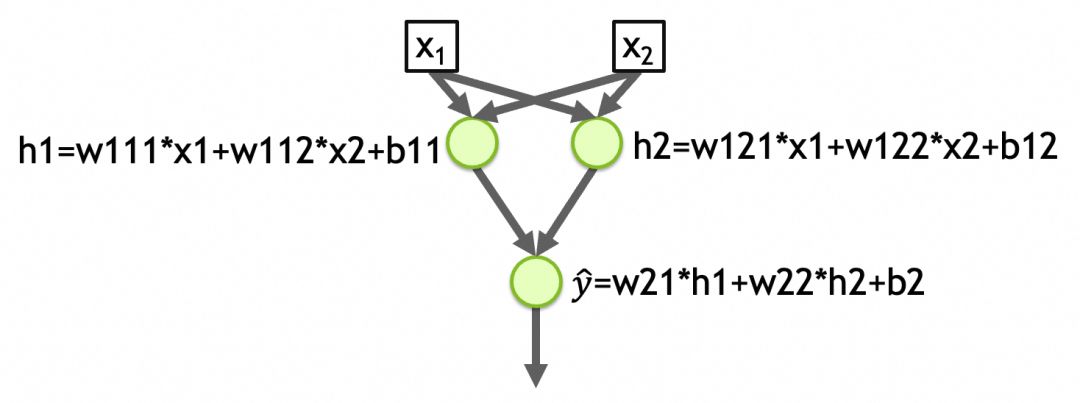
该网络拥有两个输入、两层结构,第一层具有 2 个神经元,第二层具有 1 个神经元。所有层的激活函数均为线性。
网络参数总数:
* 第一层:6 个(2 个输入 + 1 个偏置 x 2 个神经元)
* 第二层:3 个(2 个第一层神经元 + 1 个偏置 x 1 个神经元)
总计:9 个参数
这些参数捕获了网络所学习的模式,存储于 w111、w112、b11、w121、w122、b12、w21、w22 和 b2 中。
为什么要有激活函数(activation function)?我们可以看看如果没有特殊的激活函数,比如上面的[网络2],会是什么情况。
可以看到[网络2]每一层都是线性函数,根据线性函数的传导性,最终结果还是一个线性函数。即y_hat=w21*h1+w22*h2+b2=w21*(w111*x1+w112*x2+b11)+w22*(w121*x1+w122*x2+b12)+b2最终可以化简为y_hat=w1'*x1+w2'*x2+b'。而一个线性函数(直线、平面、…)是没法拟合/抽象现实问题的复杂度的。
引入激活函数,主要是为了引入非线性函数,让模型可以拟合/抽象复杂现实问题。

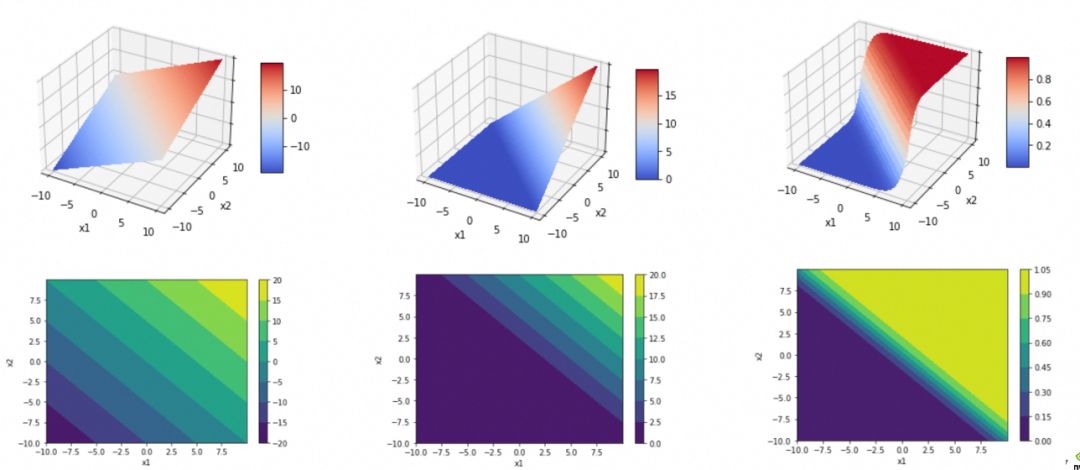
其中,ReLU用于消除负值,Sigmoid用于增加弧度。
深度学习过程拿上面的[网络1]举例。假设模型已按[网络1]创建,数据集已准备,分为训练集(training)比如 x=[1,2], y=[3,5] 和验证集(validation)比如 x=[3], y=[7]。
深度学习即神经网络训练步骤:
第1步、初始化参数:这里只有一个神经元,m和b两个参数。随机给值就行,假设m=-1,b=5。

第3步、使用损失函数评估输出的好坏(和实际值的差异),这里采用MSE(平均方差):
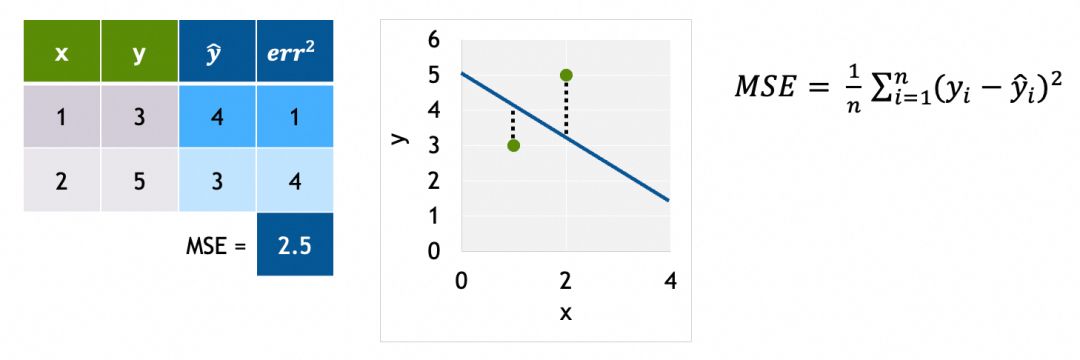
第4步、通过反向传播算法计算各参数的梯度(gradient)。
通过计算参数梯度,我们了解每个参数对损失函数的影响程度。利用梯度信息,我们可以调整参数以最小化损失,从而在复杂的参数空间中找到损失最小值,实现模型的优化。
为了计算梯度,我们需要先了解损失曲面。
利用参数 m 和 b 作为坐标轴,并以损失函数结果为深度轴,可绘制损失曲面。即使参数数量增加,形成多维参数空间,这一概念仍然适用。
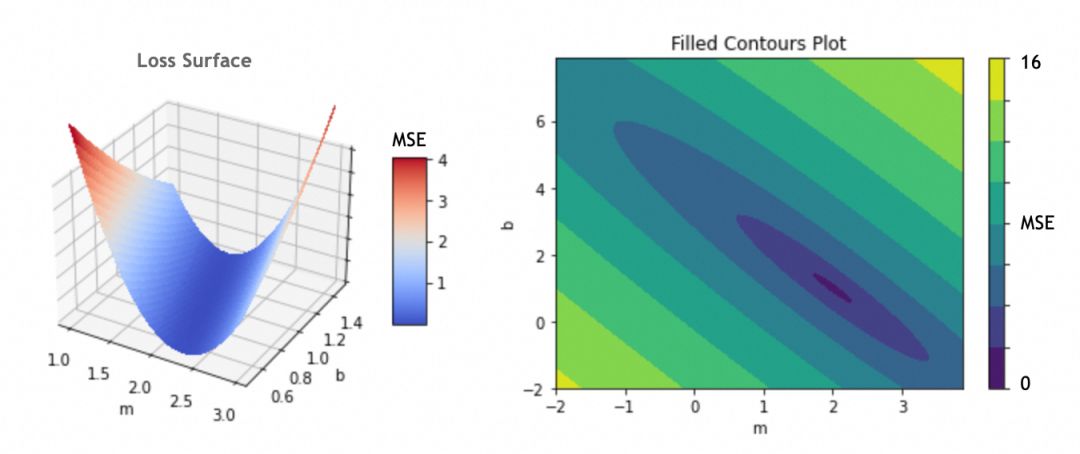
通过最小化损失函数,我们确定了最优参数:m = 2 和 b = 1。我们采用渐进式偏移法,将初始参数 (m = -1,b = 5) 分步调整至最优值。
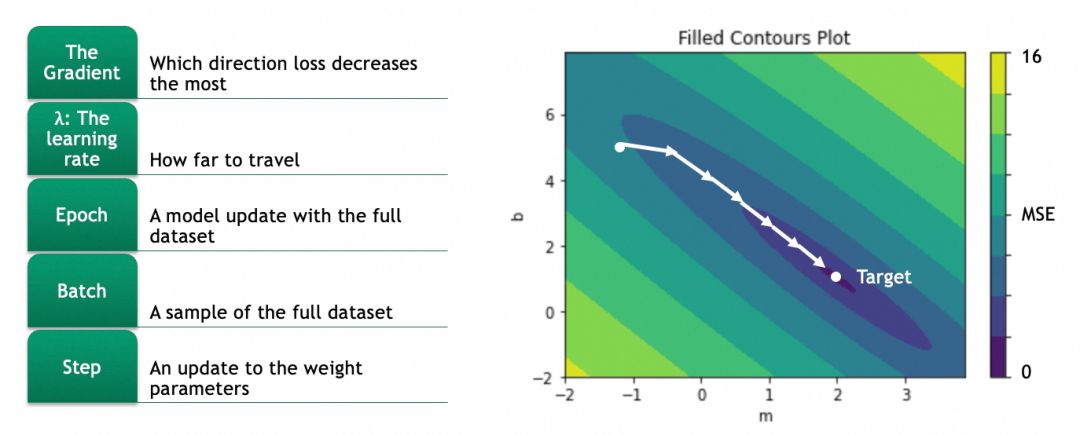
偏移具体怎么算呢?这就涉及到计算梯度,数学上就是计算偏导数。
优化曲面移动:计算当前位置的梯度,即各个方向(x 和 y)的偏导数。这反映了参数变化对损失结果影响的程度。梯度指示了最陡峭的下坡方向,调整参数以沿着此方向移动可以有效降低损失。
幸运的是,任何损失函数都有计算参数偏导数的公式。例如,激活函数为 y_hat = mx + b,损失函数为 L = (1/N) * Σ(y - y_hat)^2,则偏导数为:
∂L/∂m = (1/N) * Σ -2x(y - (mx + b))
无需手动计算这些偏导数,模型会自动提供。
神经网络的传导性使其能够通过反向传播更新参数。例如,在网络 2 中,通过逐层计算偏导数,我们可以获取第一层参数 w111 的梯度:∂L/∂w111 = ∂L/∂y_hat * ∂y_hat/∂h1 * ∂h1/∂w111。
第5步、按梯度更新各参数:
因为偏导数是向上的,往低处走、梯度下降要取反。
拿m举例,m的新值m = m - learning_rate * ∂L/∂m。
优化学习率至关重要,过高可能导致错过最优值,过低则训练时间过长。大多数模型提供自动调节算法,无需手动调整。
通过迭代训练,神经网络不断调整其参数,优化其表现。每个训练周期(epoch)利用梯度下降,逐步改进网络,直至达到最佳状态或满足停止条件。
在每个训练周期中,利用训练集训练模型,并使用验证集验证其性能。通过比较训练集和验证集的结果,可识别过拟合现象,即模型在训练集上表现良好,但在新数据(验证集)上无法泛化。
关于全局最优解和局部最优解:
复杂损失曲面可能存在多个局部极小值,渐进式移动算法可能陷入局部最优。因此,使用全局优化技术至关重要,以找到最佳解决方案,避免局部最优陷阱。
训练批次优化
当训练集庞大时,为了减轻计算负担,训练通常采用分批进行。常见的批次训练方法:
* 随机梯度下降 (SGD):每次仅选择一个样本进行训练。优点:计算量小,易跳出局部最优;缺点:波动大。
* 小批量梯度下降:每次选择 10 至数百个样本进行训练。优点:兼具 SGD 的优势和更高的稳定性,广泛应用。
MNIST数据集深度学习案例

探索深度学习的核心原理,了解神经网络的运作机制、模型训练和评估。本文将深入浅出地解释关键概念,无需复杂的技术细节。
加载和观察数据集深度学习图像模型训练和验证需要图像数据集 (X) 和标签 (Y)。MNIST 数据集被分成四个部分:
* 训练集 (X1, Y1)
* 验证集 (X2, Y2)
* 测试集 (X3, Y3)
* 保留集 (X4, Y4)
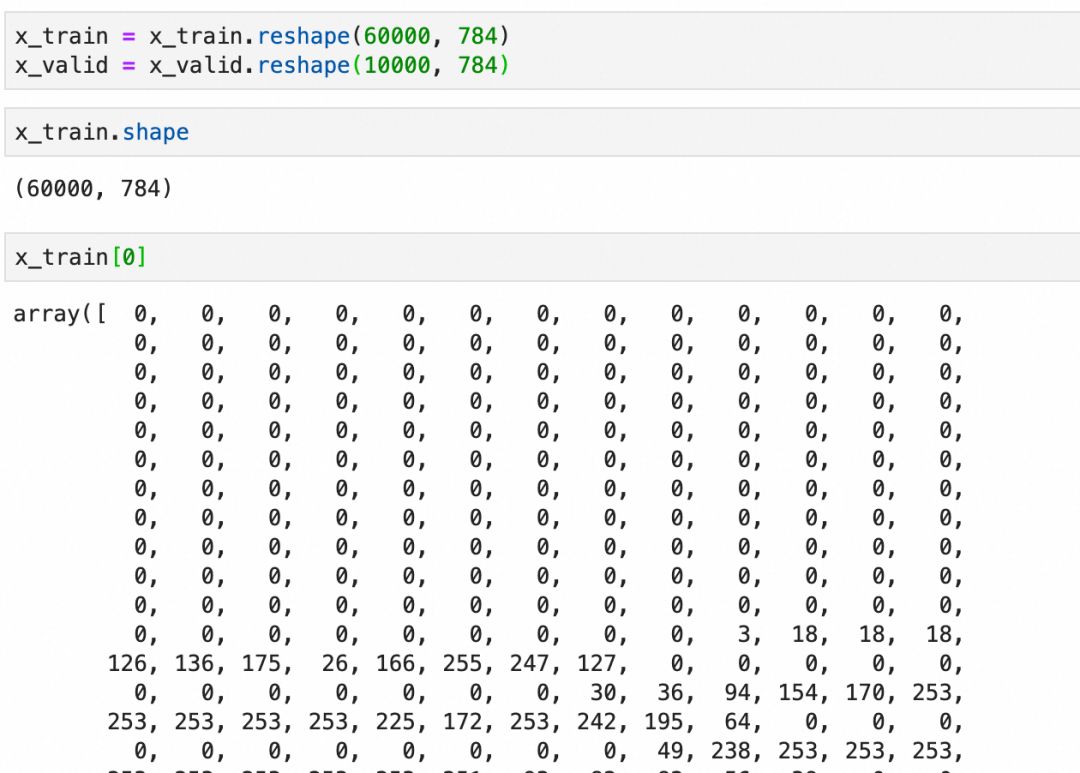
x_train:用于训练神经网络的图像y_train:x_train图像的正确标签,用于评估模型在训练过程中的预测结果x_valid:模型训练完成后用于验证模型表现的图像y_valid:x_valid图像的正确标签,用于评估模型训练后的预测结果了解数据是机器学习的关键第一步。使用 Keras API 加载数据集,洞察其概貌,建立数据理解的基础。

查看训练图像集(60,000 张)和验证图像集(10,000 张):
- 灰阶图像 (0-255)
- 分辨率:28x28 像素
每个图像是一个图像grid的二维数组,下图是二维数组的内容和可视化图像:


标签y_train比较简单,就是图像对应的数字:

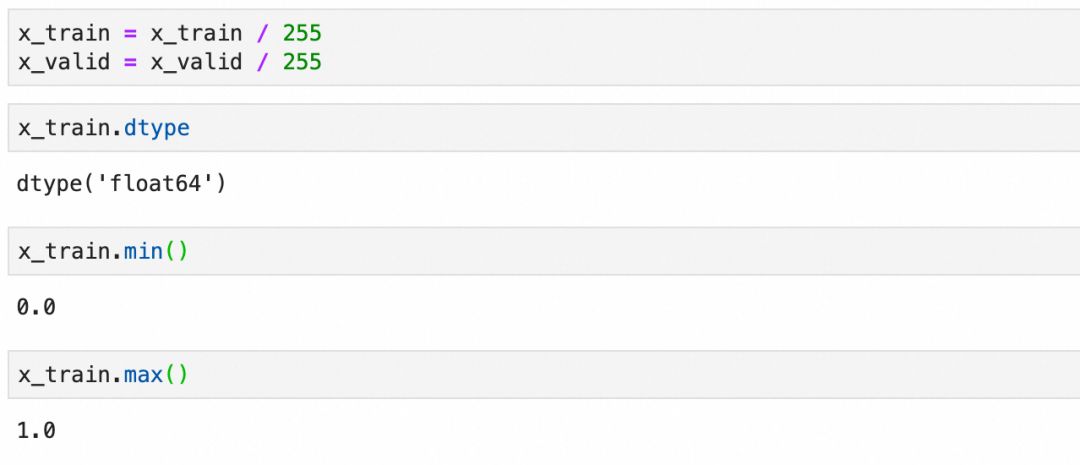
预加工数据集
神经网络数据预处理至关重要,包括:
- 展平图像为一维向量
- 将像素归一化至 0-1 范围
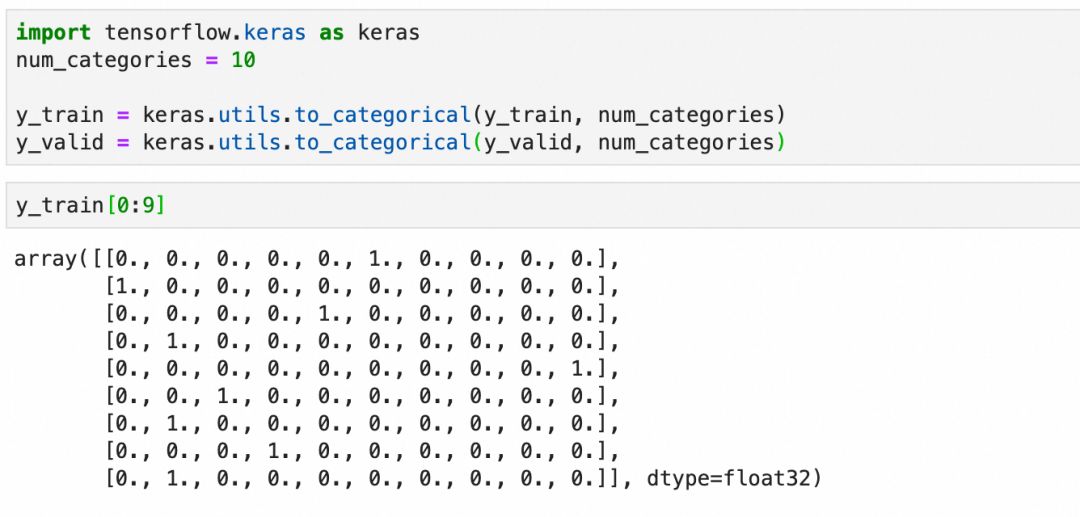
- 转换标签为 one-hot 编码,适用于分类任务
展平:
标准化:
one-hot 编码是深度学习中处理分类问题输出的有效方法。它将每个分类表示为一个一维向量,其中所属分类的值为 1,其他分类的值为 0。
即使标签是连续整数,也不应将其视为数值问题,因为分类本质上是离散的。one-hot 编码提供了将分类信息清晰且高效地编码到深度学习模型中的方法。


Softmax 激活函数用于多类分类。它将输出层值转换为概率分布,其中每个值的总和为 1。这使得每个输出可以解释为属于特定类别的概率。例如,[0.9, 0.0, 0.1, ..., 0.0] 表示 90% 的概率属于第 1 类,10% 的概率属于第 3 类。
按此创建模型并查看摘要:

可以注意这里的参数数量。
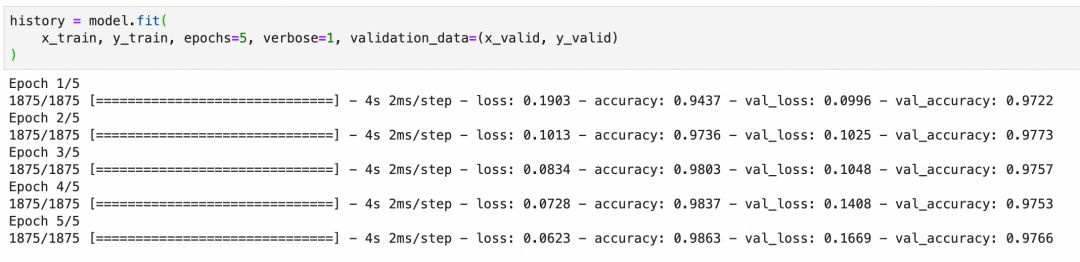
编译模型训练模型时,损失函数和优化器至关重要。多分类问题中,交叉熵损失函数有效衡量预测分布与实际分布之间的偏差。当预测正确时,损失为 0;当预测错误时,损失接近正无穷大,惩罚错误猜测。而优化器通过调整网络参数来最小化损失,不断提升预测精度。


通过数轮训练周期迭代优化参数,训练模型包括前向传递、评估损失和后向传递。监控训练集和验证集的准确率,确保模型在训练和泛化方面的有效性。
注意损失曲面、梯度下降等概念和原理,如果不清楚可以回顾一下【深度学习过程】。
过拟合和解决方案
模型过拟合时,其在训练集上的准确率可能较高,但在验证集上的准确率却较低。这表明模型过于复杂或训练过度,导致学习了训练数据中的噪声而不是潜在规律。
训练集,左边损失非常小:

验证集,左边损失反而更大:
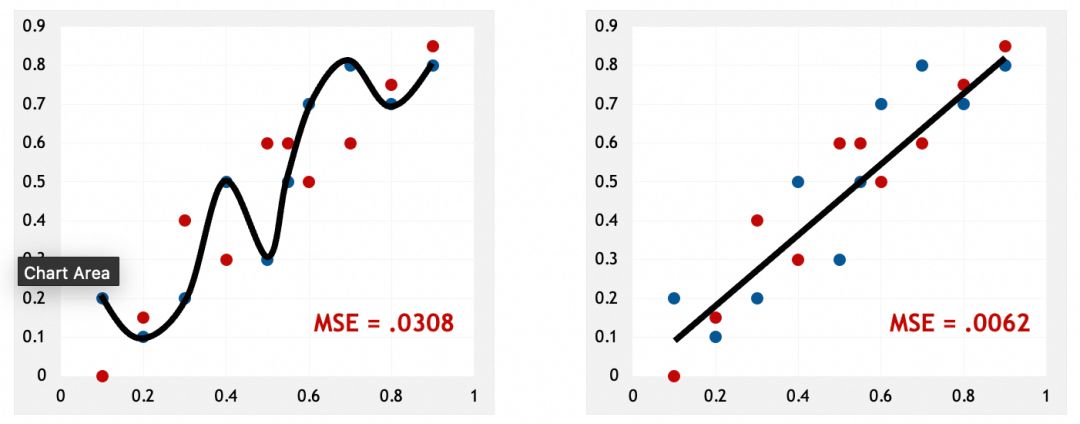
神经网络以类人方式解决问题,通过寻找模式和抽象规律来超越直接记忆训练集。就像人类不会死记硬背具体实例,神经网络也通过抽象学习本质特征,以解决更广泛的问题。
为什么会出现过拟合过拟合提示:
* 训练集特征不显著,不易抽象
* 图像模糊或亮度不足
模型原因:
* 过于复杂或训练过度,导致死记硬背
如何解决过拟合AI技术已成熟,采用先进算法如卷积神经网络和递归神经网络有效解决过拟合问题。详情将在后续文章中深入探讨。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-
