AI带来的不只是效率革命,更是创新的进化
近期,谷歌的Gemini“乌龙”事件多少有些让人失望;然而,面对外界的打击,谷歌并没有就此泄气。最近,谷歌发布了名为VideoPoet的大语言模型,旨在解决当下AI视频生成方面的个性化、精准化、可控性等方面的挑战。

不同于Runway、Pika等以图生视频为核心优势的AI大模型,谷歌VideoPoet号称可以实现“零样本生成视频”,且相较于其他模型,画面更稳定、动作更逼真,清晰度也更高。
VideoPoet的功能十分强大,不仅支持常见的文生视频、图生视频,还支持视频编辑、风格化处理、视频扩展以及视频配乐。

其中,在视频编辑方面,输入文字指令即可实现视频内容调整,比如增加动作、调整镜头、添加环境因素等;


在风格化处理方面,可以通过指令改变视频风格,包括人物、场景、穿着、表现风格等;

在视频扩展方面,可以增加视频元素,也可以生成任意时长的视频;

在视频配乐方面,VideoPoet可以在不给任何文本提示的情况下,根据画面自动生成音频。
可以说,VideoPoet较以往的AI视频大模型有了质的飞跃,向大规模商业化落地前进了一大步。
很多人见识到了AI大模式在文字和图像处理方面的优势,但在视频生成方面,AI却有很大缺陷和可提升的空间。
就目前而言,无论是AI图片还是AI视频,往往具有一次性的特点,即无法对AI成品进行局部微调,只能通过提示词一遍遍的重试,才有可能生成自己想要的成品——当然,目前也有部分模型在局部调优方面展现出了巨大潜力,但距离实际应用落地还有一段距离。图片方面容易提升和优化,但对视频而言,局部调整的难度却要高上几个数量级,其所使用的辅助工具也更多,处理起来也更为复杂。
在之前出圈的部分AI视频案例中,更多凸显的其实是AI的效率革命。如今年8月份,热心网友仅用5晚制作的时长1分钟多钟的AI版《流浪地球3》预告片;


9月份上海交通大学文创学院一名学生,花费不到2周制作的、时长3分钟左右的“校园名人路”视频;
他们所使用的工具往往达2-5种左右,在工具之外,更需要人的大量智力参与其中。
而从谷歌VideoPoet的演示效果来看,其横跨视频制作、剪辑、配乐、修复、二次加工各个维度,在深入参与视频制作的前期至后期各个环节的能力方面,无疑是具有开创性的。由此来看,AI大模型带来的已经不单单是效率革命,更可以称之为创意的革命了。
某种程度看,谷歌VideoPoet的出现,是过往各类模型的集大成者,效率的提升无需多言的,其在功能整合和创新方面的表现也可圈可点。VideoPoet不仅让视频制作变得更简单,更让可编辑的AI视频成为可能。
谷歌VideoPoet的推出,引发不少人的惊叹,大家似乎也都在翘首以盼该应用的尽快上线。而VideoPoet究竟会让大家重拾对谷歌的信心,还是再次对谷歌感到质疑和失望,便要看VideoPoet的实际表现了。
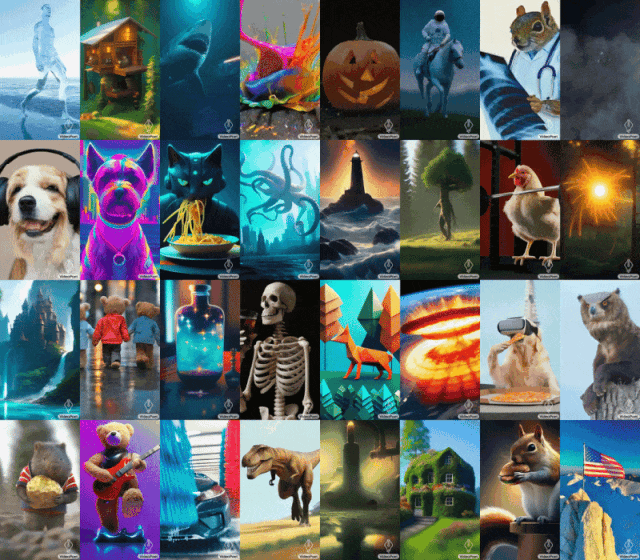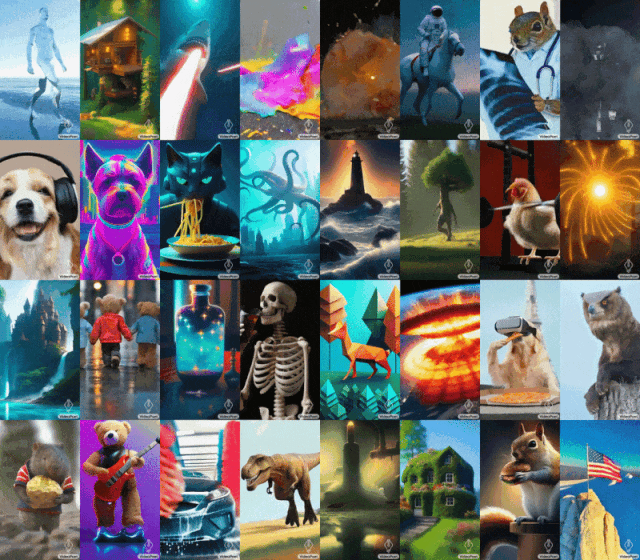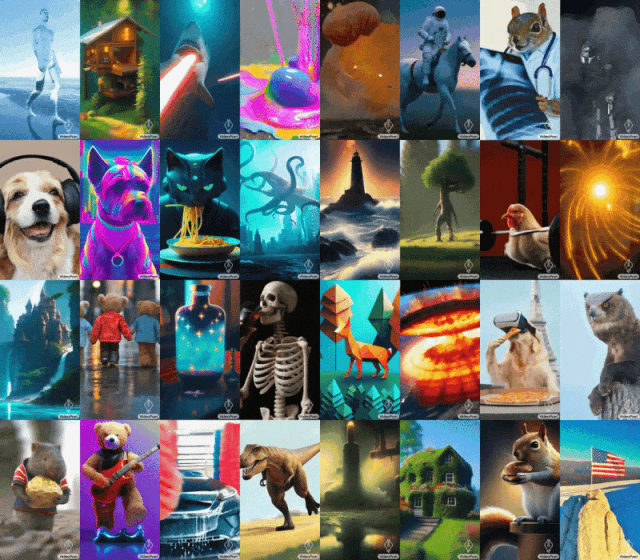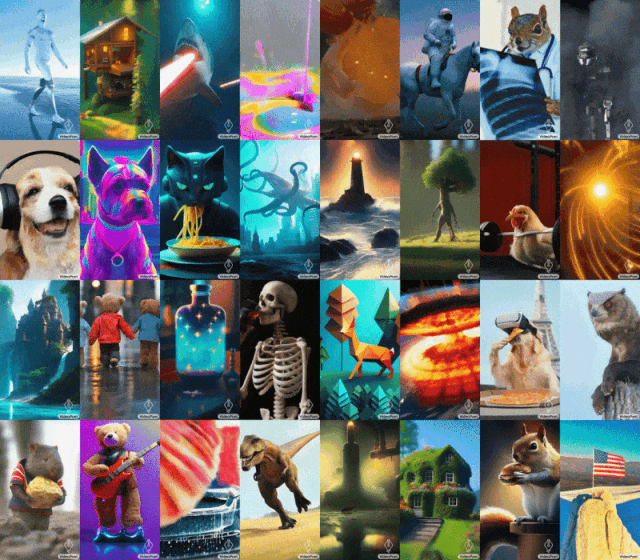
国内方面,针对AI视频也是动作频频。近期,字节和阿里的“掐架”便引发一众网友吃瓜。
先是阿里发布了一个AI项目Animate Anyone,号称只需要1张图片和1个骨骼动画,就可以为任何人制作视频,并宣布源代码稍后开源;


接着,字节跳动也放出类似的AI项目MagicAnimate,一样支持1张图片+1个骨骼动画生成视频,且比阿里更进一步,支持一张照片里多人视频化,同时宣布直接开源;

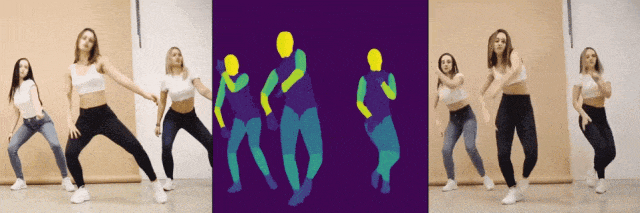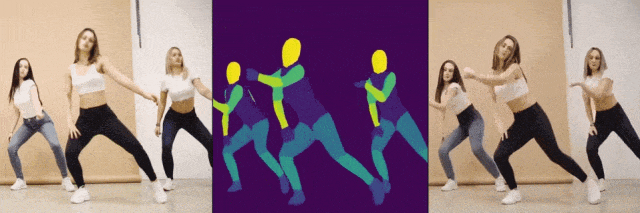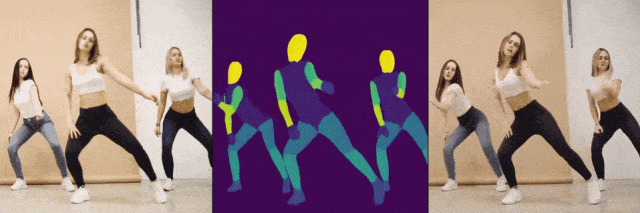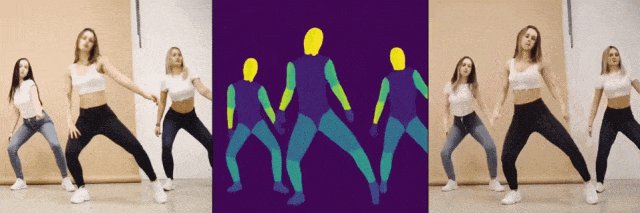
压力给到阿里这边,可阿里也不是“吃素的”,随即发布了一个比上述两个还要强悍的AI项目DreaMoving,可以指定任何人,在任何场景下跳舞。值得一提的是,DreaMoving仅靠脸部照片和文字提示就能生成跳舞视频,不仅支持真人,连动画和绘画人物也不在话下。阿里随即也宣布稍后开源。



DreaMoving的效果很惊艳,不过暂时看不到这个项目究竟有什么商业价值。
从技术角度来看,阿里和字节的AI项目解决了当前大部分AI视频大模型从数据采集到视频生成方面的一些挑战。由于缺乏多样化、一致性的人类舞蹈视频数据集,以及难以获得精确的文本描述,在人类舞蹈动作生成方面,目前的AI视频大模型还面临诸如个性化、可控性等方面的挑战。阿里和字节选择另辟蹊径,通过数据集处理+框架模型重构的方式,提出了新的解决方案,而这无疑为今后国产AI视频大模型的发展提出了新的解题思路。

继人类加大AI语言大模型的投入之后,AI视频大模型的成果也频频迸发。AI席卷之下,其对各行业的冲击之大,将是前所未有的。
当然,随着以谷歌VideoPoet为代表的AI大模型的大规模应用,必然会带来假视频泛滥等后果,然而这并值得忧虑,因为这是新事物出现不可避免的副产物。
乱花渐欲迷人眼之下,保持开放的心态很重要。学会积极拥抱变化,适应变化,运用变化,才有可能在未来的竞争中,把握先机。
