
预测未来 NVIDIA AI 芯片架构:
NVLink和NVLink C2C演进推演互联技术的发展遵循着带宽、调制、编码等基础要素的演进规律。通过结合这些因素以及工程进展和市场需求,我们可以预测技术趋势。
聚焦于NVLink的宏观技术逻辑和可观指标,探究其历史演变。通过分析,预见NVLink未来发展趋势,洞悉技术演進的脈絡。
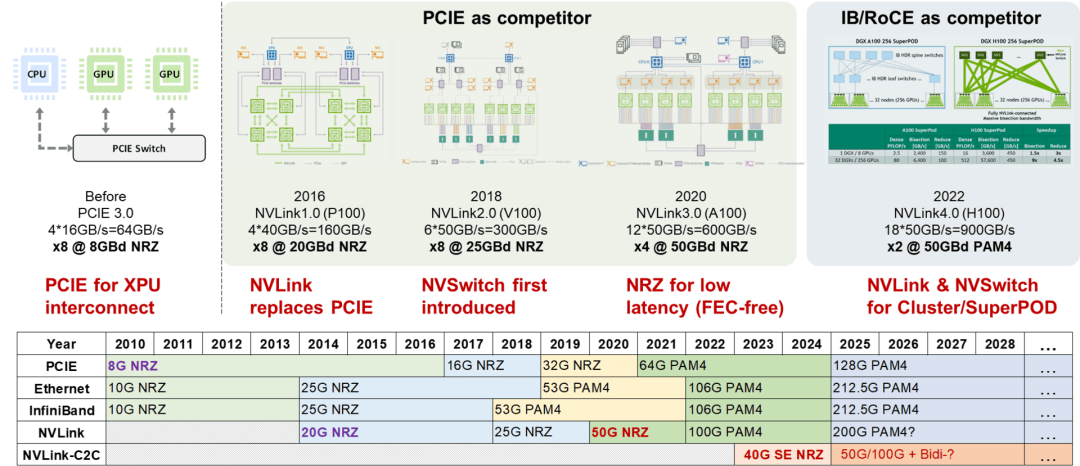
NVLink技术已发展四代,解决业界不同连接协议的痛点。NVLink C2C为单个代际,与不同协议的速率比较,明确了NVLink技术的竞争对象和解决的问题。
开放互联生态包括 PCIe(CXL 依赖)和 Ethernet(InfiniBand 依赖)。NVLink 解决 GPU 互联,早期 GPU 保留了与 CPU 的 PCIe 互联。NVLink 的早期竞争对手是 PCIe,因为它最初用于解决 GPU 互联问题,并继承了 PCIe 与 CPU 互联的技术。
NVLink 以其处于 PCIe 和以太网 SerDes 速率之间的优势地位,在高速互连市场中脱颖而出。与 PCIe 相比,它利用了以太网生态成熟的互连技术,实现了更快的接口速率,同时降低了成本。
通过复用以太网协议,NVLink 融合了以太网在互连方面的成熟度和 PCIe 的性能优势,使其成为需要大规模、高带宽通信的应用的理想选择。
NVLink采用独特的技术规范,区别于Ethernet。NVLink 3.0采用NRZ调制(而非Ethernet的PAM4调制),利用100Gbps PAM4 SerDes的优势,同时降低NRZ调制的阶数,以实现无误码链路,大幅减少FEC带来的延迟。这使得NVLink在50Gb/s速率下,仍能保持卓越的性能。
InfiniBand曾以其低时延优势著称。然而,在50G时代,它采用与以太网相同的PAM4调制,导致其在时延方面的优势不再明显。为了维持低时延,市场选择继续使用25G InfiniBand网络。
由于需要复用以太网光模块生态,InfiniBand网络受制于以太网互联规范。而 NVLink3.0 只需专注于机箱内互联,无需遵循这些限制,从而拥有更大的灵活性。
NVLink 4.0 突破了传统限制,实现了跨盒子、跨框互联,采用符合以太网互联电气规范的频点和调制格式。这使得 NVLink 4.0 得以复用以太网的光模块互联生态,同时避免了 InfiniBand 曾经遇到的问题。
互联时代步入100G,Ethernet、InfiniBand和NVLink的SerDes速率保持同步。200G世代也将延续此一致性,因它们采用相同的SerDes技术。这表明这些互联接口在下一代创新中将步调一致。
NVLink是专有互联生态,提供无与伦比的互联优势,包括:
* 消除跨速率代际兼容性问题
* 支持同代际多种速率接口
* 实现多厂商互通
NVLink 4.0 突破原有框架限制,超越盒子和机框,NVSwitch 作为独立网络设备脱颖而出,与 InfiniBand 和以太网比肩。
NVLink 4.0 专注于负载存储网络,满足超级节点内部内存共享需求。推测采用轻量 FEC 和链路级重传技术,实现低延迟、高可靠互连。
NVLink超越InfiniBand和以太网的时延和可靠性优势,赋能内存语义网络,促进超级节点内内存共享。其独特特性,例如超低时延、超高的可靠性,为总线域网络的存在提供了不容忽视的理由,超越了传统网络的局限性。
NVLink C2C技术,由NVIDIA率先推出,为封装内芯片间通信提供高性能解决方案。随着NVIDIA SuperChip超级芯片的发展,NVLink C2C有望在未来的AI芯片中扮演关键角色。
NVLink C2C采用了先进的9*40Gbps NRZ调制方式,可实现极低延迟和功耗,同时保持连接两个独立封装芯片的能力。其技术不断演进,被视为封装内芯片互连均衡的重大突破,在未来AI芯片的发展中具有广阔前景。
NVLink-C2C未来将升级至更高速率和双向传输。50G NRZ在功耗和延迟上具备优势。保持NRZ调制并优化频率,实施双向传输,可将传输速率提升一倍。
NVLink C2C 互联优化适用于芯片间通信。然而,由于缺乏与标准 SerDes 的速率对应关系,导致信号转换无法比特透明。这限制了其应用场景,并要求在与标准 SerDes 对接时引入协议转换层,从而增加延迟、面积和功耗。
优化后的文章:
高密单端传输技术,如 NVLink C2C,正迎合多对一速率匹配的需求,大幅提升 C2C 互联的应用潜力。
NVLink 和 NVSwitch 历代速率均为上一代的 1.5-2 倍。预计下一代 NVLink 5.0 将采用每通道 200G,每个 GPU 的 NVLink 接口数量将大幅增加,最高可达 32 个或更多。
NVSwitch 4.0 端口速率提升至 200G,交换芯片端口数量激增 2-4 倍,总交换容量高达 51.2T,大幅提升数据传输效率。
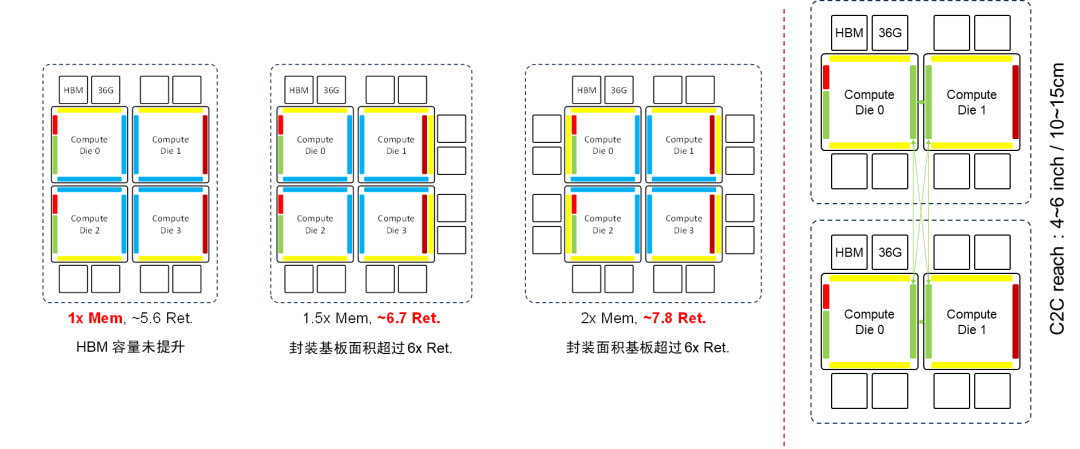
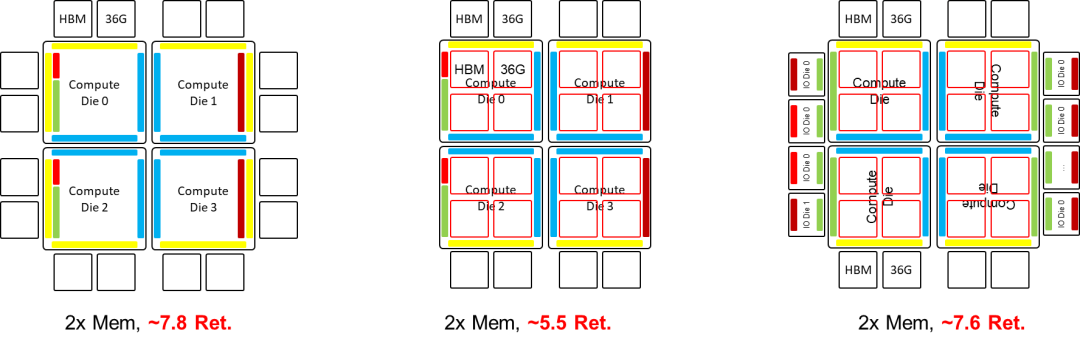
B100 GPU架构推演B100 GPU架构采用创新的双芯封技术,将两颗H100 GPU裸片合并封装,有效提升性能。先进的封装技术带来更低的延迟、更高的带宽,将B100 GPU推向新的高度。
B100 GPU的"双Die"推演架构采用HBM边缝合技术,通过连接H100的HBM边,将IO可用边长翻倍。这一设计显著扩展了IO带宽,提升了系统的性能和效率。
采用"IO边缝合"技术,H100的IO边得以连接双模组,显著提升HBM可用边长,扩大了内存容量扩展的可能性。

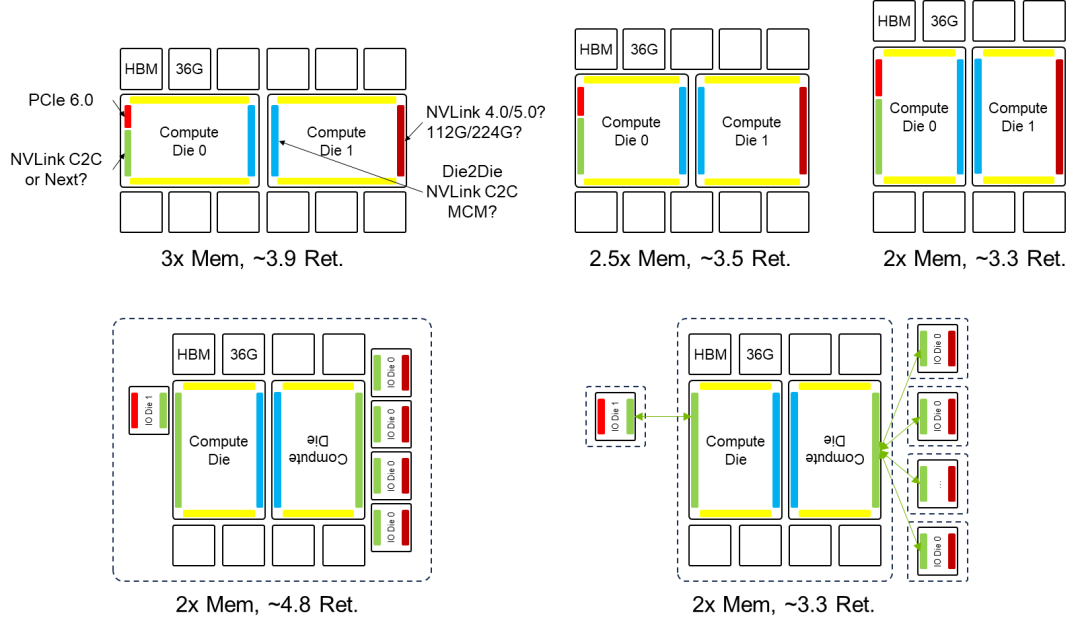
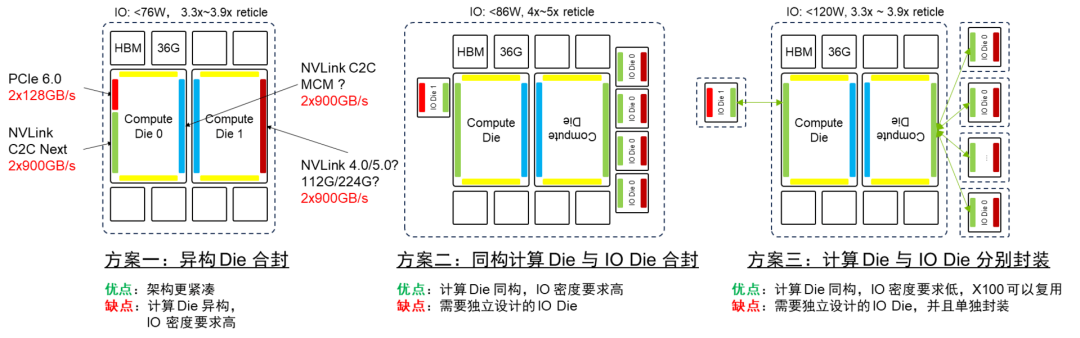
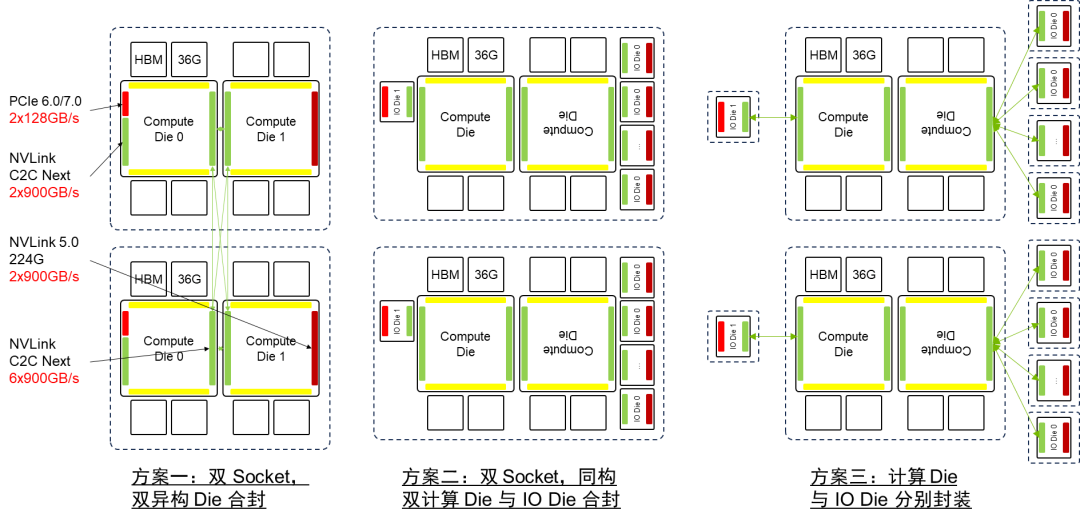
将计算 Die 和 IO Die 分离,同构化计算 Die,降低成本;利用 NVLink C2C 封装互联,扇出 IO,缓解 IO 边密度压力。
NVLink C2C 技术面临协议转换的性能瓶颈,需要在 IO Die 上进行协议转换。为优化性能,理想的解决方案是实现比特透明的 CDR,消除协议转换开销。
方案一和方案三符合当前先进封装能力,但方案三需要额外的协议转换。考虑到 B100 将于 2024 年推出,方案一和方案三更具可行性。方案二则超出当前先进封装能力。
X100 GPU架构推演
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-
