
使用新的h2oml套件,当传统的统计模型失效时,可以通过H2O使用机器学习从数据中发现见解。使用集成决策树--梯度提升机(GBM)或随机森林--进行分类或回归。调整超参数,使用验证或交叉验证(CV),评估模型性能,解释预测结果等。这些功能,现在都是StataNow的一部分。
长期以来,Stata用户依赖线性回归、逻辑回归和传统统计模型从他们的数据中发现见解。在许多应用中,关系往往是复杂和非线性的,这些经典方法可能无法捕捉到更复杂的数据模式。
• 如果您的预测因素以线性(或逻辑)回归模型无法捕捉到的方式相互作用,该怎么办?
• 如果您模型的准确性在仔细选择变量后停滞不前怎么办?
• 如果您需要对缺失数据和多重共线性具有鲁棒性的模型,同时还需要对超出观察数据范围的数据进行概化,该怎么办?
• 最重要的是,如果您能实现上述所有目标,而不需要为了预测能力而牺牲预测的可解释性,会怎么样?
这就是GBMs和random forest革命性地改变了您在Stata中分析数据的方式。通过在Stata中无缝访问H2O的机器学习算法,您现在可以在您熟悉的Stata环境下使用高性能预测模型的强大功能。只需使用具有直观Stata语法的命令即可训练出优于传统技术的复杂集成学习模型。
无缝访问H2O的Stata内部的机器学习算法,您现在可以使用高性能预测模型的强大功能,而无需离开您熟悉的Stata环境。只需使用带有直观Stata语法的命令来训练性能优于传统技术的复杂集成学习模型。您还觉得机器学习是个“黑匣子”?已经不是了!借助Shapley附加解释(SHAP)值、部分相关图(PDPs)和变量重要性排名等工具,GBM和随机森林提供了强大的预测能力,同时保持了可解释性-无需权衡
快速工作流程
1、设置和数据准备
初始化H2O集群,并将当前的Stata数据集导入到名为data 的H2O数据框中:

将数据分为训练集(80%)和验证集(20%):

2、参考(基线)模型
使用默认超参数将GBM模型拟合到二进制响应:

或者使用3-fold CV代替验证集:

存储参考(基线)模型:

3、用户指定的超参数和调优
对11个超参数中的任意一个指定不同的值。例如,指定200棵树和0.2的学习率:

用用户指定的超参数存储模型:

对树的数量和学习率进行超参数调优:

存储调整后的模型:

通过指定accuracy作为调优度量来定制调优设置,并执行随机网格搜索方法:

4、评估模型性能
使用分数历史图检查过度拟合或欠拟合:

评估CV性能

查看按模型性能排序的超参数配置的网格摘要:

使用各种指标比较前10个模型:

手动选择特定的模型:

评估模型指标:

5、比较不同的方法
假设您已经重复了步骤2到4,以选择最佳的随机森林模型rf_tuned。您可以将GBM模型gbm_tuned与随机林模型rf_tuned进行比较,如下所示:

6、执行预测
使用最佳模型进行预测:

7、解释模型结果
评估变量重要性:

生成PDP和个体条件期望( ICE )图:

分析SHAP值以评估预测变量的贡献:

Stata与H2O机器学习集成的命令
监督学习
h2oml GB regression 梯度推进回归
h2oml gbbinclass 梯度推进二元分类
h2oml gbmulticlass 梯度推进多类分类
h2oml RF regression 随机森林回归
h2oml rfbinclass 随机森林二元分类
h2oml rfmulticlass 随机森林多类分类
评估结果和后评估框架
h2omlest H2O估计结果目录
h2omlpostestframe 为后评估分析指定框架
调整和评估摘要
h2omlestat metrics 显示绩效指标
h2omlgof 机器学习方法的拟合优度
h2omlestat cvsummary 显示CV摘要
h2omlestat gridsummary 显示网格搜索摘要
h2omlexplore 网格搜索后浏览模型
h2omlselect 网格搜索后选择模型
h2omlgraph scorehistory 生成分数历史图
二元分类后的性能
h2omlestat threshmetric 显示基于阈值的指标
h2omlestat confmatrix 显示混淆矩阵
h2omlgraph prcurve 绘制精确率-召回率曲线图
h2omlgraph roc 绘制受试者工作特征曲线图(ROC曲线图)
预测
h2omlpredict 连续反应、概率和类别的预测
机器学习可解释性
h2omlgraph varimp 生成变量重要性图
h2omlgraph pdp 生成部分依赖图
h2omlgraph ice 生成个体条件期望图
h2omlgraph shapvalues 为单个观测值生成SHAP值图
h2omlgraph shapsummary 生成SHAP蜂群图
保存决策树
h2omltree 保存决策树的DOT文件并显示规则集
示例
示例数据集:电信客户流失数据集
为了演示h2oml套件,我们重点介绍一个用于二进制分类的GBM模型。其他模型,如random forest或用于回归的GBM,具有非常相似的语法和工作流。我们分析一个虚构的电信公司Telco的数据,该公司在加利福尼亚提供家庭电话和互联网服务。该数据集由IBM提供,包含7,043名客户的26个变量的信息。我们的主要目标是开发一个预测模型,可以识别哪些客户面临流失风险,这意味着他们可能会终止与电信公司的服务。我们的二元响应churn表明客户在过去一个月内停止了服务,还是继续留在Telco公司。
预测因素(特征)包括客户人口统计数据(如性别和年龄);账户详细信息(如合同类型和时长);以及服务订阅(如互联网、电话、安全服务等)。
我们希望预测潜在客户流失的客户行为模式,这可以帮助电信公司采取积极措施留住有价值的客户。
在Stata中为H2O机器学习准备数据
我们首先加载数据集并启动一个H2O集群。

然后我们将当前的数据集放入一个H2O框架churn中,并将其设为当前的H2O框架。

我们将数据分割为训练集和测试集,其中80%的观测值被分配到训练样本中。随后,在估计过程中,我们将在训练数据上使用交叉验证(CV)来控制过拟合。

为了方便起见,我们创建了一个全局宏来存储预测变量的名称。

参考GBM模型
我们使用默认参数设置和h2orseed(19)(以确保可重复性),拟合了一个带有3折分层交叉验证(SCV)的GBM模型。分层交叉验证(SCV)特别适用于类别不平衡(流失率的不同水平)的分类任务。

标题部分提供了模型的详细信息,显示h2oml gbbinclass使用了Bernoulli损失函数(其他损失函数可用于h2oml-gbrigress的回归)。训练集包含5,643个观测值,并使用了训练数据的3-fold SCV。超参数部分(模型参数)报告了超参数的用户指定值和实际值,如果指定提前停止,这些值可能会有所不同。
指标汇总表展示了训练数据和交叉验证(CV)数据的二进制分类性能指标。由于我们的类别不平衡,我们将选择使用精确率-召回率曲线下面积(AUCPR)作为评估指标。AUCPR的范围从0到1,1表示完美的性能。虽然CV指标是我们的主要关注点,但我们也会检查训练指标,以确保略微过拟合并避免欠拟合。训练集和交叉验证集的AUCPR之间存在正向差异(0.8024 - 0.6585 = 0.1439)是正常的,但如果差距过大,则可能表明模型存在过拟合问题,这意味着模型可能无法很好地泛化到新数据上。
我们存储参考估计结果用于以后的比较:

评估三个方面的指标可变性可确保模型性能与特定的数据分割无关。CV指标的高变化可能表明对新数据的泛化能力较差。这可以通过使用h2omlestat cvsummary命令来完成;
模型选择和超参数调整
我们的基线模型的CV AUCPR为0.6585。为了提高模型性能,我们将调整超参数。虽然GBM模型有11个可调参数,但为了简化操作,我们仅在小范围内调整ntrees()(树的数量)和predsamprate()(预测变量采样率)这两个参数。超参数调整是一个迭代过程,此示例仅用作说明。

标题部分显示了调整细节,包括调整方法(Cartesian)、调整指标(AUCPR)和超参数的网格搜索范围。所选值,ntree()为100,predsamprate()为0.15,对应于性能最佳的模型。输出的其余部分显示了最优模型的超参数值和指标摘要。
通过调整,我们将CV AUCPR从0.6585增加到0.6739。改进很小,因为我们在这个例子中只探索了超参数的一小部分。
让我们存储这个经过最佳调优的模型以供以后使用:
我们可以使用h2omlestat gridsummary命令获取网格搜索摘要。此命令列出了我们正在调整的超参数的配置,按AUCPR排名。

我们希望使用h2omlexplore命令,根据其他指标比较前两个模型:

如果我们选择的模型不是最优的模型(也许是一个性能稍差但使用较少的树的模型),我们可以通过h2omlselect命令来选择它;
让我们使用h2omlgof命令,根据其他指标,将最佳模型gbm_tuned与上一节中的参考模型gbm_default进行比较。

输出结果显示,首先是训练结果,随后是交叉验证(CV)结果。从CV结果可以看出,调参后所有指标的性能均有所提升:更低的对数损失(log loss)、每类错误率(per-class error)、均方误差(MSE)和均方根误差(RMSE),以及更高的AUC、AUCPR和基尼系数(Gini coefficient),表明调参后的模型性能更优。
我们还可以根据变量重要性来细化预测因素列表:

根据上述图表,我们可能会决定删除预测变量onlinebackup。
方法选择:GBM vs随机森林
假设我们按照与之前相同的步骤,使用h2oml-rfbinclass训练一个随机森林进行二元分类。为简单起见,假设在超参数调整后,最佳模型为:

现在,我们使用测试集(在数据分割时创建的测试数据集)来比较调参后的随机森林方法(rf_tuned)和调参后的GBM方法(gbm_tuned)。我们使用h2omlpostestframe命令来指定框架的名称(在我们的例子中是test),以便所有后续的估计后命令在计算rf_tuned和gbm_tuned结果时使用该框架:
我们没有使用h2omlestat指标在测试集上分别列出每种方法的性能指标,而是使用h2omlgof并排显示结果:
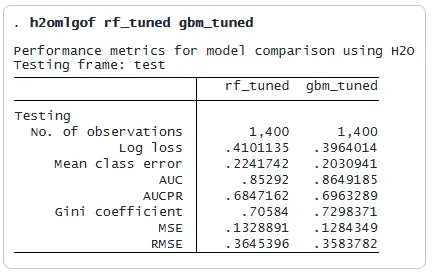
GBM优于随机森林,因为它具有更高的AUCPR,使其成为首选方法。我们可以使用ROC曲线进一步比较这些方法,其中更靠近左上角的曲线表示性能更好。
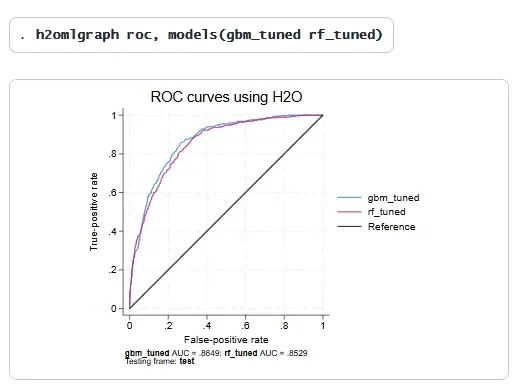
根据ROC结果,正如我们所料,GBM方法略优于随机森林方法。
另一种比较不同方法和模型之间分类预测的流行方法是使用混淆矩阵,该矩阵报告了正确和错误预测结果的数量。
对新数据的预测
假设该公司收集了存储在newchurn.dta中的新数据。它希望基于GBM模型GBM_tuned预测这些新客户流失的概率。让我们将新数据集视为H2O集newchurn。

我们使用h2omlpredict来预测流失概率和类别。默认情况下,它会预测类别(是或否);要获取概率,需指定pr选项。在上一节中,我们通过h2omlposttestframe将test设置为估计后框架。为了对新数据集进行预测,需指定frame(newchurn)。以下,我们使用GBM模型gbm_tuned来预测类别和概率。

由于我们指定了frame(newchurn),生成的类别变量(churnhat)和类别概率变量(churnprob1和churnprob2)可以在newchurn框架中找到。下面我们列出一些预测类别和概率的值。

例如,churnprob2显示第一位客户的流失概率为22%,第二位客户的流失概率为78%。预测类别(是或否)存储在churnhat中,其赋值基于churnprob2是否超过默认的F1最优阈值0.2378。该阈值是通过h2omlestat threshmetric获得的,该命令显示了优化各种指标的阈值。要使用自定义阈值,可以在h2omlpredict中通过threshold()选项指定。
解释预测
机器学习的一个关键挑战是理解为什么模型会做出特定的预测。可解释性确保预测不仅准确,而且可解释和合理。
全局模型描述了机器学习模型的平均行为。示例包括以下内容:
• 变量重要性
• 全局代理模型(近似机器学习预测的简单可解释模型)
• PDPs
局部模型通过近似模型对单个观测的行为来解释个体预测。示例包括以下内容:
• ICE曲线
• SHAP值
全局可解释性方法
我们之前已经看到了一个变量重要性图的例子;因此,我们在这里重点构建一个代理模型。我们首先恢复之前训练的最佳GBM模型(GBM_tuned)。

接下来,我们通过指定frame(churn)选项,使用GBM模型对整个数据集(而不仅仅是测试集)进行流失预测:

为了提高可解释性,我们使用例如分类树来构建一个全局代理模型,以近似来自模型gbm_tuned,rockhat的预测。
首先,我们将工作框架切换到完整的流失数据集:

然后,为了说明,我们训练一个最大深度为3(maxdepth(3))的单个决策树(ntrees(1))作为全局代理模型:

这个分类树是对复杂GBM模型的简化近似,使预测结果更具可解释性,同时保留了有用的洞察。
分类树在视觉上更容易解释。使用h2omltree命令的dotsaving()选项,我们可以生成一个DOT文件,该文件可以通过Graphviz绘制,以实现更好的可视化效果。

终端节点的值表示客户不流失的概率。例如,拥有一年或两年合同且没有互联网服务或使用在线备份和安全服务的客户,其留存的概率最高(0.997)。这意味着他们的流失概率仅为0.003(1 - 0.997),因此他们是最不可能离开的客户。
接下来,我们分析重要预测变量(之前通过h2omlgraph varimp识别)如何影响流失。我们使用部分依赖图(PDPs),这是一种全局可解释性方法,用于展示所选预测变量对预测结果的边际影响。我们首先恢复GBM模型的估计结果,以确保后续的估计后命令适用于最佳GBM模型(gbm_tuned)。

我们使用带有notest选项的h2omlpostestframe将流失数据集设置为后估计分析的活动框架,而不将其视为测试集。

然后,我们为关键预测因子生成PDPs:

PDP模式(图中的红线)与代理树的结果一致。例如,对于签订一年或两年合同(contract)的客户和使用公司服务时间较长的客户(tenuremonth),流失的概率(显示在y轴上)降低;
局部可解释方法
对于局部可解释性,我们使用SHAP值,该值估计每个预测因素对单个预测的贡献。SHAP值有助于解释为什么预测特定客户会流失,从而使机器学习决策更加透明。
我们现在使用h2omlgraph shapvalues为观测值19(使用按月合同服务9个月的女性客户,其观测到的流失率和预测的流失率均为Yes)生成SHAP值,作为前10个SHAP重要预测因素。

蓝色条表示增加流失概率的预测变量,而红色条表示减少流失概率的预测变量。SHAP值与之前的发现一致。特别是,按月合同、较短的合同期限(tenuremonths)以及未使用在线安全服务,对这位特定客户的流失有正向贡献。需要注意的是,二进制分类的SHAP值是以logit尺度报告的。例如,原始预测值f(x) = 0.2063是“观测值19会流失”的预测概率的logit值。必须使用逆logit变换将其解释为概率。
SHAP汇总(蜂群)图可视化了所有观测值的SHAP值,显示了预测值的重要性和对响应的影响。为了说明,我们绘制了四个最重要的预测因素:

y轴上的预测值按SHAP重要性排序(最大的绝对SHAP值排在第一位)。蓝色显示的较小的合同归一化预测值(按月对一年对两年)与正的SHAP值相关,这意味着较短的合同使客户更有可能离开(增加流失的可能性);
关闭H2O集群
完成分析后,您可以使用以下命令断开与H2O集群的连接

关闭Stata-H2O会话,但保持集群在后台运行。您可以稍后重新连接
要完全关闭群集并删除所有资源,请使用

北京天演融智软件有限公司(科学软件网)是Stata软件在中国的授权经销商,为中国的软件用户提供优质的服务。
