scrapy startproject tencent
cd tencent
scrapy genspider hr "tencent.com"
执行爬虫的命令
scrapy crawl hr
以上创建一个爬虫
爬虫源码

爬取内容类源码

设置


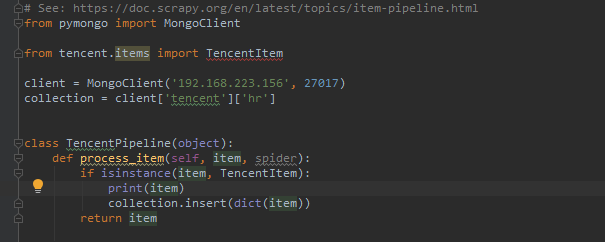
管道处理,存储进数据库
服务器上存储的内容截图
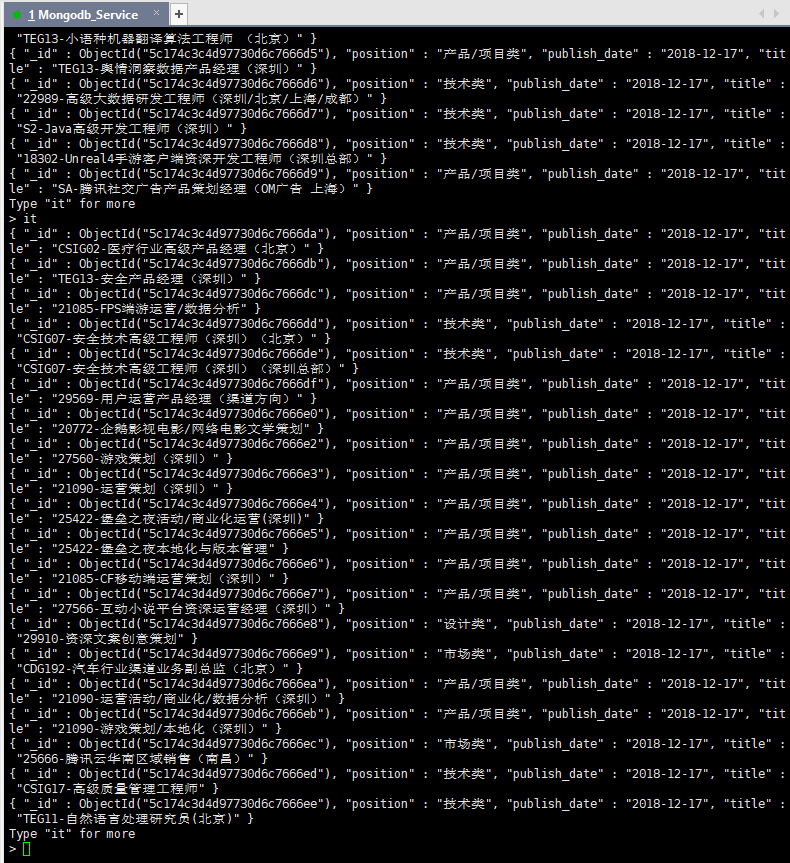
db.hr.find()
查询全部的招聘数据
如何查看是否能够用xpath爬取数据:如果doc内容和element内容一致,即可


scrapy startproject tencent
cd tencent
scrapy genspider hr "tencent.com"
执行爬虫的命令
scrapy crawl hr
以上创建一个爬虫
爬虫源码
爬取内容类源码
设置
管道处理,存储进数据库
服务器上存储的内容截图
db.hr.find()
查询全部的招聘数据
如何查看是否能够用xpath爬取数据:如果doc内容和element内容一致,即可
