
Transformer 模型是一种革命性的深度学习模型架构,主要用于处理序列到序列(sequence-to-sequence)的任务,如机器翻译和自然语言处理中的各种任务,例如问答系统和文本生成等。它由Vaswani等人于2017年提出,通过注意力机制(self-attention mechanism)实现了并行化处理序列数据,避免了传统循环神经网络(RNN)和卷积神经网络(CNN)中的瓶颈和限制。
而Transformer模型作为一个独特的模型,其设计之精美,模型之独特,需要人工智能技术,离不开Transformer模型的学习。那么Transformer模型到底有什么魅力?
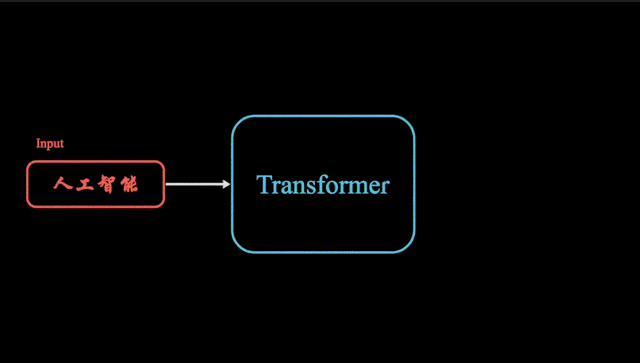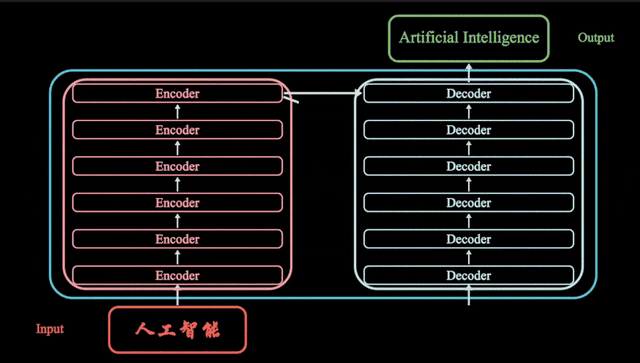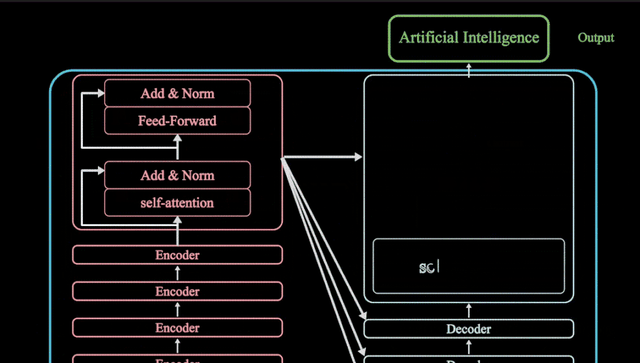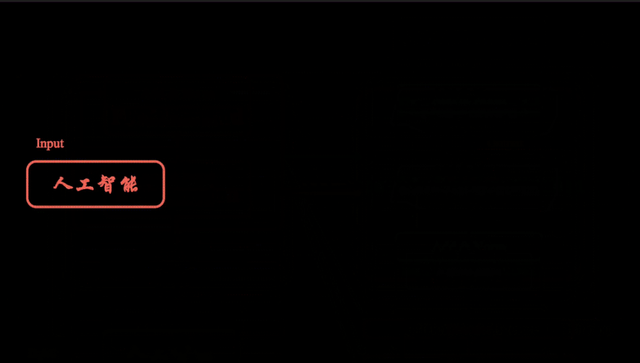
什么是Transformer模型
Transformer 是一种神经网络架构,它从根本上改变了人工智能的方法。Transformer 首次出现在 2017 年的开创性论文 《Attention is All You Need》 中,此后成为深度学习模型的首选架构,为 OpenAI 的GPT、Meta 的Llama和 Google 的 Gemini等文本生成模型提供支持。除了文本之外,Transformer 还应用于音频生成、 图像识别、 蛋白质结构预测,甚至游戏,展示了其在众多领域的多功能性。
从根本上讲,文本生成 Transformer 模型基于下一个单词预测的原理运行:给定用户的文本提示,最有可能跟在该输入之后的下一个单词是什么?Transformer 的核心创新和强大之处在于它们使用了自注意力机制,这使它们能够比以前的架构更有效地处理整个序列并捕获长距离依赖关系。

Transformer 架构
Transformer 模型包含以下几个关键组件:
嵌入:文本输入被分成更小的单位,称为token,可以是单词或子单词。这些token被转换成称为嵌入的数值向量,用于捕获单词的语义 信息。

位置编码(Positional Encoding):由于 Transformer 模型没有显式的顺序处理机制,它引入了位置编码来帮助模型理解序列中各个位置的相对位置信息。
Transformer Block是模型的基本构建块,用于处理和转换输入数据。
每个块包括:注意力机制,Transformer 模块的核心组件。它允许 token 与其他 token 进行通信,捕获上下文信息和单词之间的关系。

自注意力机制(Self-Attention):Transformer 使用了自注意力机制来计算序列中各个位置之间的依赖关系。这允许模型同时处理输入序列中的所有位置信息,而无需像 RNN 或 CNN 那样逐步处理序列。
编码器-解码器结构(Encoder-Decoder Architecture):在机器翻译等任务中,Transformer 使用编码器来处理输入序列,并使用解码器生成输出序列。编码器和解码器都由多层堆叠的自注意力层和前馈神经网络层组成。
多头注意力(Multi-Head Attention):为了增强模型对不同表示空间的表达能力,Transformer 中的自注意力机制被扩展成多个注意力头,每个头都学习并关注序列中的不同子空间。

每个 token 的嵌入向量被转换成三个向量: 查询 (Q)、 键 (K)和 值 (V) 。这些向量是通过将输入嵌入矩阵与学习到的Q、 K和 V的权重矩阵相乘而得出的 。通过使用这些 QKV 值,模型可以计算注意力分数,这决定了每个token在生成预测时应该获得多少关注。

掩蔽自注意力机制允许模型通过关注输入的相关部分来生成序列,同时阻止访问未来的输入信息。
注意力分数:查询和键矩阵的点积 确定每个查询与每个键的对齐方式,从而产生一个反映所有输入token之间关系的方阵。掩码:在注意力矩阵的上三角上应用掩码,以防止模型访问未来的信息,并将这些值设置为负无穷大。模型需要学习如何在不“窥视”未来的情况下预测下一个标记。Softmax:经过掩蔽后,注意力得分通过 softmax 运算转换为概率,该运算取每个注意力得分的指数。残差连接和层归一化(Residual Connections and Layer Normalization):Transformer 中的每个子层(自注意力层和前馈神经网络层)都使用了残差连接,以及紧随其后的层归一化操作,有助于提高训练速度和模型收敛性。

MLP(多层感知器)层,一个独立对每个 token 进行操作的前馈网络。注意力机制层的目标是在 token 之间关联信息,而 MLP 的目标是优化每个 token 的表示。也称之为前馈神经网络(Feed-Forward Neural Networks),在编码器和解码器中,每个位置都连接一个全连接前馈神经网络。这些网络在每个位置独立地作用于向量,通过激活函数(通常是ReLU)进行非线性转换。

任务特定的输出层(Task-Specific Output Layers):最后的线性层和 softmax 层将处理后的嵌入转换为概率,使模型能够对序列中的下一个标记做出预测。在不同的应用中,如机器翻译或文本生成,Transformer 的解码器最后一层通常是特定于任务的输出层,例如 softmax 分类器用于预测目标语言中的下一个单词。
https://poloclub.github.io/transformer-explainer/https://github.com/dair-ai/ml-visuals而以上的图片都是动图展示,可以到以上网站上面点击查看,当然更多视频教程可以参考专栏内容。
