德国时间2024年9月3日,英特尔在柏林正式发布了英特尔酷睿Ultra 200V处理器平台(研发代号:Lunarlake,月亮湖),正是这一代起,英特尔的处理器分为了两个架构:Lunarlake和Arrowlake,这意味着英特尔可以专注于轻薄笔记本产品线推出移动端处理器,所以,英特尔酷睿Ultra 200V处理器会更加突出产品的能效比,当然,今天我们看完所有的CPU、GPU和NPU的性能参数后,是真的感受到英特尔的“后发优势”(以往英特尔总是先于竞争对手发布自己的产品),它的确拥有超越今年之前发布的同级笔记本处理器产品的实力。

我们之前已经在Computex 2024期间给大家讲过了Lunarlake的构架以及高达120TOPS的AI算力,在IFA期间,英特尔补齐了英特尔酷睿Ultra 200V处理器平台的所有拼图:它采用最新一代性能核(Skymont)和低功耗能效核(Lion Cove)组成的混合型处理器架构,引入了增强型NPU 4.0 AI引擎,以满足Windows 12 40TOPS以上的AI性能加载需求,并搭配基于全新Xe2架构的内置英特尔锐炫显卡。

英特尔为英特尔酷睿Ultra 200V处理器冠以一个响亮的目标:伟大的AI PC始于一台伟大的PC,事实上,它也对得起这个称谓,英特尔对全新轻薄笔记本处理器进行了全面的提升:从能效,到核心性能,到核心显卡性能,以及AI性能的全面提升。
大家可以感受到,近两年的处理器产品都更强调能效比,专门为轻薄本设计的英特尔酷睿Ultra 200V处理器平台更是将这个参数放在了所有设计目标的首位。酷睿Ultra 200V处理器达到了x86构架历史上最出色的能效比,相比前代能耗降低了50%,而且这一切建立在CPU、GPU和NPU性能同时大为增长的基础上,所以说英特尔在能效上付出的远不止纸面上看到的。
x86构架史上最优能效比是怎么诞生的
英特尔将其称为x86历史最高效的处理器,这一点并没有言过其事,酷睿Ultra 200V处理器在续航等很多指标上是能够比以能效比著称的Arm构架高通骁龙处理器更为出色的,在轻薄型笔记本平台上,能效带来的实际体验是要比性能更明显的,因为性能带来的流畅度还取决于系统、软件等因素,而决定能效比结果的主要还在处理器本身之上。


能效比的故事要从Computex说起,当时英特尔展示了一台Lunarlake的原型机,并给我们拆解开来。当时这台产品就以极度轻薄的设计让人惊叹。酷睿Ultra 200V的性能刚才我们已经展示给大家,不论是CPU、GPU,还是NPU,都是今年最出色的存在,能够做得如此之薄,就落脚在能效比上。


事实上,第一代酷睿Ultra机型便在轻薄化上做得相当令人惊叹,而建立在能效比更出色的酷睿Ultra 200V之上,英特尔展示的Demo机型相当今人惊叹,1kg以下的13英寸、1.5kg以下的16英寸机型在发布会上相继展示。随着酷睿Ultra 200V的发布,笔记本市场将迎来新一波的轻薄本潮,我们来看看英特尔在能耗比上做出的努力:

总的来看,新处理器这次变化最大的是引擎架构、SoC和平台级技术,它采用了全新的8MB内存侧缓存,大大拉近了CPU和内存之前的“数据差”,可以更高效地为内存密集形的IP提供数据;封装级内存是大家关注酷睿Ultra 200V处理器的一个重要的点,将内存颗粒从主板上移到处理器之上(今年很多轻薄本都采用板载设计),大大降低了延迟,更为出色的是,PHY功耗降低了40%;另外,英特尔还采用了全新的供电构架,以提升电能利用率,可以看到的是,新处理器加强了电源管理的集成度,并优化了硬件线程调度器;改进能效核则是肉眼可见提升能效比的方法,今年英特尔的新品很多都会以增强能效耗性能来提升多线程能力。

朋友们应该还记得前一代的Meteor Lake的低功耗岛吧,这次英特尔简化了处理器构架,直接用4个能效核替代以前代2核的低功耗岛,并且提从了4MB的共享内存,兼顾能效的同时提升了出口带宽。

以最顶级的酷睿Ultra 9 288V为例,如果与高通的X1E-80-100处理器相比,性能最多超出了1.2倍;而能耗则大大降低,相比酷睿Ultra 7 165H,能耗比后者最大降低了2.29倍。

代际间的游戏差异也特别明显,这个主要考验核显之间的性能和能效差距。依旧是以酷睿Ultra 9 288V和酷睿Ultra 7 165H相比,英特尔官方公布的结果相当惊人,在《刺客信条:英灵殿》、《赛博朋克2077》和《模拟农场22》三款游戏中,新处理器的游戏性能(帧数)分别增长了32%、44%和68%,而能耗却降低了35%、22%和11%。

在UL Procyon Office测试、MobileMark、网络浏览器、Zoom、Microsoft Teams网络会议软件,以及Youtube 4K30帧 AV1编码格式的视频等典型性应用中,酷睿Ultra 9 288V比酷睿Ultra 7 165H获得平均50%左右的能效比提升。

对消费者来说,最直接的感受便是性能与续航,这次英特尔公布的酷睿Ultra 7268v的UL Procyon Office续航测试就达到了20.1小时的水准,而使用Microsoft Teams的续航时间也达到10.7小时,Office续航测试是超过高通骁龙X1E-80-100芯片的。

UL Procyon Office的续航测试比起PCMark 10现代办公测试的负载略大一些,在OEM的发布会上,厂商公布酷睿Ultra 200V的PCMark 10现代办公测试便普遍达到25~29小时,相对我们测过第一代酷睿Ultra处理器轻薄普遍在14~16小时的续航成绩,有着非常明显的提升。

在采用酷睿Ultra 9 288V与高通骁龙X1E-78-100和AMD HX 370这些各个厂商目前最高的处理器作比较,可以看到酷睿Ultra 200V处理器平台依旧保持了优势,甚至比Ultra 7更为明显。

之所以达成更优的结果,我们认为最大原因还在是于架构的更新上:Meteor Lake还是将能效核和性能核放在CPU Lite之中,调用是同步的;而Lunarlake除了用能效核替代原本低功耗岛的一部分工作,同时也会独立承担日常负载,像Office这样的低负载使用场景,仅需要调用能效核就行了。当然,降低能耗的途径并非单一的GPU同样以性能飞跃式提升的前提下,将能耗降了两倍,这也是非常了不起的设计,我们一会儿再讲。
从核心、硬件调度器到低延迟结构,打造最适合轻薄本的CPU
在Lunarlake公布构架时,就有人带节奏攻击它仅有4性能核、4能效核,且不具备超线程,性能不足。不考虑应用场景的类似发言应该都归于“耍流氓”的那一类中,我们99%的轻薄本应用场景用“4+4”的8核构架是绝对够用的,DIE上的面积更多留给dGPU和NPU,以显著提升图形性能与AI算力,像需要跑满全核、且需要多线程的渲染、工业设计等需求,完全可以交给Arrowlake打造的全能或高性能本。不用单一系列处理器产品来覆盖用户的所有使用场景,正是这一代英特尔处理器的最大设计特点。

从参数来看,酷睿Ultra 200V的4性能核(Lion Cove)最高可睿频到5.1GHz,扩展了18个执行端口,最高共享12MB的L3缓存,重新拆分乱序引擎和提升更广泛的调度,能够让大大的升数据的命中率和流畅度,另外内存(增强型子系统)、电源(基于AI)和PPA(16.7MHz)都进行了不同程度的优化。以上改进是针对轻薄本进行了开发,以提升更高效的执行速度。
另外4个能效核(Skymont)最高可睿频至3.7GHz,最高睿频频率还往略收了100MHz,最高共享4MB L3缓存。值得关注的是,能效核提供了高达26个调度窗口,拥有更深的排列以增强并行处理能力;在增强预测能力后,核心调集指令集的能力大为增强,AI吞吐量也达到原有的2倍。能效核的改进比性能核更看重并行执行效率和AI负载,因为在日常调度中,能效核会优于性能核调度,甚至还要替代低功耗岛作为SoC的常备调度核来长期“值班”。

在整个计算构架上,性能核的调优其实是相对比较直接的:酷睿Ultra 200V在提升了15%左右的能效比同时,提升了10%左右单位面积的性能密度,整体性能提升了30%。虽然将能效核心单独提了出去,但英特尔依旧没有启用超线程。超线程的确能够让线程数量倍增,但线程调度时会降低单核心运行效率,如果开启,性能核的代际整体提升可能就仅有15%了。

将酷睿Ultra 9 288V与AMD HX 370,以及高通骁龙两块处理器作比较,可以看到酷睿Ultra 9 288V在Cinebench 2024、Geekbench 6.3和SPECate 2017三项针对CPU的典型性Benchmark中都获得了最高分,与高通骁龙X1E-78-100相比,分别提升了20%、21%和61%。

相对第一代酷睿Ultra处理器,酷睿Ultra 200V在性能曲线上也有所调整,可以看到17W的单线程性能提升是最高的,达到3倍。如果说性能有一个甜蜜点,那么17W就是最优的。所以我们看到,酷睿Ultra 200V不论是Ultra 5、7还是9,都将基准性能释放定在17W。

多线程能力上,也可以看到旗舰级的酷睿Ultra 9 288V拥有看齐苹果M3芯片的能效比(20W),这是x86构架中极为难得的,尤其是它的基础性能释放还定在17~30W的区间里。

来看看常用应用场景,在UL Procyon Office、Speedometer 3、Pugetbench Photoshop、Crossmark和Handbrake等Benchmark和软件中,酷睿Ultra 9 288V获得了绝大多数的优势,相比高通骁龙X1E-78-100最高拥有92%的提升,大部分场景也优于AMD HX 370。

我之前聊存储产品时经常讲到“性能的本质其实是延迟”,不一定对,但延迟指标比性能指标更贴近用户的流畅性体验。所以,酷睿Ultra 200V在芯片设计时专门对延迟做了优化,从性能核出发的数据延迟降到了20+ns左右,而能效核出发的数据则降到了50+ns,尤其是采用封装级内存之后,CPU到内存间的延迟降低到90ns左右,要知道,我们测过的前代板载内存延迟基本在130ns以上。

全新的性能调度器是充分匹配酷睿Ultra 200V针对轻薄本产品线的需求场景的,首先便是调度策略改为了动态的方式,而不是针对一类应用统一“打分”,在硬件调度中,我们甚至看到单一能效率的调用方式,也就是说,只要是单线程的低负载场景,便不再调用其他核心;而多线程任务,也优先调度能效核;直到较重负载时,才会根据需求高度到性能核上。
核心显卡再次遥遥领先
酷睿Ultra 200V采用了第二代Xe显卡构架,它包含第二代Xe核心、增强的矢量引擎、更大的光追单元、全新的XMX AI引擎,以及兼顾性能与能效的图形加速能力,并且全面支持最新的DirectX Ultimate XII,这完全就是一个全新的核心显卡,它的目标便是打造当下最强的核心显卡能力。这两年英特尔终于醒过味来了,核心显卡才是赢得主流消费级用户的主要推力,之所以比竞品后发,就是要将这一优势保持到最后。

比较两代Xe显卡,性能提升达到了31%,这是英特尔基于多达45个游戏测试出来的平均结果。
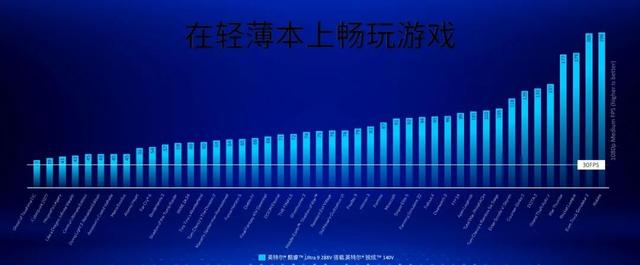
像《赛博朋克2077》这样的游戏,可以跑到39fps,大部分的3A游戏和网游,都能运行在60fps以上的流畅程度。

酷睿Ultra 9 288V与高通骁龙X1E-78-100来比较游戏性能,的确有些胜之不武,在上述游戏清单中,后者仅有23个游戏能够游戏,有的游戏,平均帧数也低了68%。

AMD的890M集显是一个好对手,与之相比,酷睿Ultra 9 288V的Intel Arc 140V核心显卡同样拥有明显的优势,在绝大多数游戏中,Intel Arc 140V的帧数都超越了890M,所有游戏平均超越了16%。

我们来看一下游戏实际体验,可以看到酷睿Ultra 7 258V和酷睿Ultra 9 288V在《英雄联盟》中的游戏帧数超过高通骁龙X1E-80-100两倍以上,而且也大大领先了AMD HX 370,说明核芯显卡的性能已经是独一档的存在。

同时,我们还可以看到酷睿Ultra 200V系列的核心显卡在能耗比上也做到相当高的水准,酷睿Ultra 9 288V的能耗与高通骁龙X1E-80-100相差无几,领先x86“同行”AMD HX 370约10%;而酷睿Ultra 7 258V则领先了AMD HX 370了20%以上。

3A游戏上,酷睿Ultra 9 288V的Intel Arc 140V核心显卡也领先了AMD HX 370的890M集显30%左右的性能,而且99%的游戏都能以大于30FPS以上(基本流畅)的帧数运行。

而与之匹配的XeSS,支持游戏首次来到120个,作为实现游戏更大分辨率的利器,Xe超级采样技术已经肉眼可见地逐步覆盖了主流游戏,而且还能带来额外6%的性能提升,这能够大大增加英特尔锐炫显卡的竞争实力。


英特尔一向擅长的媒体编解码器,酷睿Ultra 200V系列同样有着领先的表现,不仅解码能力大大超越了AMD和高通,而且在播放4K AV1格式的流媒体文件时,比起前代处理器的能耗也降低了近1倍。
更高AI效能、更强兼容性、更全AI PC生态
在酷睿Ultra 200V系列上,明显更加看重AI算力的成长,120 TOPS的算力我们之前在Computex便已谈及,对于跑在笔记本上的AI能力,我们更看重NPU的轻度、低延迟的实时负载能力,因为这才是突破原有功能边际的最适合硬件。

以运行20轮的Stable Diffusion 1.5的图片生成作为测试项,如果以FP16的浮点半精度跑在核心显卡上,酷睿Ultra 9 288V完美完成了任务,而骁龙X1E-78-100则倒在了该轮测试上;换为W8A16的神经网络模型量化方式跑在NPU之上时,骁龙X1E-78-100虽然完成了任务,但效率依旧不敌酷睿Ultra 9 288V。

在ULProcyon AI计算机视觉测试中,可以看到酷睿Ultra 9 288V继续领先,而骁龙X1E-78-100仅完成了int8整数的测试,AMD HX 370则不能完成同类测试。

ULProcyon AI图片生成的测试中,酷睿Ultra 9 288V获得了最高的391分,AMD HX 370的分数一半不到,而骁龙X1E-78-100同样没有完成任务。

在7个软件的多个AI典型性测试功能中,酷睿Ultra 9 288V与竞品相比在执行效率上快了58%,在实际应用中,英特尔的x86原生优势是非常明显的。

对于当前的各种AI模型与框架,酷睿Ultra 200V系列在多个项目上已经能够运行最新的模型,而其他模型与框架上的运行效率,正以惊人的速度成长。
这次,英特尔对软件生态与平台体验认真起来了
按以往的节奏,我们讲在讲完处理器的硬件内容之后就会结束,可以看到酷睿Ultra 200V系列的整体硬件提升非常出色,它拥有2.29倍的CPU能效提升,拥有2X的核心显卡能效提升,拥有最高3倍的每线程性能提升,更拥有30%以上的游戏性能提升……但这次,英特尔的新处理器故事包含了一台完整的PC,或者说是一个完整的产业链,在接下来的内容里,我们还为大家继续讲述酷睿Ultra 200V系列的软件生态与平台体验。

首先,我们要明白为何要讲。高通携Arm构架气势汹汹而来,但他首先面临的便是生态问题,要知道,英特尔深耕x86构架的软件生态已经长达45年,自身的开发应用已经普布PC的所有路径之上。特别是近年,英特尔在AI和AI PC上的进拓与进取有目共睹,不仅进行平台型的软件框架开发,而且还大大鼓励AI PC生态的成长。

这强图片包含了巨大的信息,它包含对多种操作系统的支持和100个典型性应用程序,合作跨越1000个软件开发商。它建立在酷睿处理器上不断改进的分层方式,用于提升软件的兼容性——每一代全新处理器都会经过早期披露、案例匹配和架构评估的工作,保证其软件运行的持续稳定性;另外,我们还看到英特尔在软件端的广泛合作,包含英特尔开发者专区、SDK和开发工具包,以及Tiber开发者云平台等;甚至还包含英特尔在市场与渠道端的强大能力,以及各种技术培训与认证。

英特尔正与更多的软件提供商去积极拓展AI体验上的全新驱动、全新功能,从深度与广度上进一步增加AI PC的能力。对于笔记本生态而言,这些软件都能显著提升生产力效率,或改进运行环境稳定性。

平台化一直是英特尔在酷睿处理器上强调的特性,这次在酷睿Ultra 200V系列上,英特尔提供了包含WiFi 7、雷电4、蓝牙5.4、Killer网络连接以及其他连接套件。

在保证高效连接性的同时,英特尔还提供了包含SSE、GSC、CSME、PSE等多个层级上的增强安全性,这是以往在至强处理器上强调的安全特性,英特尔已经逐步下放到个人电脑层面,PSE便是全新应用在酷睿Ultra 200V系列上的新特性。英特尔在安全性上的这些积累,或许日常感受不到,但它能够最大可能提升系统的稳定性。

随着酷睿Ultra 200V系列的发布,英特尔同时公布了全新的Evo认证,认证和项目从笔记本的移动性、智能协作和专项合作三个方面展开,规定了Evo笔记本在续航、散热、静音、性能、无线、外设、NPU支持的音视频等方面展开,并且与将配件计划拓展到24个合作伙伴,新增15种配件,使经过验证的配件总数达到85个以上。

我们还看到,新版Evo的整机验证过程更加苛刻,所有机型都要经过12个月的测试以及与配件厂商、OEM厂商的共同打磨。每个配件在批准、发布之前都要经过预评估、两次预验证和最终验证的过程,可以说是笔记本行业最严格的行业标准,这也意味着每一台Evo笔记本都是值得信任的。
9个SKU为用户提供不同的轻薄本驱动力
相信大家都很关于酷睿Ultra 200V系列的规格清单,可以看到,酷睿Ultra 200V提供了9个SKU,在封装级内存加入处理器、并提供了16GB和32GB两个选项后,处理器的划分更细了,共包含1款Ultra 9、4款Ultra 7和4款Ultra 5,全部为4性能核、4能效核的配置,主要区别在于性能核与能效核的频率,其中Ultra 9的性能核最高可睿频至5.1GHz,能效核则为3.7GHz。
另外,核芯显卡和NPU配置也由高至低拉开了差距,Ultra 9与Ultra 7的核显虽然都是8核配置,但Ultra 9的频率更高,而Ultra 5 则配备了7核核显。NPU的配置从48TOPS一路下行到40TOPS,即使最低型号,也是满足Windows 12 AI性能需求的。

性能释放上,最高的酷睿Ultra 9 288V在基础功耗与其他处理器拉开了差距,定在了17~30W,其他则为8~17W,说明旗舰款的性能明显更强。值得留意的是,他们都围绕着17W这个性能释放甜蜜点展开的。酷睿Ultra 200V的最大睿频功耗都统一为37W,这也是所有SKU的性能释放上限,这一点也是与以往对OEM性能释放上限不加限定不一样的。
写在最后:不论从何种角度来看,英特尔酷睿Ultra 200V系列都是x86构架中最好的移动端处理器,它在配置非常均衡,CPU、GPU和NPU的性能都是同级产品中最出色的。值得一说的是,新一代产品更看重能效比,这也给产品形态带来了更多可能性,除了给轻薄本带来强劲的性能,在掌机等产品形态上更可带来飞跃的性能体验。从处理器构架加速产品进程的演进,英特尔这一波不仅做到了,而且赢麻了。
