
在一个阳光和煦的清晨,李明坐在他的小书房里,面对着满桌子密密麻麻的数学题。
他一边喝着咖啡,一边锲而不舍地研究这些数学问题,却不知道这次的挑战将让许多尖端科技陷入深深的困惑。
李明的书房里,墙上的挂钟悄然敲打着时间,而此时,远在中国科学院的实验室里,全新的数学推理测试正悄然展开。
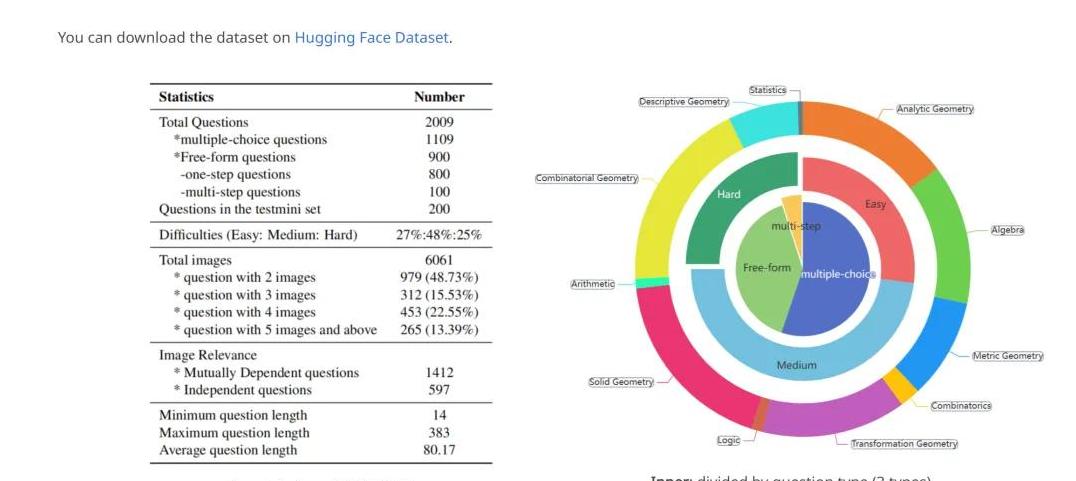
MV-MATH基准测试的创新之处最近,中科院自动化研究所推出了一个名为MV-MATH的创新基准测试。
这是一项专门为评估多模态大语言模型(MLLM)在复杂数学场景中的推理能力而设计的测试。

与以往不同的是,MV-MATH引入了多图视觉场景的概念。
想象一下,在这个基准中,每一个数学问题都伴随着多个图像,文字和视觉信息交织在一起,形成一个全新的复杂场景。
这种设计不仅使测试更加贴近现实世界的应用,还为MLLM在数学推理中提供了额外的挑战。
多视觉场景中的推理挑战李明还记得,最初接触MV-MATH时,他以为这只是普通的数学题,直到发现每个问题都打开了一个新的世界。
这些数学问题不仅考验了大模型的计算能力,同时也挑战了它们在多视觉场景中的整体理解能力。

MV-MATH包含了多项不同的题型,如选择题、填空题和多步问答题,并且每个问题都是基于真实的K-12教育场景。
这给了李明一种回到了学生时代的感觉,但是,这次的难度更高,因为问题的解答不仅需要理解文字,还需分析多幅图像。
数学领域广泛覆盖,难度分级考验进一步探究MV-MATH,李明注意到,它涵盖了多达11个数学领域,包括解析几何、代数、统计学等等。
这些问题被精心设计成不同的难度等级,从简单到困难,全面考验大模型的推理能力。
在实验中,包括GPT-4o在内的多款先进模型尝试解决这些问题,但结果却不尽如人意。
这些看似简单的学习场景,在多种不同难度下,揭示了目前大模型在数学推理中所面临的诸多挑战。
模型与人类能力的对比分析这让李明不禁想到了一个有趣的对比。
虽然技术不断进步,机器在速度和记忆力上几乎无与伦比,但在复杂推理和深度理解上,人类依然有着独特优势。
MV-MATH的数据揭示了一个惊人的事实:尽管那些大模型的整体准确率堪忧,最好的模型在某些领域甚至不及普通人的表现。
这让Hi明开始反思,科技进步是否真的能替代人类在理解问题上的深度。

在对这些问题进行深入分析后,我们发现,视觉信息的阐述方式和信息的互相关联在推理过程中起到了关键性影响。
不仅每幅图像的信息需要被正确理解,还要将不同图像之间的联系进行整合,这种复杂的跨图理解,正是大模型当前面临的最大挑战之一。
随着李明的研究逐渐深入,他开始意识到,MV-MATH不仅是一个具重大挑战的新型基准测试,同时也为MLLM的未来发展提供了激励。
虽然目前的模型在处理多图视觉问题上表现不佳,但这就像是一种“让我们回到起跑线”的提示,提醒我们技术发展需要更广泛的视角和更深刻的理解能力。
在总结这个故事,李明意识到,MV-MATH正在给我们指出一个清晰的方向:机器学习不仅仅是关于速度和效率,更是关于理解力和创造力的不断提升。
以这样的视角展望未来,或许我们会看到一个人与机器和谐共存、彼此共进的动态平衡。

这样不仅使得技术更具人性化,也为人与技术的协作打开了新的可能性。
通过不断挑战和改进,科技的未来承载了无限可能。
