自我纠正(Self-correction)是大语言模型 (LLM) 非常重要的能力,但人们发现这种能力在现代LLM中基本上很少存在。现有的训练自我纠正的方法要么需要多个模型,要么依赖于更强大的模型或其他形式的监督。
我们如何才能让LLM具备自我纠正能力?之前的研究要么依赖于提示工程,要么依赖于专门用于自我纠正的微调模型。但前者通常无法有效地进行有意义的内在自我纠正,而后者基于微调的方法需要在推理时运行多个模型,例如需要oracle「教师」来监督指导自我纠正过程。
在最近提交的一篇论文中,来自Google DeepMind的研究者开发了一种无需上述任何要求即可有效进行自我纠正的方法,即通过强化学习进行自我纠正(SCoRe,Self-Correction via Reinforcement Learning),只需训练一个模型,该模型既可以对推理问题做出响应,也可以纠正错误,尽管没有收到任何oracle反馈。更重要的是,SCoRe完全通过在自生成数据上进行训练来教模型具备这种能力,而无需任何oracle。
 论文标题:Training Language Models to Self-Correct via Reinforcement Learning论文地址:https://arxiv.org/pdf/2409.12917
论文标题:Training Language Models to Self-Correct via Reinforcement Learning论文地址:https://arxiv.org/pdf/2409.12917本文主要贡献在于提出了一种多轮强化学习方法——SCoRe,用于教LLM如何纠正自己的错误。相对于基础Gemini模型,SCoRe在MATH推理问题的自我纠正方面获得了15.6%的增益,在HumanEval编码问题上获得了9.1%的增益。
SCoRe原理介绍
为了教LLM进行自我纠正,SCoRe将标准单轮强化学习(公式2)扩展到Zhou等人提出的分层框架下的多轮设置。

不过这样做面临诸多挑战。首先,优化公式1解决了分布偏移问题,但尚不清楚它是否也能满足要求 [D2]。

这里的 [D2] 如下图所示,图中展示了SFT方法失败的两个原因。而有效的解决方案必须满足两个要求:[D1] 模型应该直接在自生成轨迹上进行训练,以缓解SFT的分布不匹配(图4),[D2] 所采用的自生成轨迹应防止在学习过程中因进行微小编辑而崩溃。
作者开发了一种在线RL方法,通过仔细的初始化和奖励塑造来解决这些挑战。


其次用于微调的基础模型初始化在编辑距离上呈现出高度倾斜的分布(图 3a),这使得它们容易受到模式崩溃的影响,这是深度强化学习中一个常见的问题。即使基础模型可以在自我校正过程中产生编辑距离比倾斜度较小的分布,但仍然需要强化学习训练过程从训练数据中学习一种可以推广到测试提示的自我校正策略。

SCoRe旨在解决上述关键挑战,其分为两个阶段,这两个阶段都是通过适当初始化模型和控制后续RL使模型偏向学习自我纠正。
具体而言,这两个阶段包括:
阶段I:训练模型初始化以防止崩溃
SCoRe第一阶段的目标是通过提高基础模型对第二次尝试响应的覆盖率来获得良好的模型初始化,以便后续自我纠正训练不会出现STaR/SFT中观察到的崩溃现象。
为了达到此目的,该研究不采用SFT来初始化RL训练,而是开发了第一阶段来产生不易崩溃的单独初始化。
作者微调基础模型,以便在第二次尝试时产生高奖励修正,同时通过使用KL散度将第一次尝试的响应分布限制为尽可能接近基础模型的响应分布,从而强制模型不改变其第一次尝试的响应。虽然这看起来不是最优的——但第一次尝试的响应错误较少,可以纠正为更好的第二次尝试响应。优化的目标可以表示为:

其中_2是一个超参数,旨在仅在第一次尝试时强制执行严格的KL惩罚,以避免第一轮响应发生偏移(用蓝色项表示)。请注意,作者仍然使用公式2中的默认KL散度惩罚,但该惩罚的权重要小得多,并且为了简洁起见,公式3中省略了它。事实上,与简单的多轮RL不同,阶段I在分离两个响应方面更有效(图5b)。

阶段II:带有奖励的多轮强化学习
借助第一阶段的模型初始化,该模型在耦合两个响应时表现出更小的偏差,SCoRe的第二阶段现在可以训练两次尝试的响应,并根据公式1优化奖励。当然,作者还希望确保在此过程中不会降低第一次尝试的响应。因此,对于两轮自我纠正问题,作者针对以下目标训练策略_(⋅∣⋅):

图6为阶段I、阶段II流程说明。可以看出SCoRe以交错方式应用阶段I和II进行多次迭代。


实验评估
该研究进行了一系列实验,来验证SCoRe在教LLM具备自我纠正能力方面的有效性,并通过消融实验探索了SCoRe的每个组件的影响。
该研究主要关注数学和编码任务,使用以下基准来评估方法的有效性:
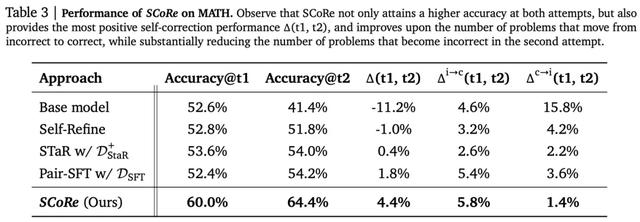
MATH;MBPP和HumanEval。几种方法在MATH基准上的实验评估结果如下表3所示:
在代码生成方面,实验结果如下表4所示:

消融研究
为了探究以下几个问题,该研究进行了消融实验:
多轮训练的重要性多阶段训练的重要性奖励函数设计(reward shaping)的影响on-policy强化学习的重要性消融实验结果如下表5所示:

--机器之心
