
在月亮的暗面,闪闪发光。
作者丨郑佳美
编辑丨陈彩娴
2025 年 1 月 20 日 Kimi k1.5 正式发布,伴随着技术报告的公布,有网友表示:“这应该是全球范围内,除 OpenAI 之外的公司首次实现 o1 正式版的多模态推理性能了吧!”
一时间,Kimi k1.5 成了话题王者。
但在一个月后的 2 月 24 日,X 上出现了一篇关于 Kimi k1.5 的技术爆料帖,博主直言 k1.5 所用到的强化学习算法,其实是借鉴了自己在 24 年 5 月提出的一种名为 SPPO 的技术。
消息一出,瞬间吸引了数万人关注。

在这则爆料中,博主 Yue Wu 先是对 SPPO 进行了简单解释,并且附上了相关论文(https://arxiv.org/abs/2405.00675),简单来说,SPPO是一种自博弈算法,最初的动机来源于刻画广泛意义上的人类偏好,并且使用了如下图所示的平方损失函数:

值得一提的是,点开论文链接,你会发现原来 Yue Wu 和 Zhiqing Sun 同为这篇文章的第一作者。

紧接着,他开始对 SPPO 技术进行解析:
通过迭代求解上式中的 theta_t,我们可以得到一个与人类偏好对齐良好的语言模型。SPPO 使用胜率(红色部分)作为奖励,并用常数近似基线(蓝色部分)。
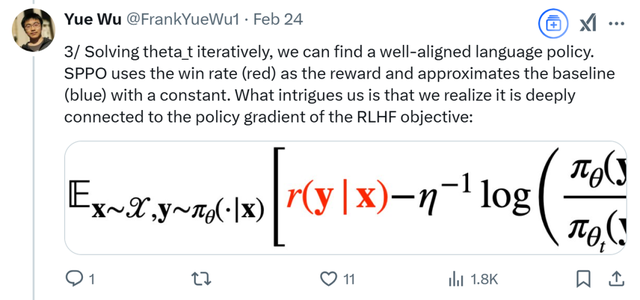
让我们感兴趣的是,我们发现它与 RLHF 目标的策略梯度有着深层的联系:如果我们直接用普通的策略梯度优化 RLHF (人类反馈强化学习)目标会怎样?根据策略梯度定理,策略梯度实际上也具有平方损失形式(蓝色项是策略梯度中的基线):

从数学上,我们证明了 SPPO 的平方损失等价于普通策略梯度的一种半在线变体:
SPPO 中的胜率充当奖励函数(红色部分)。
分区函数项自然地成为(软)值函数(蓝色部分)。

那么这到底意味着什么呢?
标准策略梯度(PPO、GRPO、REINFORCE)在每一步都收集遵循当前策略的样本。
SPPO 在每次迭代开始时只采样一次,然后通过平方损失进行优化。
这使得 SPPO 成为一种轻量级的 RLHF 方法——无需即时生成!

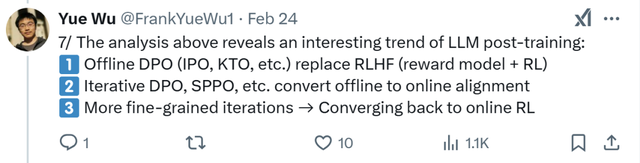
上述分析揭示了大型语言模型(LLM)后训练阶段一个有趣的发展趋势:
离线 DPO(IPO、KTO 等)取代 RLHF(奖励模型 + 强化学习)
迭代 DPO、SPPO 等方法将离线方法转化为在线对齐方法
更加精细的迭代 → 回归到在线强化学习
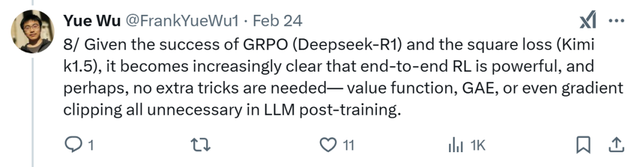
鉴于 GRPO(Deepseek-R1)和平方损失(Kimi k1.5)的成功,端到端强化学习的强大作用愈发凸显,或许在大型语言模型(LLM)后训练阶段无需额外技巧——价值函数、广义优势估计(GAE),甚至梯度裁剪都无需使用。
另一个简单但有趣的发现是,他们发现 SPPO 暗中在词汇级别优化最优最大熵策略。其平方损失隐含地最小化了学习到的策略与最优词汇级别策略之间的 KL 散度。
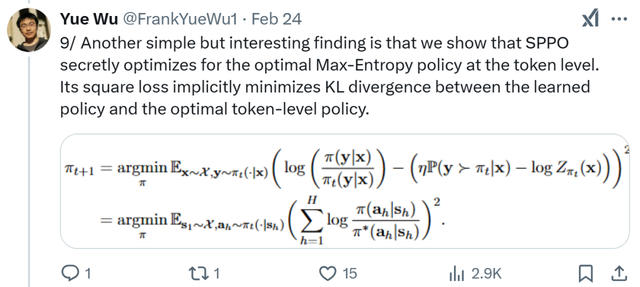
在我们后续的研究 GPO 中,我们直接最小化相对奖励与对数比率之间的平方损失。这两项工作中的平方损失等价于策略梯度,但它是以迭代的方式进行的。
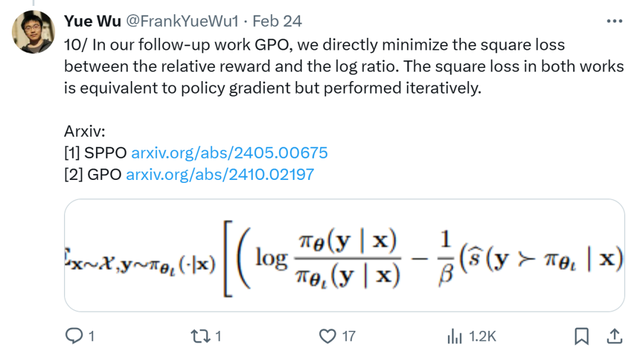
 除此之外,2023 年至今他一共参与发布了 9 篇 Paper,其中 3 篇均为第一作者。
除此之外,2023 年至今他一共参与发布了 9 篇 Paper,其中 3 篇均为第一作者。 强大的学术背景之外,Wu Yue 的实习经历也非常加分。2022 年至 2024 年,他分别在 NEC 美研院、字节美国 AI lab和 Meta 工作实习。在 NEC 美研院期间,Wu Yue 从事个性化联邦学习研究,并开发了一种基于混合模型的方法,该方法被 ICML 2023 接受发表;在字节美国 AI lab 时,他专注于药物发现领域的多构象生成,将分子动力学的物理先验纳入基于扩散的生成模型,相关成果被 ICML 2024 接受;来到 Meta 后,Wu Yue 又致力于词汇级别奖励建模和新架构设计,用于一般人类偏好和一般偏好优化,为生成式人工智能的发展做出了贡献。
强大的学术背景之外,Wu Yue 的实习经历也非常加分。2022 年至 2024 年,他分别在 NEC 美研院、字节美国 AI lab和 Meta 工作实习。在 NEC 美研院期间,Wu Yue 从事个性化联邦学习研究,并开发了一种基于混合模型的方法,该方法被 ICML 2023 接受发表;在字节美国 AI lab 时,他专注于药物发现领域的多构象生成,将分子动力学的物理先验纳入基于扩散的生成模型,相关成果被 ICML 2024 接受;来到 Meta 后,Wu Yue 又致力于词汇级别奖励建模和新架构设计,用于一般人类偏好和一般偏好优化,为生成式人工智能的发展做出了贡献。 而与他同为第一作者的 Zhiqing Sun ,目前已经从 CMU 毕业,并在今年 2 月加入 OpenAI。
而与他同为第一作者的 Zhiqing Sun ,目前已经从 CMU 毕业,并在今年 2 月加入 OpenAI。
参考链接:https://x.com/FrankYueWu1/status/189385002391950553
论文链接:https://arxiv.org/pdf/2405.00675

未经「AI科技评论」授权,严禁以任何方式在网页、论坛、社区进行转载!
公众号转载请先在「AI科技评论」后台留言取得授权,转载时需标注来源并插入本公众号名片。
//为什么中国只有一个 DeepSeek?
谁将替代 Transformer?
Andrej Karpathy 最新视频盛赞 DeepSeek:R1 正在发现人类思考的逻辑并进行复现

