
在某个春日的傍晚,技术爱好者小李正坐在咖啡店角落,他的朋友小王带着些许兴奋神情凑过来说:“你听说过那个新的xLSTM吗?
听说改造后比Mamba快了50%!
这到底是什么操作啊?”

小李撇了一眼自己屏幕上滚动的信息流,满是各种科技新词,他挠了挠头,“这世道,还能跟上吗?”小王则俨然成了行家,开始聊起xLSTM的故事。
回归经典:xLSTM与Transformer的对比
要弄清xLSTM,我们先来聊聊热门的Transformer模型。
自从Transformer一亮相,几乎成了诸多语言模型的模范代表。
不过,Transformer在处理长文本时,计算量是会迅速增大的,像小李平时打开上百页的PDF,这种情况下就有点儿力不从心。
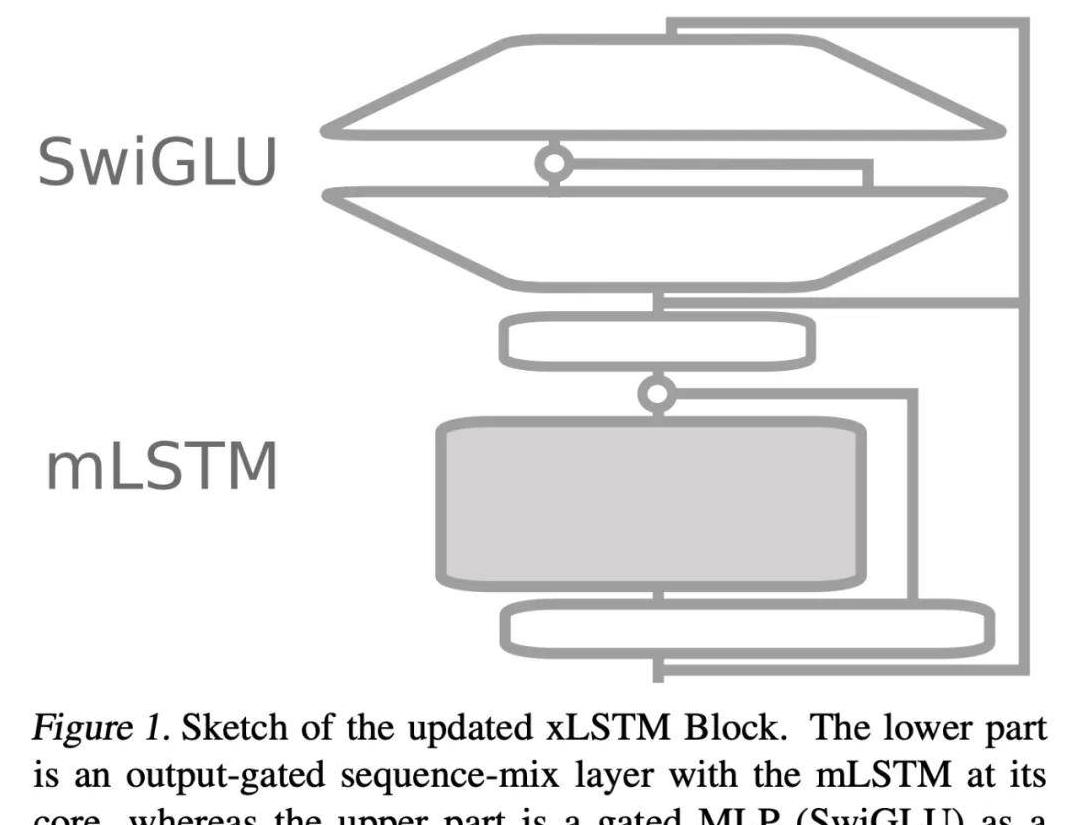
而xLSTM呢,是从90年代一种叫LSTM的算法演化而来的版本,有人调侃它是靠“祖传秘方”翻红。
xLSTM有个好处,就是它在处理越长越复杂的文本时,计算量增长得比较舒缓,这就好比有人在登山,走得稳重而不是一路狂奔。
优化的背后:mLSTM的关键角色
听完这些,小李有点明白了,但真正让xLSTM被推上风口浪尖的,是背后的优化机制——mLSTM。
小王接着说,其实优化xLSTM还真是一项复杂的工程。
为了让它跑得又快又稳,开发团队对它的小脑袋,嗯,也就是mLSTM模块,做了不少局部整修。

想象一下,要让一块大型机械在尽可能低的耗能下高效运转,关键还是要精简内部结构,比如少装些“花哨”的齿轮。
而这一次优化就成功让xLSTM在同等计算能力下,显著降低了内存需求,能够更快速地处理数据。
贴近边缘:速度与内存的优化
在生活中,我们可能未必实时接触到这些模型的性能如何,但小李一直好奇它们背后用于什么场景。
大概是为了某种类似人机对话的智能助手应用吧?
小王略带神秘地说,其实这些模型还真是在向着个人设备靠拢,现在的优化确保了xLSTM在小设备运行时占的内存更少。

想象一个日常对话情境:你对着智能音箱抱怨晚餐没有灵感,xLSTM迅速处理完你的输入,不用等音箱“嘿嘿”半天。
长文本处理的挑战与突破当然,最长的“文章”未必是它跑得最快的动力。

xLSTM引以为豪的,还有它面对长文本时的稳定表现。
在对复杂文章的分阶段训练中,学会了“耐下心来看完每一个字”的本事。
正如小王水上听讲座时忍耐力训练,也因耐心看完长篇文章,抓住了些许研究中的“机灵窍门”。

结尾时,小李若有所思。
他意识到,科技即使不断迭代创新,本质却没变:我们是在学习如何更智慧地看待和处理浩繁的信息。
xLSTM的加入并非要取代谁,而是在繁杂内存里寻求更简洁的路径。

正如生活中每一次革新,每个瞬间都蕴含着丰富可能,是否能把握,取决于你是否选择向自己挑战。
小王笑着戏谑道:“所以,这次改造挺像在给xLSTM修个小圣殿。”
小李点头,心想那要真是个圣殿,里面的一草一木岂能不细细打量呢?
随着夜色渐深,小李和小王各自走向了自己的思绪,仿佛这xLSTM引发的探讨给了他们对技术的重新思考:科技是新的时间轴上让人不断成长的伙伴,了解一点求知着一点,不是为了炫耀,而是为了探索发现中更好理解自己。
