
超万卡集群建设方兴未艾,当前主要依托英伟达GPU及其设备。英伟达GPU在大模型训练中表现卓越,但国产AI芯片虽进步显著,性能与生态构建仍存差距。面对诸多挑战,构建技术领先、基于国产生态的超万卡集群,仍需不断突破与创新。
大模型升级至万亿参数多模态,超万卡集群需强化底层算力。关键在增强单芯片性能、提升超节点计算力、DPU驱动的多算力融合及追求算力能效极致。欲知详情,请参阅“超万卡训练集群互联关键技术”。
1、超万卡集群核心设计原则
大算力与大数据驱动大模型构建,超万卡集群搭建需超越单纯算力堆叠。为确保数万GPU高效协同如“超级计算机”,集群设计需遵循五大核心原则,引领行业创新。
倾力打造巅峰集群算力:通过Scale-up互联提升单节点算力极限,结合Scale-out互联实现万卡级集群规模,铸就超万卡集群的卓越算力基石,引领行业算力革命。
构建协同调优系统,凭借超大规模算力集群,运用DP/PP/TP/EP等并行训练策略,提升有效算力,优化计算通信比,确保模型开发效率达到巅峰。
实现长稳可靠训练,我们拥有自动检测和修复软硬件故障的技术,针对千万器件满负荷系统,不断增强MTBF、缩短MTTR,并具备断点续训功能。支持百亿级稠密、万亿级稀疏大模型百天稳定训练,确保系统稳定、鲁棒性强。
我们致力于提供灵活的算力支持,支持集群算力调度,实现资源按需调配,确保单集群大作业和多租户多任务并行训练性能卓越,保障算力供给的灵活性与高效性。
推动绿色低碳发展,深化全套液冷方案在超万卡集群应用,实现绿色算力能效比(FLOPs/W)最大化,液冷PUE值低于1.10,助力环保高效计算新时代。
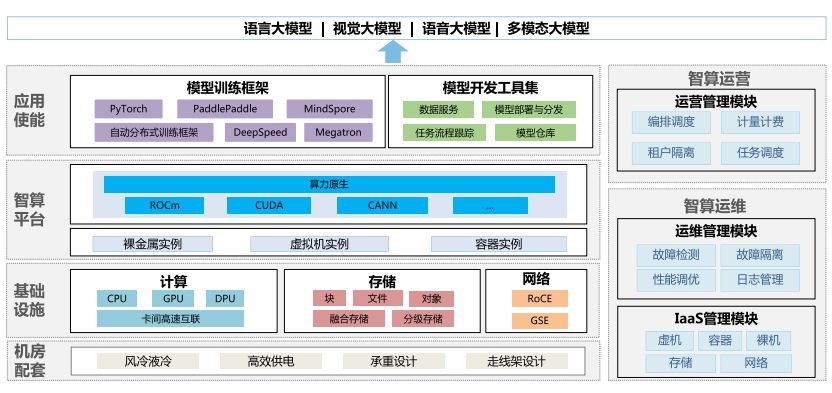
2、超万卡集群整体架构设计
超万卡集群架构独特,涵盖机房配套、基础设施、智算平台、应用使能四层,并融合智算运营与运维域,实现高效智能运维。

机房配套层专为超万卡集群高密集约设计,强调高效供电、先进制冷、承重楼板与走线架优化,确保集群稳定运行。
基础设施层精准融合算、网、存三大硬件资源,实现集群算力最大化。CPU、GPU、DPU芯片协同工作,释放集群计算潜力;独立组网的参数面、数据面、业务面、管理面,搭配RoCE交换与CLOS组网技术,确保高速数据传输与多租隔离;融合与分级存储技术,实现无阻塞数据并发访问,全面优化集群性能。
智算平台层依托K8s,提供裸金属与容器集群资源,实现集群资源高效纳管与大规模集群的自动化精准故障管理,确保高效训练与稳定运行。未来,将引入异厂家GPU芯片,通过算力原生技术,解决智算碎片化问题,实现应用跨架构迁移与异构混训,展现平台卓越能力。
应用使能层融合模型训练框架与开发工具集,借助开源框架实现分布式训练优化,并前瞻设计自动分布式训练框架。通过通信与计算优化、算子融合及网络性能调优,提升效率。同时,研发数据服务与模型部署工具,实现从人工到自动化的模型研发能力转型,提升研发效率与精准度。
智算运营与运维域:高效支持万卡集群通信与调度,灵活资源分配与任务调度,支持多任务并行训练,助力高效运维。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-
