凭借优秀的应用表现,DeepSeek(深度求索)已经成为全民皆知的一款现象级大语言模型。如果只想简单地体验DeepSeek,用户使用网上在线客户端就能运行,比如由超算互联网推出的DeepSeek在线对话网页(https://chat.scnet.cn/#/home)。不过在线使用DeepSeek的问题是如果用户数过多,可能出现服务器无响应、等待时间过长的问题,而且还存在泄露隐私的风险。所以如果用户的电脑硬件具有较好的技术性能,那么还是可以将DeepSeek部署在本地硬盘上,让它成为只供自己使用的“私人工具”。那么对普通用户来说,应该如何在电脑上部署DeepSeek呢?

▲DeepSeek(深度求索)现在已经成为受全民追捧的大语言模型,用以解决用户在工作生活中遇到的各种问题。
需要使用高性能显卡与存储系统目前要在本地使用DeepSeek,首先需要用户的电脑硬件具有较好的技术规格。最为重要的就是显卡,通过显卡来运行DeepSeek,可以让DeepSeek具有更高的词元生成速度,更低的思考时间,简单来说,就是回答问题的速度更快。而且显卡性能越强,就能运行参数量更大的模型,模型参数越大,其能处理的任务就更多,解答更准确。一般而言,我们推荐使用GeForce RTX 3060级别的显卡运行DeepSeek R1 7B、8B模型(注:B即英文billion 10亿的缩写);推荐GeForce RTX 4080/5080级别的显卡运行DeepSeek R1 14B模型;推荐GeForce RTX 4090/5090 D级别的显卡运行DeepSeek R1 32B模型。而70B及更多参数的模型则推荐使用GeForce RTX 4090 /5090 D或NVIDIA A100多卡系统。当然以上只是推荐配置,很多情况下,用户的显卡即便没有达到推荐等级也是可以运行这些模型的,只是运行速度较慢而已。

▲不同参数量的DeepSeek R1模型推荐显卡
其次就是存储系统,存储系统对DeepSeek至关重要。因为在本地电脑使用的话,用户需要将DeepSeek大语言模型下载到自己的硬盘上,各类DeepSeek R1模型的容量并不低。其中DeepSeek R1 14B的最大容量可以达到15.7GB左右,DeepSeek R1 32B的最大容量可达34.82GB,DeepSeek R1 70B的最大容量可达74.98GB。要使用这些模型需要用户有一块较大容量的硬盘来存放,性能还得够强。

▲该图为运行传统游戏时的数据流动方式,需将数据从SSD传输到内存、CPU与显存。
因为运行DeepSeek时,其负载主要由GPU与CPU执行,所以数据的流动方式就像上图运行传统游戏时,需要将模型的大部分内容从SSD读取到系统内存中,再将需要处理的数据传输给CPU,分配给GPU进行运算的数据,则由内存交给显存供GPU读取进行运算。因此要想CPU、GPU高效地工作,负责传送数据的SSD与内存就必须具备优秀的性能。特别是担当数据传输第一棒的SSD,它必须具备足够快的数据传输速度,能在短时间内将数据发送到内存,CPU、GPU才能尽早地收到数据,并开始工作。
最终在使用效果上的呈现,就是高性能SSD可以缩短加载模型的耗时,解答问题更快即带来更高的Token/s词元生成速度。因此用户最好将DeepSeek部署在高性能SSD上,比如传输速度在7000MB/s左右的满速PCIe 4.0 SSD,如果预算充足,将它部署在速度可达10000MB/s~15000MB/s的高端PCIe 5.0 SSD上则是更好的选择。
最后,在硬件上更为重要的一环就是需要用户配备容量足够大、速率尽可能高的内存。系统载入模型时有可能使用相当于与该模型容量一样的内存容量,特别是在没有开启GPU加速时。此外在显卡性能不够,只能部分开启GPU加速,运行大参数模型时,也会占用大量系统内存。因此,从最坏情况与留有余量的角度情况考虑,如果你要运行最大15.7GB的DeepSeek R1 14B模型,那么至少得配备32GB内存,如果要运行最大为34.82GB的DeepSeek R1 32B模型,48GB内存是电脑运行它的门槛,要运行最大74.98GB的DeepSeek R1 70B模型,最低96GB的系统内存必不可少。

▲加载参数高、容量大的模型会带来较大的内存占用,图为拥有48GB内存的电脑载入最轻量级70B模型后的内存占用情况。
使用LM Studio让你快速完成DeepSeek本地部署如果你的硬件性能足够强大,接下来就可以着手开始部署DeepSeek,我们将在基于48GB内存的硬件平台上为大家说明如何部署DeepSeek。首先,用户需要安装LM Studio或Ollama任一种大语言模型开发和应用软件平台。两种平台的安装都非常简单,不过鉴于Ollama原生提供的是命令行显示界面,因此完全以图形化界面显示的LM Studio对没有接触过代码或缺乏计算机软件知识的用户更加友好,而且它还能将语言设置为中文。所以在本篇文章中,我们将以LM Studio为核心向大家进行介绍。
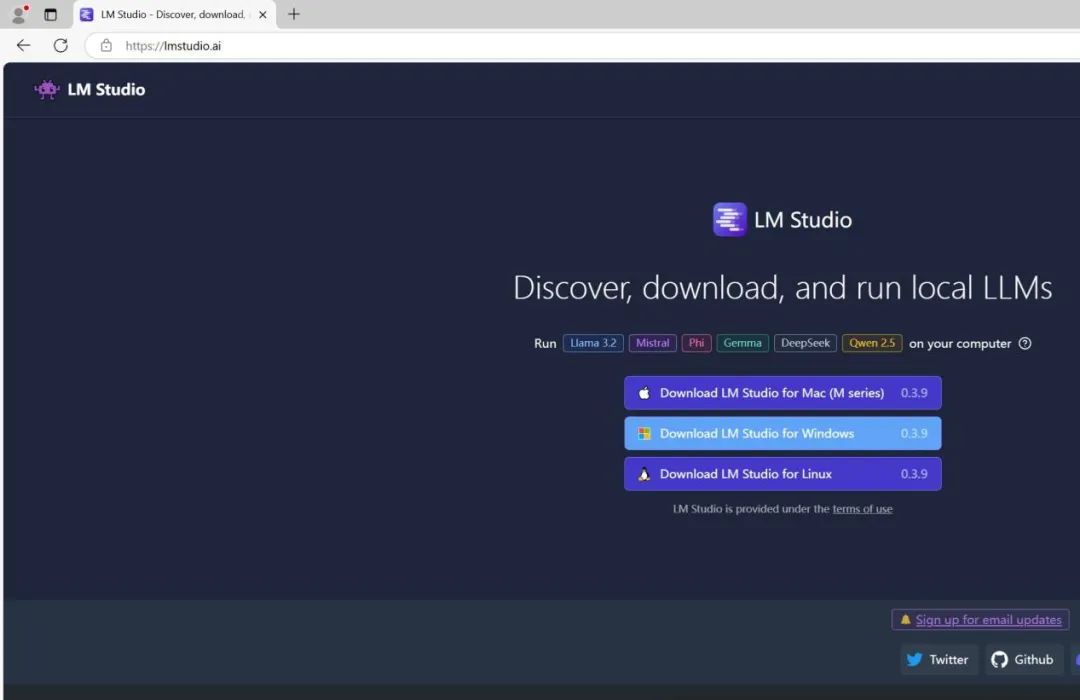
▲在网站https://lmstudio.ai/下,可直接下载LM Studio Windows版本。
网站https://lmstudio.ai/下,可直接下载LM Studio Windows版本。" 1551ae2b"="">网站https://lmstudio.ai/下,可直接下载LM Studio Windows版本。" 57b9769b"="">网站https://lmstudio.ai/下,可直接下载LM Studio Windows版本。" uploaded="1" data-infoed="1" data-width="1080" data-height="700" data-format="jpeg" data-size="38112" data-phash="CBF7B4894A548B89" data-source="outsite" outid="undefined">LM Studio的安装很简单,在网站https://lmstudio.ai/下载其Windows版本软件,双击运行并选择安装的文件夹点击“Next”即可。不过LM Studio里并没有内置DeepSeek模型,还需要用户在LM Studio中进行下载。首先在软件的“APP SETTING”中将“Language”(语言)切换为“简体中文”(注:部分功能选项仍使用英文显示),再在“常规”中勾选“Use LM Studio's Hugging Face Proxy”,即使用Hugging Face公司的代理服务器下载模型,这样你就能方便、快速地下载模型。
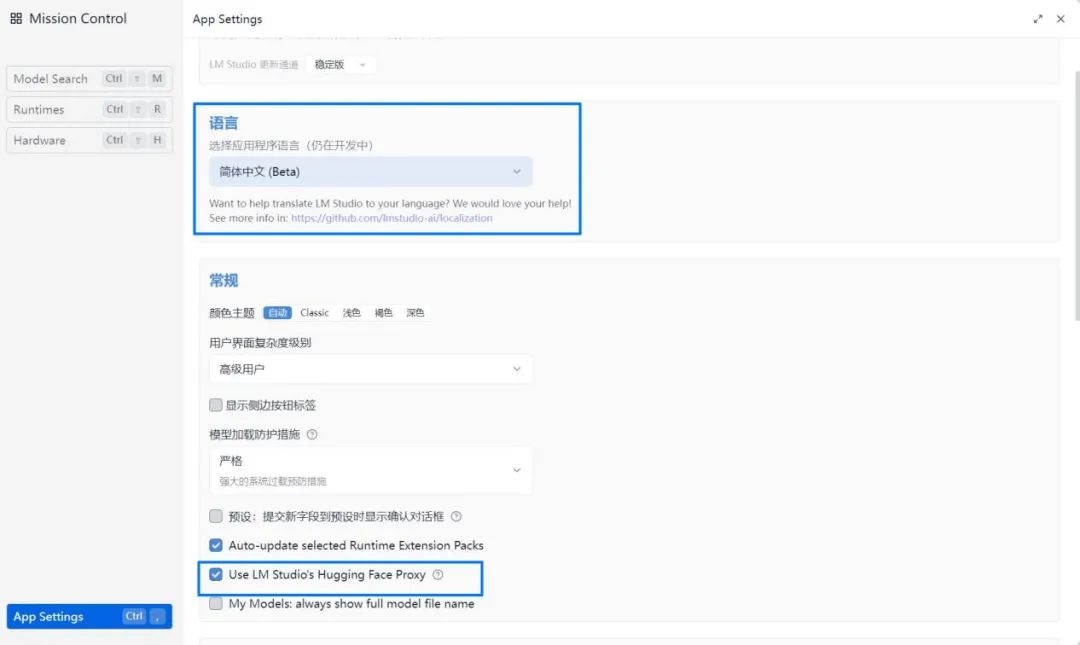
▲使用LM Studio之前,用户需将语言设置为“简体中文”,并启用“Use LM Studio's Hugging Face Proxy”(用Hugging Face公司的代理服务器下载模型)。
需要的模型在哪里呢?点击LM Studio软件左侧的“发现”,输入“DeepSeek”,你就能发现很多参数数量不同、容量不等的DeepSeek模型。每个DeepSeek模型后都有一个特殊的标识。其中有小火箭标识的说明你的显卡在运行该模型时可以进行完全加速,能达到最佳运行速度,而有小方块标识的则表示你的显卡只能对该模型进行部分加速。至于标有“可能对本机来说太大”的模型,则意味着你的电脑内存不足,无法运行它,没有必要下载。因此一般使用时,用户最好选择拥有小火箭标识,参数最多、容量最大的模型。如果想尝鲜体验更复杂的模型,则可以下载有小方块标识的模型。
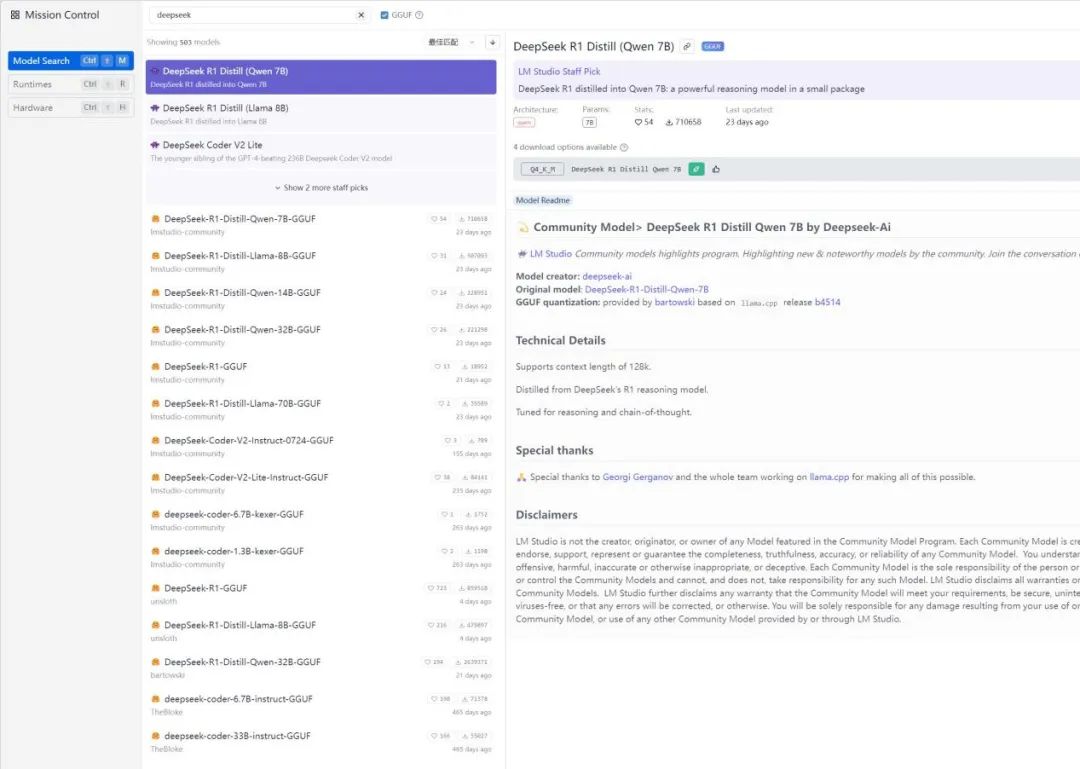
▲点击“发现”,可以看到大量DeepSeek模型提供下载。
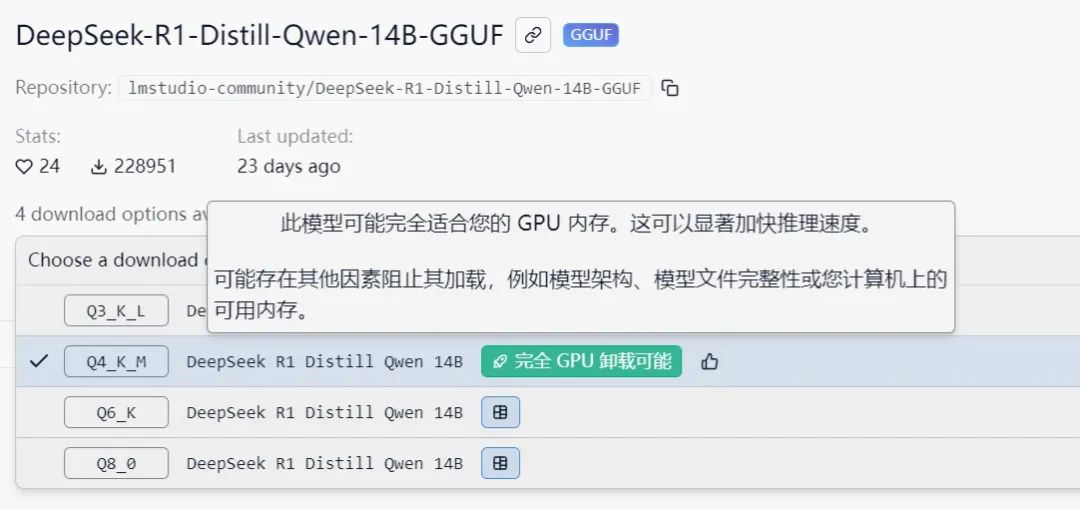
▲拥有小火箭标识的模型,说明用户电脑的GPU在运行该模型时可以完全加速。
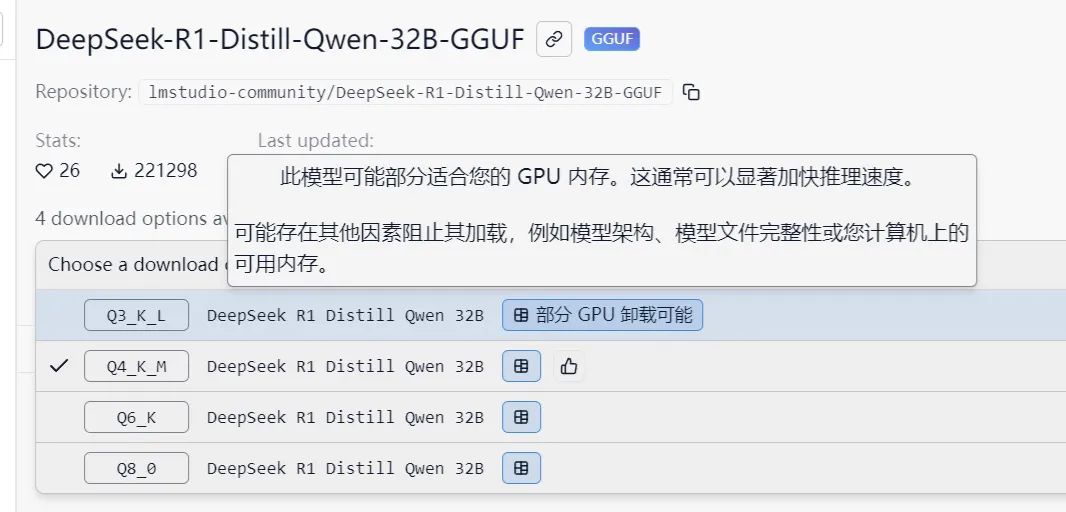
▲拥有小方块标识的模型,则说明所用电脑的GPU在运行该模型时,只能部分加速。
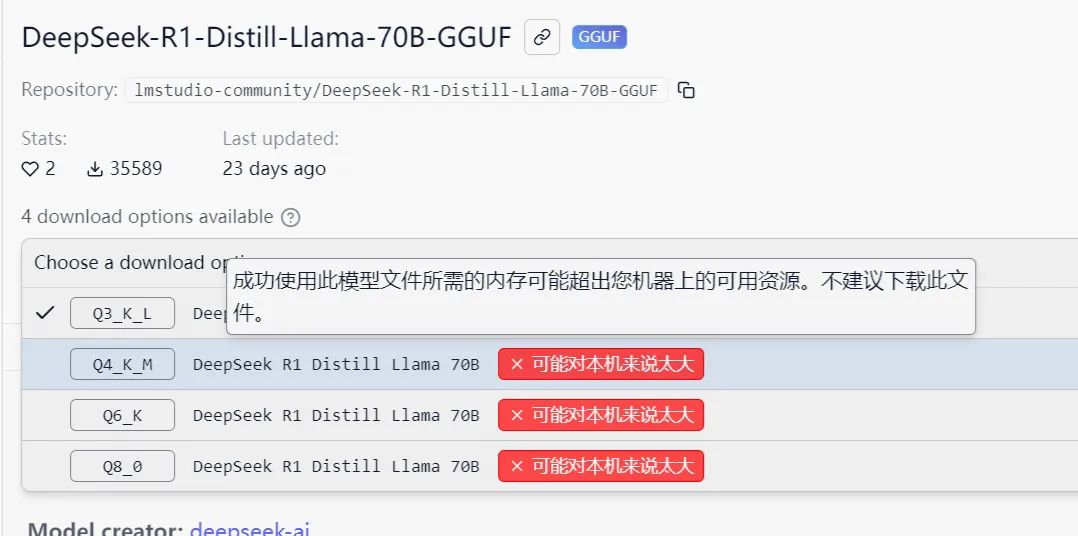
▲标注“可能对本机来说太大”标识的模型,则意味着所用电脑内存不足,无法运行,没有不要下载。

▲模型下载完成后,点击“选择要加载的模型”,就能使用DeepSeek。
下载完模型后,用户就能在LM Studio软件的上方点击“选择要加载的模型”,选择下载好的模型即可使用。是不是非常简单?去掉软件与模型的下载时间,基本只花1~2分钟,大家就能用上DeepSeek。为了让模型在使用时拥有更高的执行效率,我们在加载模型时还可以对模型选项进行微调,比如将“GPU卸载”“CPU Thread Pool Size ”(CPU线程池尺寸)向右拉满,使显卡、处理器能调用最多的计算资源来运行模型,特别是在那些拥有小火箭标识,可以完全加速运行的模型中,再打开“快速注意力”选项,可以减少内存占用和生成时间。
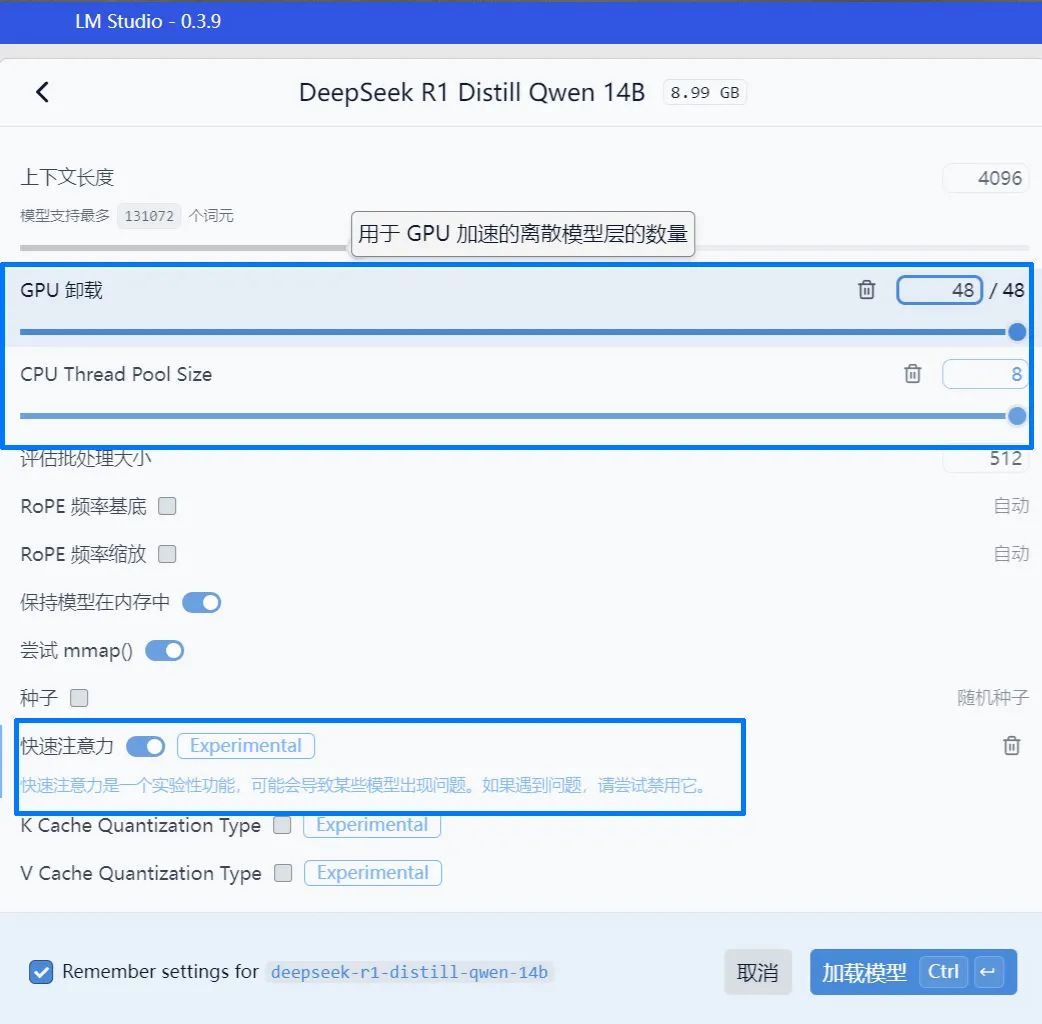
▲对于拥有小火箭标识的模型,用户可以尝试在模型选项中将“GPU卸载”“CPU Thread Pool Size ”向右拉满,并打开“快速注意力”选项。
DeepSeek体验基于致态TiPro9000 SSD 2TB的 PCIe 5.0平台表现最佳完成DeepSeek R1模型部署后,接下来就让我们看看该模型的运行效果,尤其是近期大量PCIe 5.0 SSD新品上市,NVIDIA GeForce RTX 50系显卡接踵而至,在这些新硬件上运行DeepSeek R1是否能带来更好的体验呢?
DeepSeek体验平台
主板:ROG MAXIMUS Z790 DARK HERO
处理器:酷睿i9-14900K
内存:DDR5 7200 24GB×2
硬盘:长江存储致态TiPro9000 PCIe 5.0 SSD 2TB、满速PCIe 4.0 SSD 2TB
显卡:GeForce RTX 5080、GeForce RTX 4080
电源:be quiet! Dark Power Pro 13 1600W ATX 3.0
操作系统:Windows 11
为此我们特别采用长江存储最新推出的致态TiPro9000 PCIe 5.0 SSD分别搭配GeForce RTX 5080显卡,上一代GeForce RTX 4080显卡进行测试,并与基于满速PCIe 4.0 SSD 2TB(注:最高传输速度超过7400MB/s),分别搭配GeForce RTX 5080显卡、GeForce RTX 4080显卡的平台进行了对比。

致态TiPro9000 PCIe 5.0 SSD采用先进的PCIe 5.0 x4 SSD方案,支持多达8个NAND闪存读写通道,32CE片选信号,并符合NVMe 2.0标准。更为关键的是,它板载了性能更强,基于长江存储晶栈Xtacking 4.0架构的原厂TLC颗粒。为了充分释放SSD的性能,致态TiPro9000 SSD还采用独立缓存设计。比如本次使用的2TB产品配备了2GB独立缓存,用于存放记录数据位置的FTL映射表。SSD的读写操作都需要查询这张记录表,要想读写速度快,就需要把这张映射表存放在高性能的DRAM内存颗粒中,从而有效提升SSD的读写性能。目前致态TiPro9000 PCIe 5.0 SSD有1TB、2TB两种容量供用户选择。质保方面,这款产品拥有5年质保加写入数据量的质保政策(以先到为准),其1TB、2TB产品的TBW质保可写容量分别为600TB、1200TB,与其他高品质SSD相当。

▲包装内部由致态TiPro9000 SSD、可拆卸式散热器与一把微型螺丝刀组成。
致态TiPro9000 PCIe 5.0 SSD 2TB的标称顺序读写速度分别为14000MB/s、12500MB/s,随机读取性能为2000K IOPS。而《微型计算机》的实测结果更让人惊喜,致态TiPro9000 SSD 2TB的顺序读取速度可达14528.79MB/s,顺序写入速度为13914.89MB/,随机读取性能高达2158K IOPS,均大幅超过标称规格,远远好于大部分传输速度在7500MB/s以内的PCIe 4.0 SSD。

▲致态TiPro9000 SSD 2TB的CrystalDiskMark测试结果超过标称规格,大幅领先于普通的PCIe 4.0 SSD。
此外,致态TiPro9000 SSD 2TB在PCMark 10存储性能的得分则达到了超高的6377分,其平均传输带宽为1008.64MB/s。这是什么概念呢?在《微型计算机》之前的测试中,大部分PCIe 4.0 SSD在该测试中只能获得3500分左右的成绩,传输带宽不到600MB/s。这说明在致态TiPro9000 SSD生产力软件应用上能更快地读写数据,更适合进行专业应用。而致态TiPro9000 SSD 2TB的1649元的价格却比其他相同容量的一线品牌PCIe 5.0 SSD便宜,更具性价比。

▲致态TiPro9000 SSD 2TB的PCMark 10完整系统盘性能测试成绩高达6377,这也是PCIe 4.0 SSD难以企及的高度。
那么基于致态TiPro9000 SSD 2TB的PCIe 5.0 SSD测试平台在使用DeepSeek时,可以带来怎样的使用效果呢?测试中,我们首先在每一个平台上载入容量为8.37GB的DeepSeek R1 Dstill Qwen 14B模型,并提出一个“请规划一个重庆五日游”的问题,从而测试其tokens/s词元生成性能。该模型也是本次测试平台上所能进行完全加速的最大模型,从测试结果来看,四个平台的数值差异不大,但区别仍然存在。


▲本次测试中,致态TiPro9000 SSD 2TB+GeForce RTX 5080的组合拥有最快的词元生成速度。
简单来说就是致态TiPro9000 SSD 2TB与GeForce RTX 5080的组合拥有最高的性能表现,其词元生成速度可以达到53.45tokens/s,而且强于也使用GeForce RTX 5080显卡,但基于满速PCIe 4.0 SSD 2TB的平台,后者的词元生成速度为51.78tokens/s,致态TiPro9000 SSD 2TB+GeForce RTX 5080的组合小幅领先3.2%。在换用GeForce RTX 4080显卡后也有类似的结果,致态TiPro9000 SSD 2TB搭配GeForce RTX 4080的词元生成速度为50.77tokens/s,而满速PCIe 4.0 SSD 2TB搭配GeForce RTX 4080的词元生成速度为50.2tokens/s,使用致态TiPro9000 SSD 2TB也能带来1.1%的性能提升。我们推测原因在于像致态TiPro9000 SSD 2TB这样的PCIe 5.0 SSD可以更快地向内存传输数据,因此处理器与GPU可以更有效率地执行负载,生成的词元数量要略多一点。同时我们也测试了各平台在加载大容量模型时,加载时间是否有差异。


▲加载34.59GB的70B模型会比加载8.37GB的14B模型更耗时,后者的加载时间只有7s左右。
我们将在每一个平台加载容量为34.59GB的DeepSeek R1 Dstill Llama 70B模型,这也是本次测试平台所能加载的最大模型。模型调节项目全部使用默认设置,毕竟我们的平台在运行时无法进行完全加速。同样,测试结果有较小但明显的区别。那就是使用致态TiPro9000 SSD 2TB这样的PCIe 5.0产品时,模型的加载时间最短。

可能由于显卡分担负载不同的缘故,在与GeForce RTX 4080搭配时,反而致态TiPro9000 SSD 2TB加载模型的时间更短,只有23.18s,换用GeForce RTX 5080显卡则需要25.94s。但无论致态TiPro9000 SSD 2TB与哪种显卡搭配,其加载时间都比使用满速PCIe 4.0 SSD 2TB少。特别是在均使用GeForce RTX 4080的状态下,致态TiPro9000 SSD 2TB加载70B模型的时间少了4s,比使用满速PCIe 4.0产品时的耗时降低了多达15%,在均使用GeForce RTX 5080显卡的环境下,致态TiPro9000 SSD 2TB的耗时也少了近3s,比使用满速PCIe 4.0产品时的耗时降低10.2%。
要玩转DeepSeek 高规格硬件不能少通过以上测试,我们认为借助LM Studio这样的图形化平台,使用DeepSeek对用户软件、AI知识的要求很低,几步就能快速完成部署、使用。反倒是DeepSeek对PC硬件的要求很高,特别是要体验参数量、容量大的模型,用户必须配备性能尽可能高、容量尽可能大的显卡、SSD、内存,比如换用致态TiPro9000 SSD 2TB这样的高性能PCIe 5.0产品,不仅能轻松存储各类模型,还能输出更高的词元tokens/s生成性能,较使用满速PCIe 4.0 SSD时可以提升最大约3.2%的性能,更可以显著降低模型加载时间,相比满速PCIe 4.0 SSD的耗时最多可以降低约15%,大幅提升运行效率,给用户带来更好的DeepSeek使用体验。因此要想玩转DeepSeek,那么采用高规格硬件就必不可少。
