对象检测是计算机视觉中的核心任务,涉及识别和定位图像中的对象。实时对象检测对自动驾驶、监控和机器人等应用至关重要。YOLO(You Only Look Once)系列自 2015年问世以来,因其速度和准确性而广受关注。

YOLO 系列的历史与演进
YOLO 系列始于 2015年的 YOLOv1,由 Redmon 等人提出,首次实现单网络实时对象检测。它将图像划分为网格,每个网格预测边界框和类别概率,显著提升了检测速度。首个单阶段实时检测框架,通过网格划分与全局回归实现“看一眼即检测”。其缺陷在于定位精度低、小目标漏检率高。

YOLO
YOLOv2 (2016):引入批归一化、锚框和 Darknet-19 架构,平衡速度和准确性。引入锚框(Anchor)机制、多尺度训练,并提出Darknet-19骨干网络,显著提升检测精度。
YOLOv3 (2018):采用更深的 Darknet-53,支持多尺度预测,增强对小对象的检测。采用残差结构与多尺度预测(FPN),在COCO数据集上实现精度与速度的平衡。
YOLOv4 (2020):由 Bochkovskiy 等人提出,结合最佳实践,包括免费优化(bag of freebies)和特殊技巧(bag of specials),提升性能。集成CSPNet、Mish激活函数等技巧,提出“Bag of Freebies”训练策略,速度达65 FPS时AP达43.5%。

YOLOv5
YOLOv5 (2020):由 Ultralytics 发布,社区驱动,优化训练和推理流程。引入自适应锚框计算与混合数据增强,成为工业界最广泛应用的版本

YOLOv7
YOLOv7(2023):通过跨阶段特征融合与动态标签分配策略,刷新实时检测SOTA。
YOLOv8(2023),Ultralytics再次发布YOLO更新模型,YOLOv8模型。Ultralytics YOLOv8是YOLO对象检测和图像分割模型的最新版本。YOLOv8 是一种尖端的、最先进的 (SOTA) 模型。YOLOv8的一个关键特性是它的可扩展性。它被设计为一个框架,支持所有以前版本的 YOLO,可以轻松地在不同版本之间切换并比较它们的性能。

除了可扩展性之外,YOLOv8 还包括许多其他创新,使其成广泛应用在对象检测和图像分割任务上。其中包括新的骨干网络,新的无锚网络检测头和新的损失函数功能。YOLOv8 也非常高效,可以在各种硬件平台(从 CPU 到 GPU)上运行。
YOLOv9(2024):提出可编程梯度信息(PGI)与广义高效层聚合网络(GELAN),解决深度网络信息丢失问题
每个版本都在前代基础上构建,吸收深度学习最新进展,推动实时对象检测的边界。

Transformer 模型注意力机制
在深度学习中,注意力机制允许模型动态聚焦输入数据中与任务相关的信息。最初用于自然语言处理(如机器翻译),后来扩展到计算机视觉。对象检测中,注意力机制帮助模型关注可能包含对象的区域,减少无关信息的干扰。注意力机制模拟人类视觉系统的聚焦特性,通过动态权重分配增强关键特征、抑制冗余信息。

其核心类型包括:
空间注意力:聚焦图像的特定区域,突出潜在目标。定位关键空间区域,增强目标位置响应。
通道注意力:权衡特征图的不同通道,强调对检测有用的特征。学习通道维度权重,突出重要特征通道。
自注意力:受 Transformer 启发,模型可关注特征图的不同部分,提升全局上下文理解。建立全局长程依赖关系,捕捉上下文关联
注意力机制显著提升模型性能,尤其在处理复杂场景或多尺度对象时,Transformer 的主要组成部分:
 编码器(Encoder): 将输入序列转换为一个高维的向量表示,捕捉序列中的上下文信息。解码器(Decoder): 根据编码器的输出和已生成的序列,逐步生成输出序列。注意力机制(Self-Attention): 是 Transformer 的核心,它可以让序列中的每个元素都与其他元素进行交互,从而捕获它们之间的关系。
编码器(Encoder): 将输入序列转换为一个高维的向量表示,捕捉序列中的上下文信息。解码器(Decoder): 根据编码器的输出和已生成的序列,逐步生成输出序列。注意力机制(Self-Attention): 是 Transformer 的核心,它可以让序列中的每个元素都与其他元素进行交互,从而捕获它们之间的关系。Transformer 的优点:
并行计算: Transformer 模型允许对序列中的所有元素进行并行计算,显著缩短了训练时间。长距离依赖: 通过注意力机制,Transformer 模型能够捕捉序列中远距离元素之间的依赖关系,克服了 RNN 模型在长序列上的不足。强大的表示能力: Transformer 模型能够学习到丰富的上下文信息,从而在各种自然语言处理任务上取得卓越的性能。可扩展性: Transformer 模型结构简单,易于扩展,可以通过增加模型的层数、维度和注意力头数来提高模型的性能。YOLOv12 的设计与注意力机制
根据论文 YOLOv12: Attention-Centric Real-Time Object Detectors,YOLOv12 将注意力机制作为核心设计,旨在提升实时对象检测的准确性和效率。YOLOv12 的核心是将注意力机制融入 YOLO 框架,以提升目标检测的精度,同时保持 YOLO 系列一贯的快速推理速度。 论文的核心观点在于,尽管注意力机制在建模能力上优于 CNN,但由于计算效率和内存访问的限制,以往的 YOLO 模型主要依赖 CNN。YOLOv12 旨在打破这一局面,打造一个“注意力中心”的 YOLO 检测器。
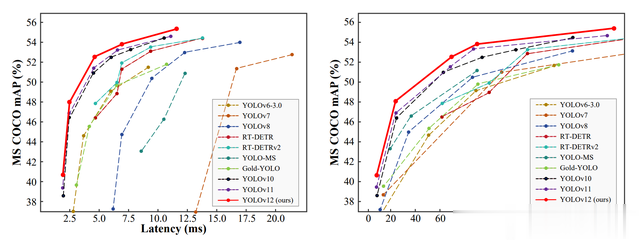
现有YOLO 模型架构设计主要集中于 CNN 改进,而忽略了注意力机制更强的建模能力。注意力机制在实时目标检测中应用受限的原因:
计算复杂度高: 自注意力计算复杂度与输入序列长度呈平方关系。内存访问效率低: 注意力计算过程中存在大量的内存读写操作。基于以上问题,YOLOv12进行了关键的改进
注意力中心设计: YOLOv12 率先探索了在 YOLO 框架中以注意力机制为中心的设计思路,打破了以往 CNN 一统天下的局面。Area Attention(A2): 区域注意力机制是一种简单有效的降低注意力计算复杂度的方法,能够在保持精度的同时显著提高速度。提出了一种简单而高效的区域注意力模块。通过将特征图划分为多个区域,在区域内进行注意力计算,降低计算复杂度,同时保持较大的感受野。 R-ELAN: 残差高效层聚合网络解决了训练大型注意力模型时遇到的优化难题,提高了模型的稳定性和收敛性。全面的架构优化: YOLOv12 在多个方面对模型架构进行了优化,包括引入 FlashAttention、移除位置编码、调整 MLP 比例等,从而实现了整体性能的提升。Residual Efficient Layer Aggregation Networks(R-ELAN): 设计了一种残差高效层聚合网络,用于解决注意力机制带来的优化挑战。R-ELAN 在原 ELAN 基础上引入了块级残差设计和重新设计的特征聚合方法。
R-ELAN: 残差高效层聚合网络解决了训练大型注意力模型时遇到的优化难题,提高了模型的稳定性和收敛性。全面的架构优化: YOLOv12 在多个方面对模型架构进行了优化,包括引入 FlashAttention、移除位置编码、调整 MLP 比例等,从而实现了整体性能的提升。Residual Efficient Layer Aggregation Networks(R-ELAN): 设计了一种残差高效层聚合网络,用于解决注意力机制带来的优化挑战。R-ELAN 在原 ELAN 基础上引入了块级残差设计和重新设计的特征聚合方法。
架构改进:
引入 FlashAttention,解决内存访问问题。移除 positional encoding,加快模型速度。调整 MLP 比例,平衡注意力机制和前馈网络的计算量。尽可能使用卷积算子,提高计算效率。

在标准目标检测数据集 MS COCO 上进行了大量实验,证明 YOLOv12 在精度和速度上均优于以往的 YOLO 模型以及其他实时目标检测器。不同尺度的 YOLOv12 模型 (YOLOv12-N/S/M/L/X) 在精度和速度之间取得了良好的平衡。
而 hugging face 上面也已经可以有demo 进行使用,用户只需要上传一张照片或者视频即可

而YOLO12 已经在 GitHub上面开源,可以直接使用代码进行对象检测
import cv2from ultralytics import YOLOimport supervision as svimage_path = f"demo.jpeg"image = cv2.imread(image_path)model = YOLO('yolov12l.pt')results = model(image, verbose=False)[0]detections = sv.Detections.from_ultralytics(results)box_annotator = sv.BoxAnnotator()label_annotator = sv.LabelAnnotator()annotated_image = image.copy()annotated_image = box_annotator.annotate(scene=annotated_image, detections=detections)annotated_image = label_annotator.annotate(scene=annotated_image, detections=detections)sv.plot_image(annotated_image)
当然微调YOLO12系列模型也是比较简单,可以直接使用开源的代码
from ultralytics import YOLOmodel = YOLO('yolov12n.yaml')results = model.train( data='coco.yaml', epochs=600, batch=256, imgsz=640, scale=0.5, # S:0.9; M:0.9; L:0.9; X:0.9 mosaic=1.0, mixup=0.0, # S:0.05; M:0.15; L:0.15; X:0.2 copy_paste=0.1, # S:0.15; M:0.4; L:0.5; X:0.6 device="0,1,2,3",)metrics = model.val()results = model("path/to/image.jpg")results[0].show()当然YOLO12系列已经继承在了ultralytics里面,我们进行对象检测与视频实时对象检测时,可以直接使用ultralytics。
from ultralytics import YOLOmodel = YOLO('yolov12{n/s/m/l/x}.pt')model.predict()官方训练代码
from roboflow import download_dataset#这里下载自己的训练集dataset = download_dataset('https://universe.roboflow.com/roboflow-100/circuit-voltages/dataset/2', 'yolov8')!ls {dataset.location}!sed -i '$d' {dataset.location}/data.yaml!sed -i '$d' {dataset.location}/data.yaml!sed -i '$d' {dataset.location}/data.yaml!sed -i '$d' {dataset.location}/data.yaml!echo -e "test: ../test/images\ntrain: ../train/images\nval: ../valid/images" >> {dataset.location}/data.yaml!cat {dataset.location}/data.yaml设置好自己的数据集后,然后进行代码的训练
from ultralytics import YOLOmodel = YOLO('yolov12s.yaml')results = model.train(data=f'{dataset.location}/data.yaml', epochs=100)import localelocale.getpreferredencoding = lambda: "UTF-8"!ls {HOME}/runs/detect/train/from IPython.display import ImageImage(filename=f'{HOME}/runs/detect/train/confusion_matrix.png', width=1000) from IPython.display import ImageImage(filename=f'{HOME}/runs/detect/train/results.png', width=1000)
from IPython.display import ImageImage(filename=f'{HOME}/runs/detect/train/results.png', width=1000) import supervision as svds = sv.DetectionDataset.from_yolo( images_directory_path=f"{dataset.location}/test/images", annotations_directory_path=f"{dataset.location}/test/labels", data_yaml_path=f"{dataset.location}/data.yaml")ds.classesfrom supervision.metrics import MeanAveragePrecisionmodel = YOLO(f'/{HOME}/runs/detect/train/weights/best.pt')predictions = []targets = []for _, image, target in ds: results = model(image, verbose=False)[0] detections = sv.Detections.from_ultralytics(results) predictions.append(detections) targets.append(target)map = MeanAveragePrecision().update(predictions, targets).compute()map.plot()
import supervision as svds = sv.DetectionDataset.from_yolo( images_directory_path=f"{dataset.location}/test/images", annotations_directory_path=f"{dataset.location}/test/labels", data_yaml_path=f"{dataset.location}/data.yaml")ds.classesfrom supervision.metrics import MeanAveragePrecisionmodel = YOLO(f'/{HOME}/runs/detect/train/weights/best.pt')predictions = []targets = []for _, image, target in ds: results = model(image, verbose=False)[0] detections = sv.Detections.from_ultralytics(results) predictions.append(detections) targets.append(target)map = MeanAveragePrecision().update(predictions, targets).compute()map.plot()
训练完成后,我们使用代码进行一个图片的检测
import supervision as svmodel = YOLO(f'/{HOME}/runs/detect/train/weights/best.pt')ds = sv.DetectionDataset.from_yolo( images_directory_path=f"{dataset.location}/test/images", annotations_directory_path=f"{dataset.location}/test/labels", data_yaml_path=f"{dataset.location}/data.yaml")import randomi = random.randint(0, len(ds))image_path, image, target = ds[i]results = model(image, verbose=False)[0]detections = sv.Detections.from_ultralytics(results).with_nms()box_annotator = sv.BoxAnnotator()label_annotator = sv.LabelAnnotator()annotated_image = image.copy()annotated_image = box_annotator.annotate(scene=annotated_image, detections=detections)annotated_image = label_annotator.annotate(scene=annotated_image, detections=detections)sv.plot_image(annotated_image) https://github.com/sunsmarterjie/yolov12https://arxiv.org/pdf/2502.12524https://huggingface.co/spaces/sunsmarterjieleaf/yolov12
https://github.com/sunsmarterjie/yolov12https://arxiv.org/pdf/2502.12524https://huggingface.co/spaces/sunsmarterjieleaf/yolov12 