在时间序列分析领域中,存在多种可能影响分析结果有效性的技术挑战。其中,数据泄露、前瞻性偏差和因果关系违反是最为常见且具有显著影响的问题。
数据泄露:隐蔽的系统性错误数据泄露是指在预测时理论上无法获取的信息,通过某种方式影响了模型的训练过程。在时间序列分析中,由于数据的时序特性,这种问题尤为隐蔽。数据泄露会导致模型在训练阶段表现出远超其在实际生产环境中的准确性。
时间序列分析中的数据泄露典型场景:
未来数据混入: 在预测模型中错误地引入了未来时间点的数据作为特征。
特征工程缺陷: 在特征构建过程中无意中引入了未来信息(例如:使用包含未来时间点的滑动窗口计算均值)。
非时序数据分割: 忽视数据的时间序列性质进行随机分割,导致训练集和测试集之间的时序信息交叉。
影响分析包含数据泄露的模型在实际生产环境中往往会出现显著的性能退化,这是由于在实时预测时无法获取训练阶段使用的未来信息。
检测与防范措施时序感知的数据分割: 采用前向验证(walk-forward validation)或基于时间的分割方法,确保训练集、验证集和测试集在时间维度上的严格分离。
特征工程规范化: 确保特征构建过程仅使用相对于预测目标时间点的历史数据。
数据流程审计: 系统性地检查整个数据处理流程,识别潜在的泄露点。
以下通过日本天然气价格数据(来源:FRED,截至2024-01-24)进行实例分析,分别展示错误示范和正确实现方法。
import pandas as pd import numpy as np import requests import matplotlib.pyplot as plt from sklearn.linear_model import LinearRegression from statsmodels.tsa.stattools import grangercausalitytests import seaborn as sns import warnings warnings.filterwarnings('ignore') def fetch_fred_data(series_id, api_key, start_date='2000-01-01'): """从FRED API获取时间序列数据""" url = "https://api.stlouisfed.org/fred/series/observations" params = { 'series_id': series_id, 'api_key': api_key, 'file_type': 'json', 'observation_start': start_date, } response = requests.get(url, params=params) if response.status_code == 200: data = response.json() df = pd.DataFrame(data['observations']) df['date'] = pd.to_datetime(df['date']) df['value'] = pd.to_numeric(df['value'], errors='coerce') return df def mape(y_true, y_pred): """计算平均绝对百分比误差(MAPE)""" return np.mean(np.abs((y_true - y_pred) / y_true)) * 100 def create_features(df, leakage=False): """构建特征向量,可选是否包含数据泄露""" df = df.copy() if leakage: # 数据泄露场景 df['rolling_mean'] = df['value'].rolling(window=7, center=True).mean() df['volatility'] = df['value'].rolling(window=10, center=True).std() else: df['rolling_mean'] = df['value'].rolling(window=7).mean().shift(1) df['volatility'] = df['value'].rolling(window=10).std().shift(1) df['price_lag'] = df['value'].shift(1) df['monthly_return'] = df['value'].pct_change(periods=30) return dfdef train_model(data, features, target='value'): """训练和评估预测模型""" data = data.dropna() train_size = int(len(data) * 0.8) train_data = data[:train_size] test_data = data[train_size:] X_train = train_data[features] y_train = train_data[target] X_test = test_data[features] y_test = test_data[target] model = LinearRegression() model.fit(X_train, y_train) y_pred = model.predict(X_test) return test_data.index, y_test, y_pred def plot_features(data, leakage_data, proper_data, title, filename): """可视化对比数据泄露与正确处理的特征差异""" fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(12, 10)) # 绘制滑动平均值对比 ax1.plot(data.index, data['value'], label='Original Price', alpha=0.5) ax1.plot(leakage_data.index, leakage_data['rolling_mean'], label='Rolling Mean (with leakage)', linewidth=2) ax1.plot(proper_data.index, proper_data['rolling_mean'], label='Rolling Mean (proper)', linewidth=2) ax1.set_title(f'{title} - Rolling Means') ax1.legend(loc='upper left') ax1.set_xlabel('Date') ax1.set_ylabel('Price') # 绘制波动率对比 ax2.plot(leakage_data.index, leakage_data['volatility'], label='Volatility (with leakage)', linewidth=2) ax2.plot(proper_data.index, proper_data['volatility'], label='Volatility (proper)', linewidth=2) ax2.set_title(f'{title} - Volatility') ax2.legend(loc='upper left') ax2.set_xlabel('Date') ax2.set_ylabel('Volatility') plt.tight_layout() plt.savefig(filename, dpi=300, bbox_inches='tight') plt.show() def plot_predictions(leakage_results, proper_results, title, filename): """可视化预测结果对比分析""" fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(12, 10)) # 解析结果数据 dates_leak, y_test_leak, y_pred_leak = leakage_results dates_proper, y_test_proper, y_pred_proper = proper_results # 计算评估指标 mape_leak = mape(y_test_leak, y_pred_leak) mape_proper = mape(y_test_proper, y_pred_proper) # 时间序列预测可视化 ax1.plot(dates_leak, y_test_leak, label='Actual', alpha=0.7) ax1.plot(dates_leak, y_pred_leak, '--', label=f'With Leakage (MAPE: {mape_leak:.2f}%)') ax1.plot(dates_proper, y_pred_proper, '--', label=f'Proper (MAPE: {mape_proper:.2f}%)') ax1.set_title(f'{title} - Predictions Over Time') ax1.legend(loc='upper left') ax1.set_xlabel('Date') ax1.set_ylabel('Price') # 预测值与实际值散点图分析 ax2.scatter(y_test_leak, y_pred_leak, alpha=0.5, label='With Leakage') ax2.scatter(y_test_proper, y_pred_proper, alpha=0.5, label='Proper') ax2.plot([min(y_test_leak.min(), y_test_proper.min()), max(y_test_leak.max(), y_test_proper.max())], [min(y_test_leak.min(), y_test_proper.min()), max(y_test_leak.max(), y_test_proper.max())], 'r--', label='Perfect Prediction') ax2.set_title('Actual vs Predicted Prices') ax2.legend(loc='upper left') ax2.set_xlabel('Actual Price') ax2.set_ylabel('Predicted Price') plt.tight_layout() plt.savefig(filename, dpi=300, bbox_inches='tight') plt.show() def main(): api_key = 'YOUR_KEY' # 获取原始数据 japan_gas = fetch_fred_data('PNGASJPUSDM', api_key) # 构建对比实验数据集 data_with_leakage = create_features(japan_gas, leakage=True) data_proper = create_features(japan_gas, leakage=False) # 特征构建对比分析 plot_features(japan_gas, data_with_leakage, data_proper, 'Japan Natural Gas Prices', 'japan_gas_features.png') # 模型训练与评估 features_leak = ['rolling_mean', 'volatility', 'price_lag', 'monthly_return'] features_proper = ['rolling_mean', 'volatility', 'price_lag', 'monthly_return'] leakage_results = train_model(data_with_leakage, features_leak) proper_results = train_model(data_proper, features_proper) # 预测结果可视化分析 plot_predictions(leakage_results, proper_results, 'Japan Natural Gas Prices', 'japan_gas_predictions.png') # 模型性能评估 _, y_test_leak, y_pred_leak = leakage_results _, y_test_proper, y_pred_proper = proper_results mape_leak = mape(y_test_leak, y_pred_leak) mape_proper = mape(y_test_proper, y_pred_proper) print(f"MAPE with leakage: {mape_leak:.2f}%") print(f"MAPE without leakage: {mape_proper:.2f}%") print(f"Difference in MAPE: {mape_proper - mape_leak:.2f}%")
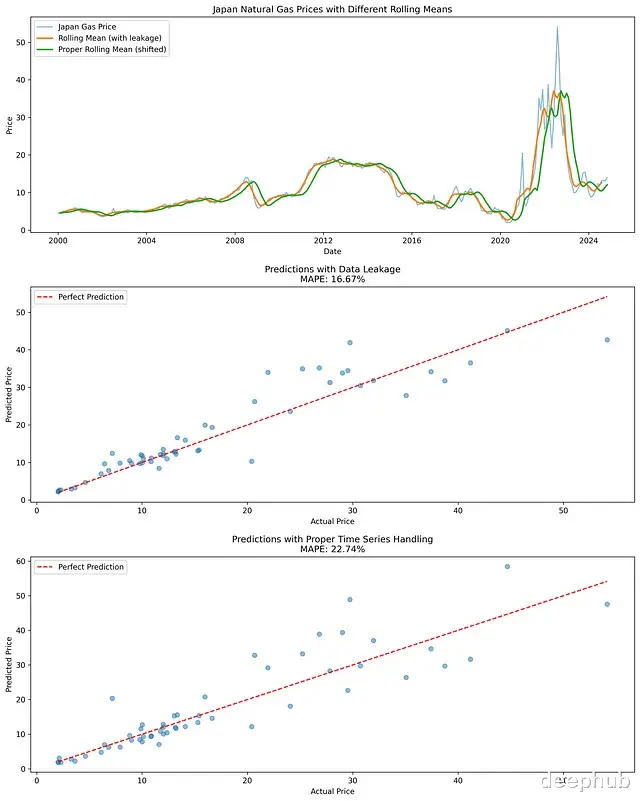
MAPE with data leakage: 16.67% MAPE without data leakage: 22.74% Difference in MAPE: 6.07%
前瞻性偏差:时序预测中的系统性误差前瞻性偏差是数据泄露的一种特殊形式,指模型在训练或评估阶段获取了未来时间点的信息。这种偏差在预测应用中尤其严重,因为预测的本质是基于已知信息推断未知的未来值。
前瞻性偏差的主要表现形式:
标签信息泄露: 在模型训练过程中误用了未来时间点的目标变量值。
因果时序混淆: 使用了仅在目标事件发生后才能获得的预测变量,如事后统计的市场指标或反馈数据。
影响评估前瞻性偏差会严重影响模型的可靠性。在测试阶段获取未来信息的模型会表现出虚高的性能指标,这种假象会导致对模型预测能力的错误评估。
前瞻性偏差防控策略滞后特征设计: 确保所有特征变量仅包含预测时点之前可获得的信息。
严格的回测机制: 采用仅使用历史数据的真实场景进行模型验证。
特征时序审计: 定期检查特征工程过程,防止特征计算中引入未来信息。
# 特征构建函数:前瞻性偏差版本 def create_features_with_lookahead(df): df['next_day_price'] = df['value'].shift(-1) # 目标变量:次日价格 df['future_5day_ma'] = df['value'].rolling(window=5, center=True).mean() df['future_volatility'] = df['value'].rolling(window=10, center=True).std() return df # 特征构建函数:正确实现版本 def create_features_proper(df): df['next_day_price'] = df['value'].shift(-1) # 目标变量:次日价格 df['past_5day_ma'] = df['value'].rolling(window=5).mean() df['past_volatility'] = df['value'].rolling(window=10).std() return df # 基于时序分割的模型训练与评估函数 def evaluate_model(data, features, title, ax): # 数据预处理 data = data.dropna() # 基于时序的训练测试集分割 train_size = int(len(data) * 0.8) train_data = data[:train_size] test_data = data[train_size:] # 特征与目标变量准备 X_train = train_data[features] y_train = train_data['next_day_price'] X_test = test_data[features] y_test = test_data['next_day_price'] # 模型训练 model = LinearRegression() model.fit(X_train, y_train) # 预测与评估 y_pred = model.predict(X_test) mape_score = mape(y_test, y_pred) # 结果可视化 ax.scatter(y_test, y_pred, alpha=0.5) ax.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'r--', label='Perfect Prediction') ax.set_title(f'{title}\nMAPE: {mape_score:.2f}%') ax.set_xlabel('Actual Price') ax.set_ylabel('Predicted Price') ax.legend() return mape_score, test_data.index, y_test, y_pred def main(): # 初始化API配置 api_key = 'YOUR_KEY' # 获取美国天然气价格数据 gas_data = fetch_fred_data('PNGASUSUSDM', api_key) gas_data = gas_data.set_index('date') # 构建对照组数据集 data_with_lookahead = create_features_with_lookahead(gas_data.copy()) data_proper = create_features_proper(gas_data.copy()) # 可视化分析初始化 fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6)) # 模型评估 mape_lookahead, test_dates_look, y_test_look, y_pred_look = evaluate_model( data_with_lookahead, ['future_5day_ma', 'future_volatility'], 'Model with Lookahead Bias', ax1 ) mape_proper, test_dates_prop, y_test_prop, y_pred_prop = evaluate_model( data_proper, ['past_5day_ma', 'past_volatility'], 'Model without Lookahead Bias', ax2 ) plt.tight_layout() plt.show() # 性能指标对比分析 print(f"MAPE with lookahead bias: {mape_lookahead:.2f}%") print(f"MAPE without lookahead bias: {mape_proper:.2f}%") print(f"Difference in MAPE: {mape_proper - mape_lookahead:.2f}%")
通过实验验证,前瞻性偏差显著影响了模型的评估结果。这种影响实际上相当于在预测过程中引入了未来信息,导致模型性能被高估。
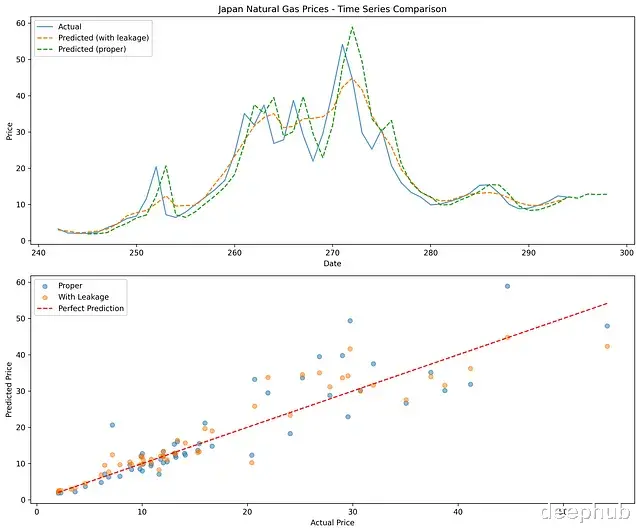
Performance Metrics: -------------------------------------------------- MAPE with lookahead bias: 17.81% MAPE without lookahead bias: 36.03% Difference in MAPE: 18.22%
实验结果明确显示,包含前瞻性偏差的模型在评估指标上优于正确实现的模型约18.22个百分点。这种性能差异凸显了前瞻性偏差对模型评估的显著影响。
因果关系分析:时间序列建模的基础在时间序列分析领域,准确理解和建模因果关系对构建可靠且实用的预测模型至关重要。当底层系统发生变化时,缺乏因果基础的预测关系往往会失效,这是由于简单的相关性可能无法持续保持。
时间序列因果分析的关键挑战:
虚假相关性: 在小规模样本中可能出现统计上显著但实际无意义的随机相关。
混淆变量: 存在同时影响预测变量和目标变量的潜在因素,形成误导性的统计关联。
反向因果: 预测变量可能实际上是目标变量的结果而非原因。
因果分析方法论格兰杰因果检验: 用于评估时间序列之间预测能力的统计检验方法。
有向无环图(DAGs): 用于建模和可视化潜在因果关系的图形化工具。
反事实分析: 评估预测变量干预效应的系统性方法。
时间序列因果分析最佳实践领域知识整合: 与领域专家合作验证因果假设的合理性。
实验设计方法: 通过A/B测试或自然实验构建可靠的因果推断框架。
模型鲁棒性: 采用结构方程模型或贝叶斯网络等方法处理混淆因素。
实证分析本节通过分析亚洲和欧洲天然气价格与美国商业银行个人贷款利率之间的关系进行实证研究。基于经济学理论,我们预期两个天然气价格指数之间存在较强的相关性。而日本液化天然气价格与美国贷款利率之间理论上缺乏直接的因果联系(虽然可能通过宏观经济指标间接关联,但这种关联在实务中并不构成显著的因果关系)。
def granger_causality(data, max_lag=12): """执行格兰杰因果检验分析""" results = {} for col1 in data.columns: for col2 in data.columns: if col1 != col2: test_result = grangercausalitytests(data[[col1, col2]], maxlag=max_lag, verbose=False) min_p_value = min([test_result[i+1][0]['ssr_ftest'][1] for i in range(max_lag)]) results[f"{col1} -> {col2}"] = min_p_value return results def plot_correlations_and_scatter(data): # 构建相关性矩阵 corr = data.corr() # 创建多子图布局 fig = plt.figure(figsize=(15, 10)) # 相关性热图可视化 ax1 = plt.subplot2grid((2, 3), (0, 0), colspan=2) sns.heatmap(corr, annot=True, cmap='coolwarm', center=0, ax=ax1) ax1.set_title("Correlation Heatmap") # 变量对散点图分析 ax2 = plt.subplot2grid((2, 3), (1, 0)) ax2.scatter(data['Japan Gas'], data['EM Gas']) ax2.set_xlabel('Japan Gas') ax2.set_ylabel('EM Gas') ax2.set_title('Japan Gas vs EM Gas') ax3 = plt.subplot2grid((2, 3), (1, 1)) ax3.scatter(data['Japan Gas'], data['US Loan Rate']) ax3.set_xlabel('Japan Gas') ax3.set_ylabel('US Loan Rate') ax3.set_title('Japan Gas vs US Loan Rate') ax4 = plt.subplot2grid((2, 3), (1, 2)) ax4.scatter(data['EM Gas'], data['US Loan Rate']) ax4.set_xlabel('EM Gas') ax4.set_ylabel('US Loan Rate') ax4.set_title('EM Gas vs US Loan Rate') plt.tight_layout() plt.show() def plot_time_series(data): fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(15, 10)) # 天然气价格时序图 ax1.plot(data.index, data['Japan Gas'], label='Japan Gas') ax1.plot(data.index, data['EM Gas'], label='EM Gas') ax1.set_title('Natural Gas Prices Over Time') ax1.legend() ax1.grid(True) # 美国贷款利率时序图 ax2.plot(data.index, data['US Loan Rate'], label='US Loan Rate', color='green') ax2.set_title('US Loan Rate Over Time') ax2.legend() ax2.grid(True) plt.tight_layout() plt.show()
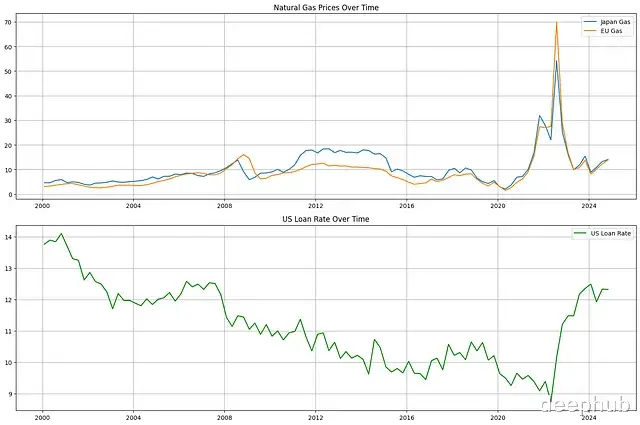
相关性分析结果显示,日本和欧盟天然气价格之间存在显著的正相关关系,这符合有效市场理论的预期。而天然气价格与美国贷款利率之间则表现出较弱的相关性。
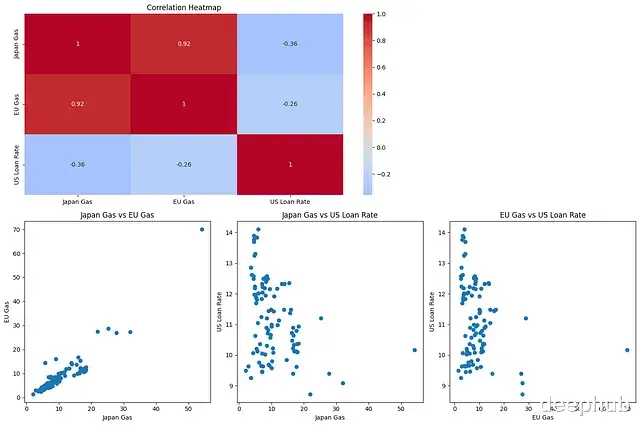
然而,格兰杰因果检验的结果却表明了一个有趣的现象。尽管理论预期显示某些变量对之间缺乏因果关系,但统计检验结果呈现出显著性,这表明观察到的时序关系不太可能是随机产生的。这种现象突出了统计显著性与实际因果关系之间的潜在差异。
Granger Causality Results (p-values): ---------------------------------------- Japan Gas -> EM Gas: 0.0003 *** Japan Gas -> US Loan Rate: 0.0014 *** EM Gas -> Japan Gas: 0.0000 *** EM Gas -> US Loan Rate: 0.0008 *** US Loan Rate -> Japan Gas: 0.0081 *** US Loan Rate -> EM Gas: 0.0005 *** Significance levels: *** p<0.01, ** p<0.05, * p<0.1
总结数据泄露、前瞻性偏差和因果关系违反等问题会导致模型评估结果出现系统性偏差。虽然Python提供了强大的数据处理能力,但确保分析过程的方法学正确性仍然是数据科学家的核心职责。实施规范的最佳实践、深入理解领域知识并严格验证模型假设,是构建可靠时间序列分析模型的关键要素。
https://avoid.overfit.cn/post/122b36fdb8cb402f95cc5b6f2a22f105
作者:Kyle Jones