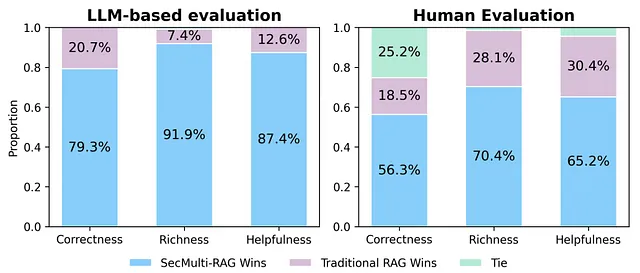
SecMulti-RAG:兼顾数据安全与智能检索的多源RAG框架,为企业构建不泄密的智能搜索引擎
本文深入剖析SecMulti-RAG框架,该框架通过集成内部文档库、预构建专家知识以及受控外部大语言模型,并结合保密性过
deephub的文章
本文深入剖析SecMulti-RAG框架,该框架通过集成内部文档库、预构建专家知识以及受控外部大语言模型,并结合保密性过
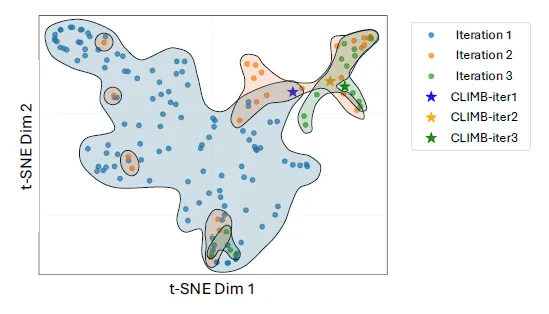
尽管优化预训练数据混合对大型语言模型(LLM)的性能有显著影响,但确定最优数据配比仍然是一个亟待解决的挑战。为应对这一问

PyTorch作为深度学习研究与工程领域的主流框架,拥有强大的性能潜力,但许多高级性能特性往往隐藏在文档深处,未被充分利

SmolVLM是专为资源受限设备设计的一系列小型高效多模态模型。尽管模型规模较小,但通过精心设计的架构和训练策略,Smo

ReSearch是一种创新性框架,通过强化学习技术训练大语言模型执行"推理搜索",无需依赖推理步骤的监督数据。该方法将搜

随着人工智能生态系统的迅速演进,模型与工具之间的无缝通信已成为技术发展的关键环节。在这一背景下,模型上下文协议(Mode

随着大型语言模型(LLMs)的快速发展,高质量数据供给已成为智能系统的关键基础架构。为使人工智能系统能够生成有实际价值的

Triton是一款开源的GPU编程语言与编译器,为AI和深度学习领域提供了高性能GPU代码的高效开发途径。本指南将全面阐
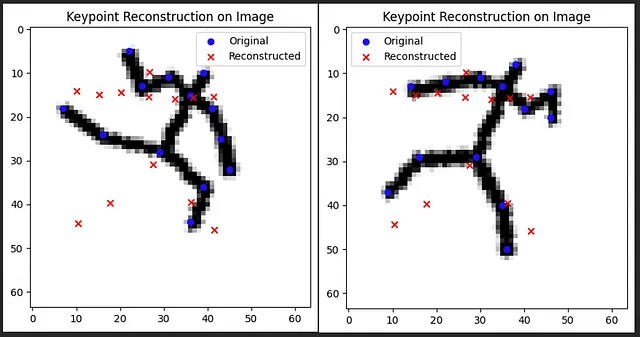
在人体姿态估计领域,传统方法通常将关键点作为基本处理单元,这些关键点在人体骨架结构上代表关节位置(如肘部、膝盖和头部)的

在人工智能领域的快速迭代发展中,两种协议已成为构建新一代AI系统的关键基础设施:模型上下文协议(Model Contex

扩散模型(Diffusion Models)和流匹配(Flow Matching)是用于生成高质量、连贯性强的高分辨率数

在深度学习工程实践中,当训练大型模型或处理大规模数据集时,上述错误信息对许多开发者而言已不陌生。这是众所周知的CUDA

本文详述了如何通过检索增强生成(RAG)技术构建一个能够利用特定文档集合回答问题的AI系统。通过LangChain框架,

CodeAct作为AI辅助系统的一种先进范式,实现了自然语言处理与代码执行能力的深度融合。通过构建自定义代码执行代理,开

在营销分析领域的持续演进过程中,营销组合建模(Marketing Mix Modeling, MMM)作为一种核心分析技

本文将详细探讨一种基于Transformer架构的时间序列去噪模型的构建过程及其应用价值。Transformer是一种专

随着NVIDIA不断推出基于新架构的GPU产品,机器学习框架需要相应地更新以支持这些硬件。本文记录了在RTX 5070

随着大型语言模型(LLMs)和基于人工智能的应用程序在各行业的广泛部署,对自然语言处理(NLP)工具性能的要求日益提高。

在计算技术快速迭代的今天,传统通用处理器(CPU)正逐步被专用硬件加速器补充或替代,尤其在特定计算领域。这些加速器通过针

真实标签的不完美性是机器学习领域一个不可避免的挑战。从科学测量数据到深度学习模型训练中的人工标注,真实标签总是包含一定比

热门分类