
PyTorchPINN实战:用深度学习求解微分方程
神经网络技术已在计算机视觉与自然语言处理等多个领域实现了突破性进展。然而在微分方程求解领域,传统神经网络因其依赖大规模标
deephub的文章
神经网络技术已在计算机视觉与自然语言处理等多个领域实现了突破性进展。然而在微分方程求解领域,传统神经网络因其依赖大规模标

SigLIP 2 是一个新型多语言视觉-语言编码器系列,通过整合基于字幕的预训练、自监督学习机制(包括自蒸馏和掩码预测)

近期大语言模型(LLM)的基准测试结果引发了对现有架构扩展性的思考。尽管OpenAI推出的GPT-4.5被定位为其最强大

选择性自我监督微调(Selective Self-to-Supervised Fine-Tuning,S3FT)是一种创

在LLama等大规模Transformer架构的语言模型中,归一化模块是构建网络稳定性的关键组件。本文将系统分析归一化技

NeoBERT代表了双向编码器模型的新一代技术发展,通过整合前沿架构改进、现代大规模数据集和优化的预训练策略,有效缩小了

这个研究探讨了大型语言模型(LLMs)在执行复杂推理任务时面临的计算资源消耗与响应延迟问题。研究特别聚焦于思维链(Cha
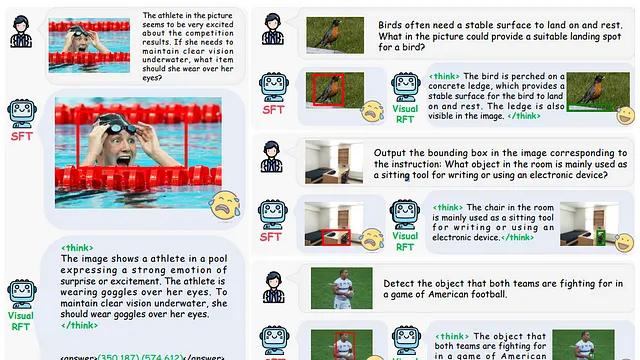
Visual-RFT 代表了视觉语言模型微调领域的技术创新,通过将基于规则的可验证奖励与强化学习相结合,有效克服了传统监

在图神经网络(Graph Neural Networks, GNNs)的发展历程中,注意力机制扮演着至关重要的角色。通过

在快速发展的自然语言处理(NLP)领域,分词(tokenization)作为将原始文本转换为机器可处理格式的首要环节,具

向后淘汰法(Backward Elimination)是机器学习领域中一种重要的特征选择技术,其核心思想是通过系统性地移

在时间序列分析领域,评估数据的平稳性是构建准确模型的基础。ADF(Augmented Dickey-Fuller,增广迪

在大规模深度学习模型训练过程中,GPU内存容量往往成为制约因素,尤其是在训练大型语言模型(LLM)和视觉Transfor

本文将介绍如何为大型语言模型(LLM)添加自定义token并进行训练,使模型能够有效地利用这些新增token。以Llam

特征选择作为机器学习工作流程中的关键环节,对模型性能具有决定性影响。Featurewiz是一个功能强大的特征选择库,具备

这篇论文探讨了基于规则的强化学习(RL)如何解锁LLM中的高级推理能力。通过在受控的逻辑谜题上进行训练并强制执行结构化的

SelfCite 提出了一种新颖的自监督方法,通过上下文消融技术和自监督奖励机制,提升大型语言模型 (LLM) 对上下文

SmolLM2 采用创新的四阶段训练策略,在仅使用 1.7B 参数的情况下,成功挑战了大型语言模型的性能边界:在 MML

本文介绍了一种名为 Diffusion-DPO 的方法,该方法改编自最近提出的直接偏好优化 (DPO)。DPO 作为 R

随着大型语言模型(LLM)规模和复杂性的持续增长,高效推理的重要性日益凸显。KV(键值)缓存与分页注意力是两种优化LLM

热门分类