在图神经网络(Graph Neural Networks, GNNs)的发展历程中,注意力机制扮演着至关重要的角色。通过赋予模型关注图中最相关节点和连接的能力,注意力机制显著提升了GNN在节点分类、链接预测和图分类等任务上的性能。尽管这一机制的重要性不言而喻,但其内部工作原理对许多研究者和工程师而言仍是一个"黑盒"。
本文旨在通过可视化方法和数学推导,揭示图神经网络自注意力层的内部运作机制。我们将采用"位置-转移图"的概念框架,结合NumPy编程实现,一步步拆解自注意力层的计算过程,使读者能够直观理解注意力权重是如何生成并应用于图结构数据的。
通过将复杂的数学表达式转化为易于理解的代码块和可视化图形,本文不仅适合已经熟悉图神经网络的研究人员,也为刚开始接触这一领域的学习者提供了一个清晰的学习路径。
本文详细解析了图神经网络自注意力层的可视化方法及其数学原理,通过代码实现展示其内部工作机制。

在采用自注意力机制的图神经网络中,一个典型层的计算可以通过以下张量乘法表示:

其中各元素定义如下:

包含自循环的邻接矩阵的转置

注意力张量

节点特征矩阵
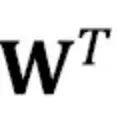
常规(非注意力)权重张量的转置
"自注意力"机制的核心在于注意力张量实际上是由方程中其他元素通过线性函数与非线性函数组合生成的。这一概念可能较为抽象,但我们可以通过编程实现来展示这种组合关系,并从代码中推导出直观的图形表示。
选择NumPy实现而非解析PyTorch Geometric我们选择使用NumPy的原因在于:
PyG的实际代码包含大量计算细节,且设计目标是扩展基础MessagePassing模块,这使得理解张量元素间的关系变得复杂。例如,GATv2Conv模块处理了以下复杂性:
参数重置
forward()方法的多种变体
SparseTensors的特殊处理
而基本的MessagePassing模块则考虑了更多复杂因素,包括钩子、Jinja文本渲染、可解释性、推理分解、张量大小不匹配异常、"提升"和"收集"的子任务以及分解层等。
因此使用NumPy构建一个简洁明了的例子能够更有效地帮助我们理解注意力张量是如何从方程的其他元素构建而来的。
图注意力层的NumPy实现为了绘制方程的位置-转移图,我们将Labonne的代码重构为四个类,这四个类对应于本文顶部图中的四个胶囊(GAL1到GAL4)。
采用面向对象的方法使得我们可以通过构造函数(init方法)区分中间结果和在整个位置-转移图中四个类/胶囊间共享的结果。共享结果通过self.x = y赋值保存为实例数据成员。
为便于理解,下面是一个四节点图的示例:

我们假设每个节点都与自身连接。图中展示了入站和出站弧而非无向边,因为入站-出站关系在代码中被显式表示。
为简化起见,我们假设特征和权重初始化均在(-1, 1)范围内。
以下是GAL1的代码实现:
import numpy as npnp.random.seed(0)class GAL1: num_nodes = 4 num_features = 4 num_hidden_dimensions = 2 # We just choose this arbitrarily // 我们任意选择这个值 X = np.random.uniform(-1, 1, (num_nodes, num_features)) print('X\n', X, '\n') def __init__(self): W = np.random.uniform(-1, 1, (GAL1.num_hidden_dimensions, GAL1.num_nodes)) print('W\n', W, '\n') self.XatWT = GAL1.X @ W.T print('XatWT\n', self.XatWT, '\n')
执行该代码会产生以下输出:
X[[ 0.09762701 0.43037873 0.20552675 0.08976637] [-0.1526904 0.29178823 -0.12482558 0.783546 ] [ 0.92732552 -0.23311696 0.58345008 0.05778984] [ 0.13608912 0.85119328 -0.85792788 -0.8257414 ]]W[[-0.95956321 0.66523969 0.5563135 0.7400243 ] [ 0.95723668 0.59831713 -0.07704128 0.56105835]]XatWT[[ 0.37339233 0.38548525] [ 0.85102612 0.47765279] [-0.67755906 0.73566587] [-0.65268413 0.24235977]]
在这一阶段,我们初始化了节点特征矩阵X和标准权重矩阵W。在实际训练场景中,X来自图结构,而W则源自初始化或前一轮训练。这在位置-转移图上表示为标记为"Graph"和"PyTorch Geo"的"云"位置。
GAL1的主要保留数据成员是self.XatWT,即我们方程的右侧部分("at"表示矩阵乘法的"@"中缀符号)。在后续代码中,这个中间结果将与邻接矩阵结合,形成注意力张量。
GAL2的代码实现如下:
class GAL2: A = np.array([ [1, 1, 1, 1], [1, 1, 0, 0], [1, 0, 1, 1], [1, 0, 1, 1] ]) def __init__(self, gal1: GAL1): print('A\n', GAL2.A, '\n') u = np.asarray(GAL2.A > 0) print('u\n', u, '\n') self.connections = u.nonzero() print('connections\n', self.connections, '\n') XatWTc0 = gal1.XatWT[self.connections[0]] print('XatWTc0\n', XatWTc0, '\n') XatWTc1 = gal1.XatWT[self.connections[1]] print('XatWTc1\n', XatWTc1, '\n') self.XatWT_concat = np.concatenate([XatWTc0, XatWTc1], axis=1) print('XatWT_concat\n', self.XatWT_concat, '\n') def reshape(self, e: np.ndarray) -> np.ndarray: E = np.zeros(GAL2.A.shape) E[self.connections[0], self.connections[1]] = e[0] return E
邻接矩阵A由图的结构固定。connections计算的结果如下:
A[[1 1 1 1] [1 1 0 0] [1 0 1 1] [1 0 1 1]]u[[ True True True True] [ True True False False] [ True False True True] [ True False True True]]connections(array([0, 0, 0, 0, 1, 1, 2, 2, 2, 3, 3, 3]), array([0, 1, 2, 3, 0, 1, 0, 2, 3, 0, 2, 3]))
我们选择的节点标签与邻接矩阵中的索引对应。第一个connections数组表示具有到节点j的出站连接的节点索引i。
例如:
节点0出现四次(出站连接到所有节点包括自身)
节点1仅出现两次(出站连接到节点0和自身)
节点2和节点3各出现三次(出站连接到节点0、彼此和自身)
第二个connections数组包含相同的值,但按入站顺序排列,这是因为该图实际上是非定向的。
使用connections数组作为gal1.XatWT的索引,产生以下输出:
XatWTc0[[ 0.37339233 0.38548525] [ 0.37339233 0.38548525] [ 0.37339233 0.38548525] [ 0.37339233 0.38548525] [ 0.85102612 0.47765279] [ 0.85102612 0.47765279] [-0.67755906 0.73566587] [-0.67755906 0.73566587] [-0.67755906 0.73566587] [-0.65268413 0.24235977] [-0.65268413 0.24235977] [-0.65268413 0.24235977]]XatWTc1[[ 0.37339233 0.38548525] [ 0.85102612 0.47765279] [-0.67755906 0.73566587] [-0.65268413 0.24235977] [ 0.37339233 0.38548525] [ 0.85102612 0.47765279] [ 0.37339233 0.38548525] [-0.67755906 0.73566587] [-0.65268413 0.24235977] [ 0.37339233 0.38548525] [-0.67755906 0.73566587] [-0.65268413 0.24235977]]
此处,我们的十二元素入站和出站connections索引数组分别被转换为gal1.XatWT元素的十二元素数组。
将入站和出站数组连接,得到结果:
XatWT_concat[[ 0.37339233 0.38548525 0.37339233 0.38548525] [ 0.37339233 0.38548525 0.85102612 0.47765279] [ 0.37339233 0.38548525 -0.67755906 0.73566587] [ 0.37339233 0.38548525 -0.65268413 0.24235977] [ 0.85102612 0.47765279 0.37339233 0.38548525] [ 0.85102612 0.47765279 0.85102612 0.47765279] [-0.67755906 0.73566587 0.37339233 0.38548525] [-0.67755906 0.73566587 -0.67755906 0.73566587] [-0.67755906 0.73566587 -0.65268413 0.24235977] [-0.65268413 0.24235977 0.37339233 0.38548525] [-0.65268413 0.24235977 -0.67755906 0.73566587] [-0.65268413 0.24235977 -0.65268413 0.24235977]]
ndarray connections被赋值给self,但并非为了在GAL2外部使用(因此在图中用虚线椭圆表示)。相反,我们在reshape方法中使用connections。reshape方法通过创建一个与A形状相同的零矩阵来生成ndarray E,然后使用connections[0]作为E的行索引,connections[1]作为E的列索引,从输入ndarray e[0]分配值。此方法将被GAL3调用。
显然,E按connections和e的排序应具有相同数量的元素。E的某些元素将保持未分配状态(零值),即那些对应于图中缺少入站或出站弧的节点对的元素。
除了GAL2.A之外,数组XatWT_concat也将在后续计算中使用,因此被赋值给self。
GAL3的代码实现如下:
class GAL3: @staticmethod def leaky_relu(x, alpha=0.2) -> np.ndarray: return np.maximum(alpha * x, x) @staticmethod def softmax2D(x, axis) -> np.ndarray: e = np.exp(x - np.expand_dims(np.max(x, axis=axis), axis)) sum_ = np.expand_dims(np.sum(e, axis=axis), axis) return e / sum_ def __init__(self, gal2: GAL2): W_att = np.random.uniform(-1, 1, (1, GAL1.num_nodes)) print('W_att\n', W_att, '\n') a = W_att @ gal2.XatWT_concat.T print('a\n', a, '\n') e = GAL3.leaky_relu(a) print('e\n', e, '\n') E = gal2.reshape(e) print('E\n', E, '\n') W_alpha = GAL3.softmax2D(E, 1) print('W_alpha\n', W_alpha, '\n') self.left = gal2.A.T @ W_alpha print('left\n', self.left, '\n')
GAL3是我们引入非线性(leaky_relu)和归一化(softmax2D)操作的类。GAL3最终将生成原始方程的整个左侧,仅剩右侧gal1.XatWT未处理。GAL3的唯一"输出"是self.left。
以下是GAL3中的前四个计算步骤:
W_att:初始化或来自前一轮训练
a:W_att与gal2.XatWT_concat的矩阵乘法
e:对a应用leaky_relu函数
E:调用gal2.reshape方法,传入e作为输入
这四个计算的结果如下:
W_att[[-0.76345115 0.27984204 -0.71329343 0.88933783]]a[[-0.1007035 -0.35942847 0.96036209 0.50390318 -0.43956122 -0.69828618 0.79964181 1.8607074 1.40424849 0.64260322 1.70366881 1.2472099 ]]e[[-0.0201407 -0.07188569 0.96036209 0.50390318 -0.08791224 -0.13965724 0.79964181 1.8607074 1.40424849 0.64260322 1.70366881 1.2472099 ]]E[[-0.0201407 -0.07188569 0.96036209 0.50390318] [-0.08791224 -0.13965724 0. 0. ] [ 0.79964181 0. 1.8607074 1.40424849] [ 0.64260322 0. 1.70366881 1.2472099 ]]
GAL3中的最后两个计算步骤:
W_alpha:对E应用softmax函数
self.left:gal2.A.T与W_alpha的矩阵乘法
结果如下:
W_alpha[[0.15862414 0.15062488 0.42285965 0.26789133] [0.24193418 0.22973368 0.26416607 0.26416607] [0.16208847 0.07285714 0.46834625 0.29670814] [0.16010498 0.08420266 0.46261506 0.2930773 ]]left[[0.72275177 0.53741836 1.61798703 1.12184284] [0.40055832 0.38035856 0.68702572 0.5320574 ] [0.48081759 0.30768468 1.35382096 0.85767677] [0.48081759 0.30768468 1.35382096 0.85767677]]
GAL3的唯一"输出"是left,因此它被赋值给self。
至此,我们已经计算出原始方程的左侧和右侧(gal1.XatWT)。
GAL4的代码实现及主函数如下:
class GAL4: def __init__(self, gal1: GAL1, gal3: GAL3): self.H = gal3.left @ gal1.XatWT print('H\n', self.H, '\n')if __name__ == '__main__': gal_1 = GAL1() gal_2 = GAL2(gal_1) gal_3 = GAL3(gal_2) gal_4 = GAL4(gal_1, gal_3)
最终结果H为:
H[[-1.10126376 1.99749693] [-0.33950544 0.97045933] [-1.03570438 1.53614075] [-1.03570438 1.53614075]]
在这里,我们将原始方程的左侧和右侧进行矩阵乘法运算,得到最终结果。
图注意力层的结构分析从文章开头的图和上面"main"中的代码可以看出,每个GALx仅依赖于前一个GAL(x-1),除了GAL4,它同时依赖于GAL1和GAL3。通过对代码进行分类和封装,我们使其结构更加清晰,从而更易于理解。
该图由位置(椭圆)和转移(矩形)组成,因此被称为位置-转移图。在本文中,我们仅针对GAL特定实现的位置-转移图进行直观分析。有关位置-转移图的更详细信息,请参考我之前的文章(参考文献[PT-GNN-TD])中的"位置-转移图基础"部分。
下面我们将详细分析GAL位置-转移图的各个组成部分。

GAL1结构相对简单,仅执行一次矩阵乘法运算。但其结果是原始方程的整个右侧,也是GAL2和GAL4的主要非邻接相关输入。
将这两个组件合并分析是因为它们之间的连接较为紧密。GAL3利用了GAL2的值A和XatWT_concat,以及GAL2的方法reshape。我们通过标记来自输入引用gal2的弧线来突出每个值或方法的使用位置。
同样,GAL2的connections使用虚线表示,因为它仅在公开方法reshape中使用。

GAL2专注于矩阵操作,是邻接矩阵A"注入"到原始方程的关键点。因此,GAL2是以图结构为中心的组件。
GAL3同样执行矩阵操作,但其核心功能是应用非线性函数(leaky_relu)和归一化操作(softmax)。注意力权重矩阵W_att的引入对GAL3的功能也至关重要。GAL3是以注意力机制为中心的组件。

与GAL1类似,GAL4的结构也相对简单,仅执行一次矩阵乘法。它将方程的左侧gal3.left与右侧gal1.XatWT结合。GAL4是唯一一个接收来自多个组件输入的类,因此它扮演着"混合器"的角色,在"串联"和"并联"模式下连接节点特征、邻接关系和注意力机制。
核心代码以下是实际PyG库中GATv2Conv的核心代码,涵盖了我们使用NumPy模拟的大部分功能:
def edge_update(self, x_j: Tensor, x_i: Tensor, edge_attr: OptTensor, index: Tensor, ptr: OptTensor, dim_size: Optional[int]) -> Tensor: x = x_i + x_j # some conditional edge code removed... // 删除了一些条件边缘代码... x = F.leaky_relu(x, self.negative_slope) alpha = (x * self.att).sum(dim=-1) alpha = softmax(alpha, index, ptr, dim_size) alpha = F.dropout(alpha, p=self.dropout, training=self.training) return alphadef message(self, x_j: Tensor, alpha: Tensor) -> Tensor: return x_j * alpha.unsqueeze(-1)
忽略MessagePassing的部分复杂性,我们可以看到实际的PyG代码与我们的NumPy实现在核心逻辑上非常相似。
总结通过本文的分析,我们已经深入剖析了图神经网络自注意力机制的内部工作原理。从数学表达式到代码实现再到可视化图形,我们提供了一个全方位的视角来理解注意力权重如何在图结构数据中生成和应用。
通过位置-转移图的概念框架,我们不仅展示了计算流程,还揭示了各组件之间的依赖关系,为图神经网络的可解释性研究提供了新的思路。
https://avoid.overfit.cn/post/1b68891a54a543da8d4f72fb2491d7c8
作者:John Baumgarten
