今天凌晨,OpenAI 发布了新一代最强大模型——o1,被种草几个月的”草莓“终于来了!
这一次,OpenAI 并没有延续之前的 GPT-3.5、GPT-4、GPT-4o 命名逻辑,而是推出的一个全新的系列——o1。
OpenAI 官方的解释是:
”这是一系列新的 AI 模型,旨在花更多时间思考后再做出反应。这些模型可以推理复杂的任务,并解决比以前的科学、编码和数学模型更难的问题。“
如果说之前的 GPT 系列模型更擅长语言类的”文科学生“,那 o1 系列将是一个妥妥的”理工天才“!
所以 OpenAI 这次从 1 重新开始计数,命名为 o1。

o1 模型有多炸裂,看下面这张图就知道了。

① 在国际数学奥林匹克(IMO)资格考试中,GPT-4o 只正确解决了 13% 的问题,而 o1 解决了 83% 的难题;
②编码,OpenAI o1 在竞争性编程问题 (Codeforces) 正确率达到惊人的 89%,而 GPT-4o 仅仅只有 11%;
③ o1 在物理、化学、生物学科中的表现达到了博士生水平,78 分更是超越了人类专家的 69.7 分。
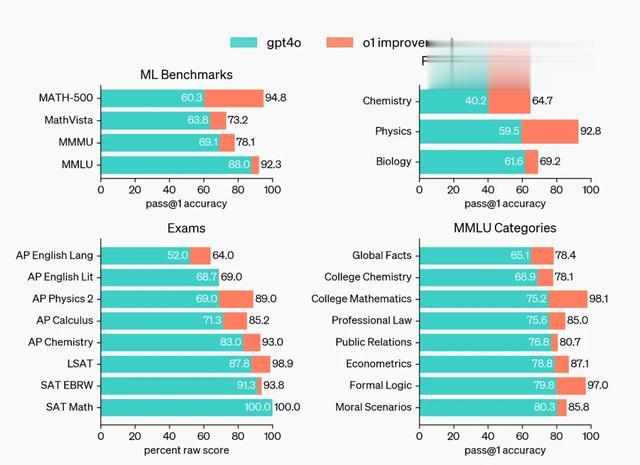
在各类基准测试上,o1 对 GPT-4o 也做到了全面碾压。
大家都常用来测试的 MATH 和 GSM8K 更是被直接干崩,因为 o1 表现太好,不得已只能用美国奥数的题目来评比。

炸了,真的炸了。
OpenAI o1模型发布,也标志着困扰大模型通往 AGI 的一块重要短板,被补齐了!
接下来,AGI 将再无阻碍。
OpenAI o1 大模型工作原理
在官方博客上,OpenAI 对 o1 系列语言模型做了详细的技术介绍。

OpenAI o1 是经过自我博弈强化学习(Self-play RL)训练来执行复杂推理任务的新型语言模型。
这个过程类似于,人类在回答难题之前,可能会思考很长时间。
尝试解决问题时,o1 也会使用一系列思维,通过强化学习,学会磨练其思维链并完善其策略,认识并纠正错误。
思考+思维链+自我纠错
这个过程将极大地提高了模型的推理能力。

让 OpenAI 研究人员惊喜的是:随着更多的强化学习投入和思考时间的延长,o1 模型的性能也在不断地提高。
而这,与 LLM 预训练时提高性能的方法有很大不同。
通过强化学习,o1 模型学会了使用思维链,分步骤回答问题。也就是说,在回答困难问题前,o1模型就像人类一样,可以自我纠正学习。
↓ 发现问题↓ 思考问题↓ 自我纠错→ 给到正确答案
大家发现没有,这妥妥的理工科学霸思维。
比人类学霸更厉害的是,OpenAI-o1 背后还有数万亿的训练数据库,未来的 o2、o3……将超乎想象。
需要注意的是:当前版本的 o1 并不是所有 LLM 应用场景全面加强。
因为 o1 模型的复杂推理非常消耗时间,在文章写作和内容编辑方面,o1模型不仅会浪费很长时间来思考,得出的结果也并不尽人意。

所以在遇到这类问题时,官方建议仍然可以使用 GPT-4o 模型来解决。
OpenAI-o1 可以用了吗?
4 小时前,OpenAI CEO 山姆·奥特曼在媒体表示:
目前,OpenAI-o1 模型已向所有 ChatGPT Plus 和 Team 用户开放,未来会考虑对免费用户开放。

因为其”强推理“能力,对应的能耗也来了个超级加倍,目前 Plus 用户 o1 预览版每周 30 条,o1-mini 每周 50 条。
大家注意上面的时间,不是每天,而是每周。
除此之外,开发者也能通过 API 访问使用,其中 mini 模型比原模型便宜 80%,输入 100M Token/3美元,输出 100M Token/12美元。

OK,今天的介绍就到这里,有 GPT Plus 的小伙伴,赶紧去体验一下吧!
