没有Python程序不使用字典,即使不直接出现在我们自己编写的代码中,我们也会在无形中、间接用到字典(日用而不自知)。所以,字典(dict)是Python实现的基石。
一些Python核心结构在内存中以字典的形式存在,比如:类和实例属性、模块命名空间、函数的关键字参数等。
此外,__builtins__.__dict__中存储着所有内置类型、对象和函数。
所以,本文就字典相关的内容,做一个补充说明。
什么是“可哈希”前面的文章中关于字典的介绍时,我们已经有所提及,字典的键必须是可哈希的。
“可哈希”在Python中是这样说明的:
如果一个对象的哈希值在整个生命周期内永不改变(依托__hash__()方法),而且可与其他对象进行比较(依托__eq__()方法),那么这个对象就是可哈希的。
两个可哈希对象仅当哈希值相同时才相等。
1、数值类型、不可变的扁平类型(比如str和bytes)均是可哈希的。
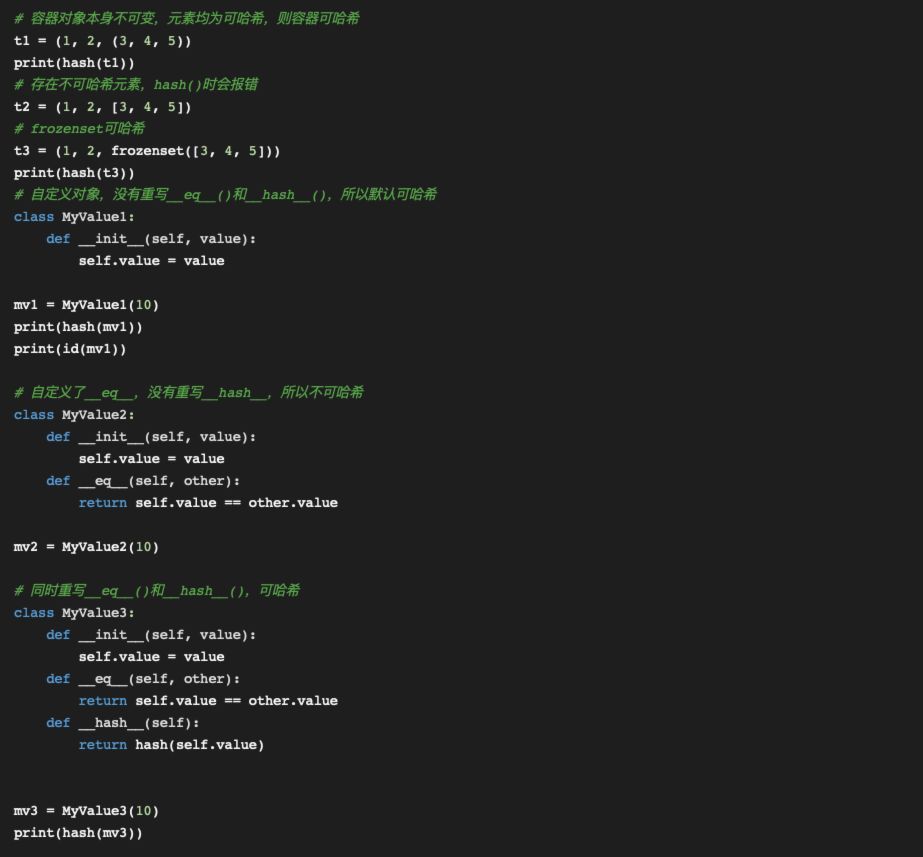
2、如果容器类型是不可变的,且所含的对象均是可哈希的,那么容器类型自身也是可哈希的。所以,tuple对象是不可变的,仅当tuple中所有元素项均可哈希,这个特定的tuple对象才是可哈希的。
3、frozenset对象全部是可哈希的。
4、用户自定义的类型,默认是可哈希的,因为自定义类型的哈希值基于id(),而且继承自obejct类的__eq__()方法只不过是比较对象ID。如果自己实现了__eq__()方法,根据对象内部状态进行比较,那么仅当__hash__()方法始终返回同一个哈希值时,对象才是可哈希的。
下面是关于上面4条是否可哈希规则的验证代码:
在前面的文章中,我们通过字典dict对象的实例方法:keys()、values()、items()进行字典数据的遍历。
从dict的定义描述中可以看到,这些方法返回的均是基于dict内部实现使用的数据结构的视图:
这些视图是动态视图,根据dict对象的变化同步更新:
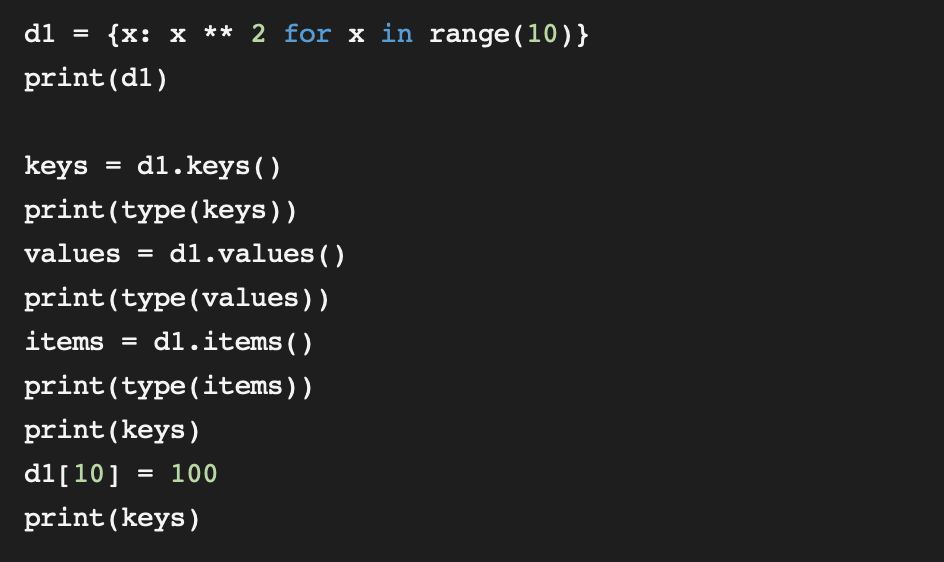
此外,除了dict_values类是相对简单的字典视图,dict_keys和dict_items还实现了多个集合方法,基本与frozenset类相当。
字典的实现由于字典的关键作用,Python对字典做了高度优化,而且一直不断在改进。Python中字典能够如此高效,主要归功于其底层的哈希表。
此外,内置类型中的set和frozenset也基于哈希表来实现。

虽然基于哈希表的实现,带来了更高的效率。但是,也对使用上带来一些影响:
1、键必须是可哈希的。
2、通过键访问项的速度非常快,通过计算键的哈希值可以直接定位键,然后找出索引在哈希表中的偏移量,稍微尝试几次就能找到匹配到的条目。
3、在CPython3.6中,dict的内存布局更为紧凑,顺带了一个副作用是键的顺序得以保留。当然,Python3.7开始,将这个副作用写入了标准,正式支持保留键的插入顺序。
4、尽管使用了紧凑布局,但是,字典仍然需要占用大量内存,这是不可避免的。
5、为了节省内存,不要在__init__()方法之外创建实例属性。因为,Python默认在特殊的__dict__属性中存储实例属性,而这个属性是一个字典,依附在各个实例上。自Python3.3起,类的实例可以共用一个哈希表,随类一起存储。如果新的实例与__init__()返回的第一个实例拥有相同的属性名称,那么新实例的__dict__属性就共享这个哈希表,仅以指针数组的形式存储新实例的属性值。如果__init__()方法执行完毕后再添加实例属性,Python就不得不为这个实例的__dict__属性创建一个新哈希表。

