2. **文章创作**
你是否还记得某个看似弱小但出乎意料地击败对手的情景?
这就像是智能手机刚上市时,人们怀疑小小的设备能否取代电脑,可现实证明它不仅仅实现了,还彻底改变了我们的生活。
今天的故事有点类似,但舞台换成了人工智能领域。
在某次AI领域的研讨会上,一个卑微但强大的小角色登场了。

想象清华大学的研究团队站在讲台前,既紧张又自信。
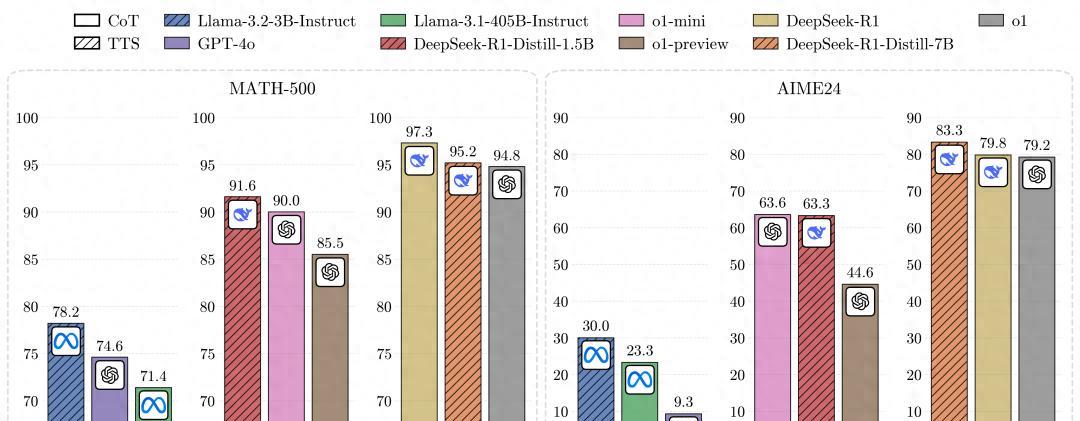
手中的PPT展示的不是什么高深玄妙的理论,而是一个震惊全场的数据结果:他们的1B模型竟然打败了405B这个巨无霸。
现场的同行瞪大了眼睛,不敢相信耳朵,他们一直以为只有参数多的大模型才能取得胜利。
这就好比一只小猫突然战胜了一只狮子,不禁引发了人们的激烈讨论和热烈思考。
这究竟是怎么做到的?

清华团队的秘诀是什么?
一个普通的下午,研究员们聚集在一起,商讨如何更有效地利用现有的计算资源。
有人提出了一个大胆的假设:能不能通过优化计算策略,提升较小模型的能力?
这听起来像是异想天开,但他们决定试一试。
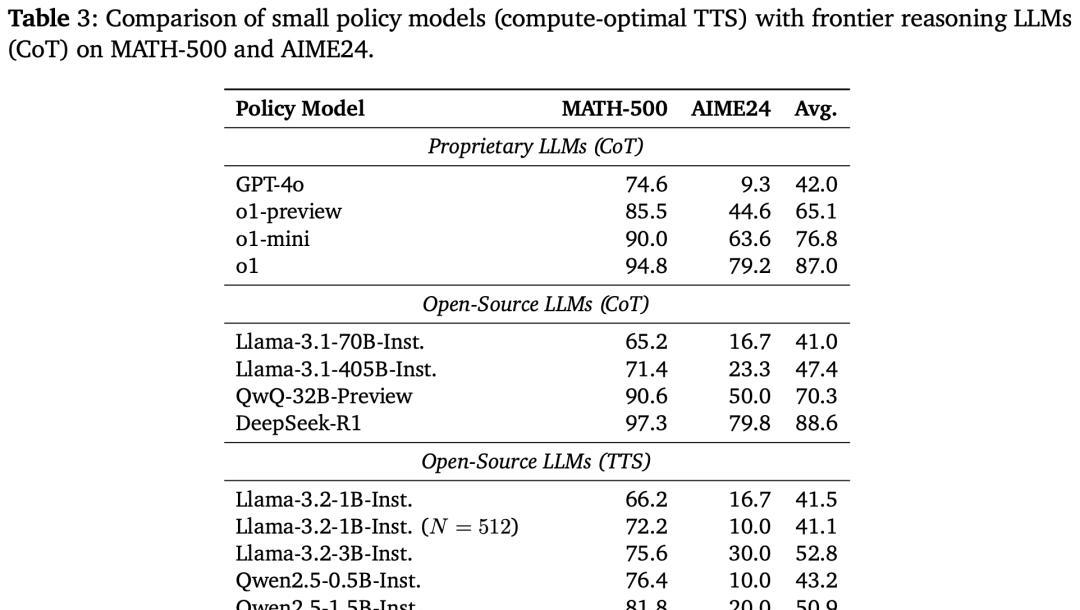
于是,他们在测试时采用了一种最新的扩展计算策略,叫做“计算最优测试时扩展策略”(TTS)。
简单来说,这种方法就是在模型推理时,更聪明地分配计算资源,确保每一个问题都能得到最优的计算支持。
结果如何呢?
他们用1B的模型,通过这套策略,成功碾压了405B的巨无霸。
研究结果不仅仅是冰冷的数字,还代表了一种全新的思维方式,这种策略的不仅仅停留在理论层面,而是通过实际应用展现其强大的潜力。
如果你有一个小而精的工具,可以战胜大而全的武器,是否会觉得惊讶?
在AI领域,大家普遍认为模型参数越大,性能就越好。
清华团队的实验结果却打破了这一固有认知。
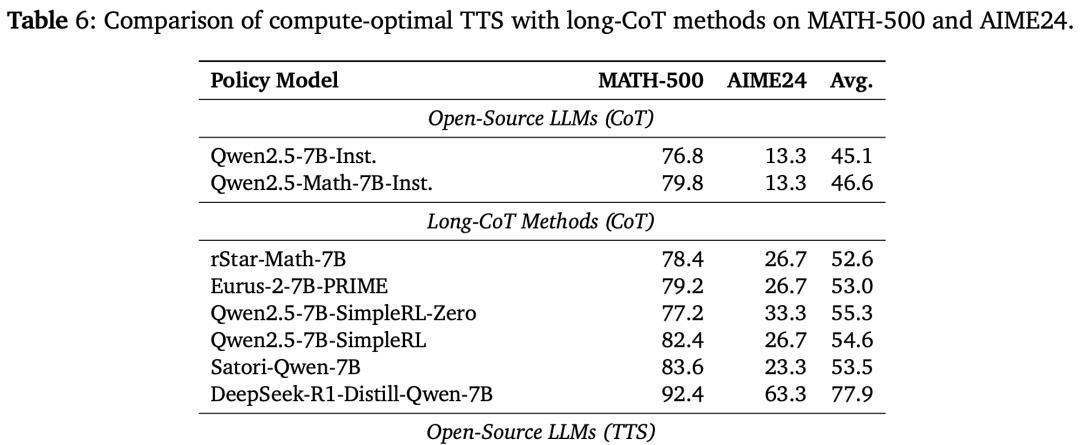
在他们的实验中,0.5B的小模型在某些数学任务上表现优于知名的GPT-4o。
更令人惊叹的是,7B的模型甚至打败了o1和DeepSeek R1这类顶尖竞争对手。
这些验证结果表明,通过优化计算策略,小模型也能达到甚至超越大模型的表现。
这就像用小刀雕刻出精美的艺术品,不仅证明了技术的可行性,更启发了许多新的研究方向。
那么,这种计算最优策略是怎么应用的?
我们可以通过研究团队的实际操作来看个究竟。
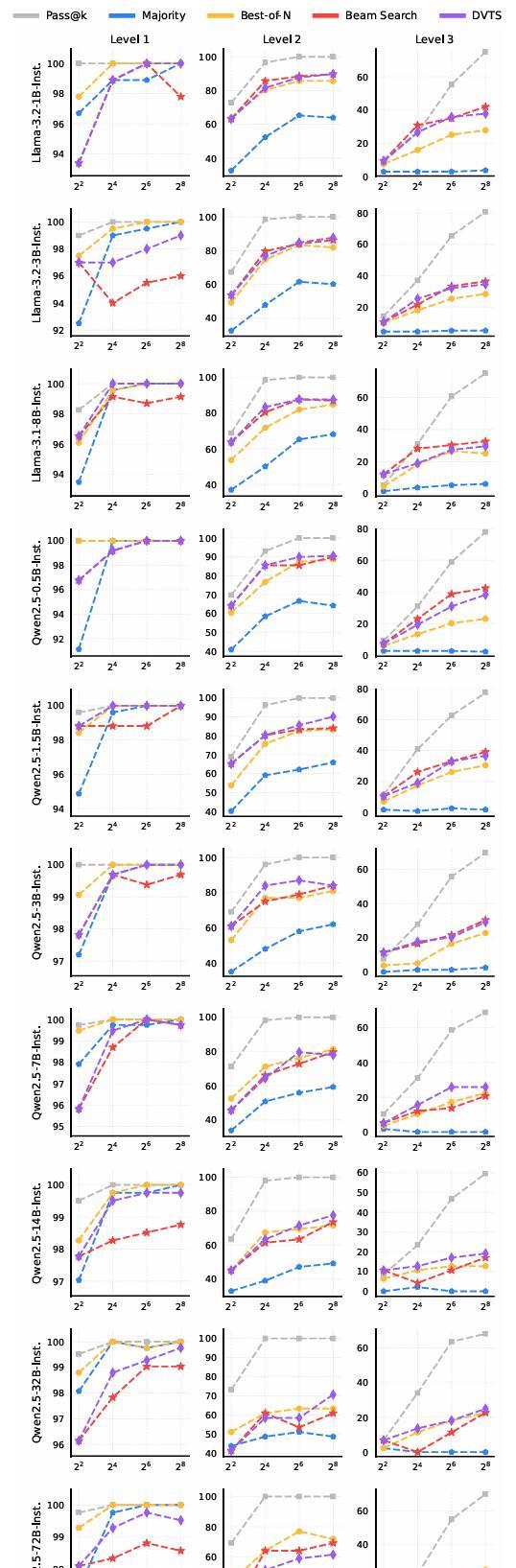
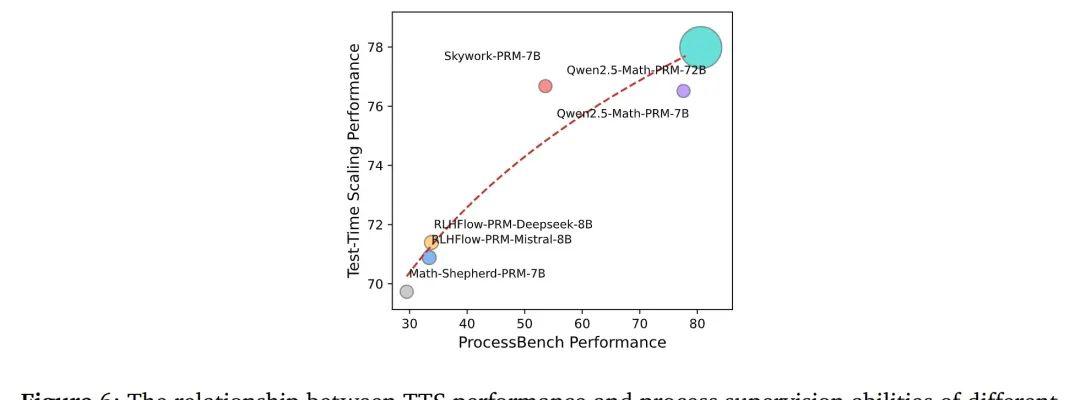
研究员们选择了在推理时提前分配计算预算,并通过一种叫做在线策略模型验证(PRM)的方法,逐步调整计算资源,确保每一步都最优。
他们不仅使用了这一策略,还进行了多次验证,发现不同策略模型下,这种方法确实能够提升整体性能。
尤其是在一些复杂任务中,较小的模型通过这种计算优化,表现甚至比大模型还要出色。
清华团队不仅仅是应用了这一技术,还通过不断的实验和数据分析,调整每一个计算细节,最终实现了小模型在复杂任务中的大逆袭。
打破常规的创新思维往往能带来意想不到的惊喜。
这次清华团队的小模型挑战大巨无霸的故事,不仅展示了新的技术手段,更是对传统思维的一次冲击。
或许在未来,AI领域会涌现出更多这样的小型但高效的创新成果。

就像一个厨艺平平的人,突然发现了一种新调料,使得他的菜品变得美味无比,从此改变了他对烹饪的理解。
这种灵感的火花,往往从最看似不起眼的地方冒出来。
而清华团队的这次研究,给AI领域带来的,正是这样一种可能性。
无论你是在科技领域打拼,还是在其他行业奋斗,也许这次的突破能带给你一些启发。
通过优化现有资源,从不同的角度思考问题,或许也能够为你打开一扇新的成功之门。
这正是科技的魅力所在,也是我们不断探索的动力源泉。
希望这篇文章能给你带来一些新的思考,也能让你对AI领域的这种小模型逆袭大模型的现象,有一个更清晰的认识。
科技进步不仅仅是参数的增加,更是智慧的体现。
清华团队的这次成功,无疑为我们展示了这种智慧的无限可能。
