A study on Prompt Design, Advantages and Limitations of ChatGPT for Deep Learning Program Repair
Jialun Cao, Meiziniu Li, Ming Wen, Shing-Chi Cheung
引用
Cao J, Li M, Wen M, et al. A study on prompt design, advantages and limitations of chatgpt for deep learning program repair[J]. arXiv preprint arXiv:2304.08191, 2023.
论文:https://arxiv.org/abs/2304.08191
仓库:https://levelup.gitconnected.com/chatgpts-abilities-a-comprehensive-list-of-tasks-the-ai-language-model-can-perform-5a44492ab94.
摘要
ChatGPT已经彻底改变了许多研究和工业领域。ChatGPT在软件工程中显示出巨大的潜力,可以促进各种传统任务,如程序修复、代码理解和代码生成。然而,自动程序修复(APR)是否适用于深度学习(DL)程序仍然是未知的。DL程序的决策逻辑没有明确地编码在源代码中,这对APR提出了独特的挑战。而为了修复DL程序,APR方法不仅需要从语法上解析源代码,还需要理解代码意图。尽管之前的工作做得最好,但错误定位的性能仍然远不能令人满意(只有大约30%)。因此,在本文中,我们通过提出三个研究问题来探索ChatGPT对深度学习程序修复的能力。(1) ChatGPT能有效调试DL程序吗?(2)如何通过提示提高ChatGPT的修复性能?(3)对话能以何种方式帮助促进修复?在此基础上,我们对DL程序修复的提示设计有用的常见方面进行了分类。此外,我们还提出了各种提示模板来提高性能,并总结了ChatGPT功能的优缺点,例如检测不良代码气味、代码重构和检测API滥用/弃用。
1 引言
大型语言模型如ChatGPT,由于其在执行广泛任务方面的显着有效性而受到越来越多的关注。大型语言模型的最新进展引发了各种研究,这些研究检查了这些模型在软件开发任务中的使用。这些研究分析了法学硕士在程序修复、代码理解和代码生成方面的能力。他们的研究结果表明,法学硕士在程序理解和程序修复方面明显优于最先进的技术。此外,最近的一项研究评估了程序修复性能在一个由40个教科书Python程序组成的基准(例如,宽度优先搜索,Hanoi, LCS-length)上的ChatGPT。评估表明,ChatGPT以最先进的技术实现了具有竞争力的表现。此外,他们的初步尝试表明,利用提示可以进一步提高ChatGPT的性能。
在本文中,我们研究了使用法学硕士来调试和修复深度学习(DL)程序的双重视角(即利弊)。我们的研究基于ChatGPT,因为它在可比较的法学硕士中的影响、性能和可用性。此外,我们将重点放在修复DL程序上,主要有两个原因。首先,与传统程序不同,深度学习程序通过指导训练产生的深度神经网络(DNN)[7]来体现其功能。这意味着决策逻辑并不直接编码在源代码中。因此,为了修复深度学习程序,ChatGPT不仅需要从语法上解析源代码,还需要理解深度学习程序修复或优化结果dnn的意图。除了范式上的差异,我们的研究与之前的研究在选择具有明显更多依赖关系(6倍多的库)和功能(超过行数的两倍)的程序主题方面也有所不同。我们的研究旨在回答三个研究问题。
RQ1。ChatGPT可以有效地调试DL程序吗?本RQ旨在了解ChatGPT在深度学习程序调试中的性能,并将其与两种最先进的技术进行比较。特别地,我们将调试任务分为三个步骤,即错误检测、错误定位和程序修复。为了评估,我们分别量化了检测到的错误程序数量(错误检测能力)、定位到的错误数量(错误本地化能力)和修复的错误数量(程序修复能力)。因此,可以更好地了解ChatGPT的优缺点。
RQ2。如何通过提示提高ChatGPT的修复性能?正如最近几项研究所指出的,即时工程可以帮助法学硕士在各种应用和研究课题中提供更好的答案。然而,promp中应该包含哪些信息仍然没有被探索。为了回答这个问题,我们转向开发人员提出的现实问题,对他们的问题进行分析和分类。在我们的定量分析之上,我们提出了一个增强的提示模板。最后,我们在相同的基准上利用这个增强的提示模板来揭示其有效性。
RQ3。对话在哪些方面可以帮助修复?由于ChatGPT被设计为与用户交互,因此是否以及如何执行对话可以帮助促进程序修复是未知的。因此,我们探索了故障位置和不正确修复的提示是否可以进一步提高性能。
在此基础上,我们在研究过程中总结了ChatGPT能力的利弊。为了突出结果,在整篇论文中,我们使用三个图标来注释在调试DL程序中使用ChatGPT的优点,缺点和特性。例如,DL库中已弃用的API可能会影响自动DL程序修复,因为ChatGPT无法识别旧版本中使用的参数名称。我们还注意到,虽然代码重构可以帮助简化代码,但某些重构(例如变量重命名)可能会因为变量名不一致而导致程序崩溃。此外,借助ChatGPT的对话功能,可以提高程序的修复能力,但同时,随着输入序列的增加,可能会出现猫的遗忘或误解,阻碍进一步的改进。
本文工作的贡献归纳如下:
(1)对ChatGPT的深度学习程序调试(即故障检测、故障定位和程序修复)能力进行了研究。这项研究补充了之前使用具有更复杂功能和更多依赖关系的有bug的程序的工作。
(2)我们对提示设计有用的常见方面进行了分类,并提出了对深度学习程序修复更有效的增强提示模板。
(3)我们总结了ChatGPT修复程序的特点。我们的发现表明,通过提供更多的代码意图,程序可以得到更好的修复。此外,ChatGPT擅长处理API误用和弃用,而在默认参数识别和处理方面则比较短。
2 RQ1.DL程序调试
在本节中,我们将探讨ChatGPT针对基准测试进行深度学习程序调试的能力。首先。我们使用下面的基本提示模板(简称PT-B)。

表1:基准比较
其中代码由基准测试中每个有bug的DL程序填充。表2展示了RQ1的总体结果。使用PT-B进行ChatGPT的结果表示为(ChatGPTPT-B)表。在下文中,我们将对结果进行详细解释。

表2:错误检测、错误定位和程序修复的比较。(AT: AutoTrainer, DFD: DeepFD,ChatGPT−:ChatGPT带提示模板PT-B (RQ1),ChatGPT−:ChatGPT带提示模板PT-E (QR2))。
2.1 故障检测
我们首先检查这些方法是否可以检测到现有的故障。结果如表2(检测)所示。特别地,对于每个有bug的程序,我们报告了这些方法是否可以检测到错误的存在,这些错误被标记为Y/N (Yes/No)。对于ChatGPT,我们报告5倍的Y/N。
从表中可以看出,基线DeepFD (DFD)可以检测到所有有bug的深度学习程序(34/34),优于ChatGPTPT-B,后者检测到34个有bug的程序中的27个。有七个有bug的程序,其中ChatGPT在五轮的大多数情况下都无法检测到错误。对于其中的两个(即48385830和39810655),ChatGPT在所有五轮中都没有检测到故障。对于其中四个(即50079585、50481178、58237726和51181393),ChatGPT至少在一轮中报告错误的存在,并试图在其他一些轮中请求更多信息,例如代码的意图和用于训练的数据。
在下文中,我们将讨论ChatGPT如何为这些故障类型提供答案。(1)语法错误。ChatGPT通常报告是否程序在回复的开头是否语法正确。包含语法错误(例如,未定义的变量,缺少导入依赖)的程序可以阻止ChatGPT检测其他类型的错误。(2)函数式错误。这种类型的故障通常导致程序不能正确地执行其预期的功能。为了检测此类错误,ChatGPT需要了解代码意图,然后在实现与ChatGPT所理解的代码意图不同时检测并修复错误。例如,如果DL程序首先使用one-hot编码处理标签(即,预处理表明它是用于分类问题的数据集),然后使用mean_absolute_error(不适用于分类问题)来计算损失。在这种情况下,ChatGPT所理解的实现和功能之间存在差距,因此它会报告功能错误。另一个有趣的发现是,ChatGPT已经学会了检测缺失或冗余的实现。例如,它建议添加代码来可视化训练过程或删除冗余的print语句。(3)代码异味。代码异味不一定会导致功能错误。它们更可能是糟糕的编码实践。ChatGPT能够建议可能的方法来提高程序的质量(例如,代码重构)或性能(例如,用可用的api替换自实现的方法)。
2.2 故障定位
准确的错误定位是实现程序自动修复的关键一步,因此我们检查程序中的错误是否可以被正确定位。由于在一个程序中可能有不止一个错误,我们展示了每种方法正确定位的错误数量。对于ChatGPT,我们列出每轮的结果,并突出显示五轮中的最佳结果。
如表2所示,现有最好的工作可以正确定位29/72个错误。ChatGPT (PT-B)定位的故障略少,为23/72。结果远不能令人满意。通过进一步分析,我们发现,在属于18例的49个(72 - 23)漏检故障中,有16个(属于7例)甚至无法检测到,有32个(属于11例)可以检测到但无法正确定位。特别是,我们对11个案例中的32个错误进行了更仔细的分析,我们观察到,ChatGPT并没有识别导致严重后果的错误(例如,缺少数据预处理),而是倾向于本地化过时的api(39525358、59278771和37624102),当它被要求修复没有明确修复目标(即提高准确性)的程序时,坏代码会变得难闻(44998910、48221692、50306988、48934338、31627380、37213388、47932589)。虽然上述改进可以使程序的质量受益,但它们并不一定是严重的错误。例如,添加更多的注释确实提高了代码的可读性,而更严重的错误(如缺失数据预处理、训练策略不当)值得更多的关注,但却逃过了错误定位。
此外,我们观察到,遗漏或错误的本地化主要是由于对代码意图的误解。例如,在一个案例(56380303)中,ChatGPT错误地将输出层中的激活函数定位为故障,因为它错误地认为DL程序是为回归程序训练的。虽然它最终被证明是一个分类问题,因此局部化的故障是一个虚警。
然而,DL程序是在线性数据集上训练的,开发人员发现所有的输出范围都在0到1之间。故障是由于激活函数sigmoid不合适造成的,其输出只能在0到1之间。在不知道具体学习任务的情况下,ChatGPT很难发现故障。
2.3 程序修复
考虑到错误定位的性能,程序修复的不理想性能是合理的。从表2ChatGPTPT−B可以看出,只有16/72的故障可以通过Chat-GPT正确修复。这个数字是基线(7/72)实现的两倍。此外,值得注意的是,ChatGPT可以完全修复6个案例(48251943、31880720、59325381、45337371、47352366、42800203),而AutoTrainer只能完全修复两个案例(47352366、37624102)。
此外,在回复中,我们总结了Chat-GPT对修复程序的回复方式。主要有三种回复方式。
(1)用完整的修复代码进行解释。这种方式是直接的,通常会附带一个关于修复策略的解释。人们可以直接执行带有完整代码的程序,以查看修复是否有效。然而,值得注意的是,代码重构经常发生。例如,变量X和Y在某些情况下被重命名为x_train和y_train(例如,44066044)。
(2)带有解释的代码片段。此类回复不包含完整的修复代码。相反,它只包含关于修复的代码片段。这样的回复可以机械地用于修理,用修好的线路替换出故障的线路。然而,在某些情况下,返回的代码片段会重命名变量。直接替换这样的代码行可能会导致崩溃。
(3)对修复策略的解释。在这些回复中,没有或很少提供代码。ChatGPT对修复策略提出建议,而通常,具体的修复并不清楚。在这种情况下,用户需要根据建议手动修复代码,需要进行一些尝试才能找到最优修复。
3 RQ2.提示的影响
ChatGPT在RQ1中的实验结果并不令人满意,因此我们有动力设计一个更好的提示,利用ChatGPT的力量来提高程序修复性能。
3.1 研究现实世界的问题
如RQ1所示,提示设计需要提供更多信息,如代码意图。然而,提示中应该包含哪些信息?为了更好地探究这个问题,我们转向了真实开发者提出的查询。特别地,我们从StackOverflow中抓取了这些案例的文本(代码块除外),然后通过手动分析将描述仔细分类为以下七种类型的信息。
症状阐明了用户对修复的意图。它允许ChatGPT更好地理解用户想要修复的症状(例如,语法、依赖项或性能错误)。常见的症状包括输出异常(如NaN、零输出)、结果不理想(如精度低、损失巨大)、过拟合或收敛缓慢。
Task解释了代码的设计目的。损失函数categorical_crosentropy和mean_absolte_ error在DL程序中都是语法正确的。虽然考虑到程序是为分类问题设计的背景,第一个损失函数比后者更可取。常见的任务包括分类问题(例如,多标签或二分类)和回归问题。
数据集描述输入数据的特征(特征和标签)。获取数据集的知识可以帮助ChatGPT更好地理解代码意图。例如,如果ChatGPT知道输入数据是图像,它就有更高的机会识别正确的数据预处理方法、损失函数等。此外,输入数据的范围也会影响数据预处理的方式。例如,知道输入值范围从0到255,ChatGPT更有可能在训练之前指出需要进行规范化。一般来说,关于的描述数据集包括训练数据的类型(例如,图像),数据的分布(例如,一组正弦波),正/负值,训练数据的维度,以及标签的数量。在数据集是众所周知的情况下也是如此,例如MNIST和Iris。在这种情况下,指定数据集名称是有信息量和帮助的。
Version/Dependency指定了所使用的库的版本。由于库正在迅速发展,指定库的版本可能有助于正确地重现代码并获得适当的API推荐。Python的版本,DL库的版本(例如,PyTorch, Tensorflow)和后端版本通常在StackOverflow中看到。
修复尝试是指开发人员已经尝试过但未能达到预期目标的修复。尝试修复有助于避免无效的修复策略。
超参数和模型架构提供了对网络和训练策略的简要介绍。虽然这些信息可以很容易地在代码中识别,但关于这些信息的案例很少。
我们在图1中将每种类型信息的统计数据可视化。可以清楚地看到,几乎所有病例都观察到了症状的描述(33/34)。其次是任务描述(26/34)和数据集描述(24/34)。剩下的信息是偶尔观察到的。
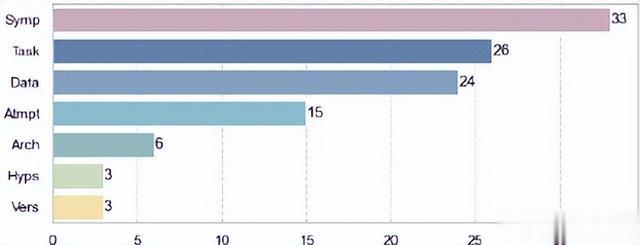
图1:问题描述的统计
3.2 增强提示模板设计
在从现实问题观察的基础上,我们提出了一个增强的提示模板(简称。PT-E)如下:

其中X描述任务(例如,分类,回归),Y指定数据集(例如,MNIST, ImageNet,跟随正弦波的数字),Z描述针对症状的目标(例如,提高准确性)。一个示例提示如下所示:

如果X/Y/Z无法使用,我们将对提示进行如下调整。

3.3 增强提示的有效性
我们使用上述增强的提示模板,对照基准重新运行实验,检验是否有效故障检测、定位和修复的统计可以增强。请注意,对于学习任务/数据集/目标不可用的情况,我们使用第4.2节中列出的变体模板。
实验结果如表2 (ChatGPTPT-E)所示。我们可以看到,改进是显著的。在故障检测方面,可以检测到所有有bug的程序,达到了与现有最佳方法(34/34)相当的结果,而使用基本提示模板时则达到了27/34。此外,ChatGPTPT-E的置信度远高于ChatGPTPT-B,即增强的ChatGPT几乎每轮都报告故障存在(5/5)。对于错误定位,正确定位的错误数量从23个翻倍到50个。正确修复的错误数量从16个增加到43个,增加了三倍。此外,在增强提示模板的辅助下,可以完成修复的案例有16/34个,而使用基本模板只有6/34个。显著的改进说明了增强后的prompt模板的有效性。
我们还注意到,在向ChatGPT提供修复目标(即模板中的[Z])之后,修复不良代码气味和额外功能的情况减少了,而真正的阳性情况增加了。这表明,有了意图修复。
4 RQ3.ChatGPT对话的有效性
ChatGPT的一个重要特征是用户交互,因此我们进一步探索是否可以通过对话提供更多信息来增强DL程序的修复能力。正如最近的一项研究[40]所展示的那样,对话可以改善常规程序修复的最终修复。然而,如何在深度学习程序修复中有效地使用ChatGPT进行多轮对话仍然是一个未知的问题。然后,我们推动了这项研究,寻求更好的方法来利用对话特征。
首先,我们使用下面的提示模板涉及故障定位信息。特别是,对于第4节中未能完全修复的案例(即18个案例),我们首先使用以下提示模板(提示模板(locations),简称PT-Loc)提供故障位置。然后,如果仍然存在未修复的故障,我们进一步提供上一轮使用中未正确修复的剩余故障的位置以下提示模板(提示模板(IncR),简称PT-IncR):

其中,PT-Loc中的故障定位信息是根据基准测试提供的信息自动填写的[7],PT-IncR中的剩余位置是经过分析后填写的。
图2展示了4轮的结果。我们用不同的提示模板可视化了修复正确和错误的错误数量的变化。可以清楚地看到,在使用增强提示PT-E(包括症状、学习任务和训练数据集的信息)后,正确修复的故障数量从16个增加到43个。然后,随着故障位置的提示,数量增加到55个。最后,有了未修复故障位置的提示,可以再修复3个故障。

图2:使用提示模板PT-B、PT-E和PT-Loc和PT-IncR修复故障的正确- (Y)和错误- (N)的数量。
此外,还有少数故障上一轮修复正确,但下一轮又变回故障。这主要是因为ChatGPT不确定它的修复,所以它迭代地没有信心地修复这些错误。此外,我们可以看到,即使我们提供了未修复故障的位置,仍然有14个故障没有修复。
仔细分析,我们总结出两个原因,一个错误一直到最后一轮对话才得到修复。首先,ChatGPT忽略所提供的信息并修复其他位置。其次,ChatGPT坚持认为所提供的位置不会因为对代码意图的误解而出错。
5 结论
在本文中,我们研究了ChatGPT在深度学习程序调试中的能力(即故障检测、故障定位和程序修复)。特别地,我们探索了提示符对调试性能的影响,并提出了一个提示符模板来提高性能。此外,我们还探讨了ChatGPT的对话特性可以在多大程度上提高性能。在实验的基础上,我们总结了ChatGPT的回复和的优缺点指出ChatGPT可以帮助促进SE社区的可能方向。
转述:拓紫苑
