Nuances are the Key: Unlocking ChatGPT to Find Failure-Inducing Tests with Differential Prompting
Tsz-On Lia,b, Wenxi Zongc, Yibo Wangc, Haoye Tiand, Ying Wangc,a*, Shing-Chi Cheunga,b*, Jeff Kramere
aThe Hong Kong University of Science and Technology, Hong Kong, China
bGuangzhou HKUST Fok Ying Tung Research Institute, Guangzhou, China
cNortheastern University, Shenyang, China
dUniversity of Luxembourg, Luxembourg, Luxembourg
eImperial College London, London, United Kingdom
{toli,scc}@cse.ust.hk, iamwenxiz@163.com, yibowangcz@outlook.com, haoye.tian@uni.lu,
wangying@swc.neu.edu.cn, j.kramer@imperial.ac.uk
引用
Li T O, Zong W, Wang Y, et al. Nuances are the key: Unlocking chatgpt to find failure-inducing tests with Differential Prompting[C]//2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 2023:14-26.
论文:https://ieeexplore.ieee.org/abstract/document/10298538
仓库:https://differential-prompting.github.io/
摘要
软件缺陷的自动检测是一项重要且极具挑战性的软件工程任务,其核心在于探究如何在一个巨大的搜索空间中高效地找到缺陷诱导测试用例(Failure-Inducting Test Case),并为这些测试用例配备合适的测试预言(Test Oracle)。本文研究了诸如ChatGPT的大语言模型(LLMs,Large Language Models)完成软件缺陷的自动检测时的表现。本文首先探究了ChatGPT直接生成缺陷诱导测试用例的能力,发现其为错误程序生成缺陷诱导用例的概率较低,只有28.8%。作者猜想产生这一结果的原因可能是大语言模型对正确程序和错误程序之间的细微差别(Nuance)不敏感,导致其无法顺应这些差别产生缺陷诱导的测试输入。结合这一猜想,作者展开进一步探索发现:在成功引导ChatGPT关注程序错误和正确间的细微差别之后,ChatGPT往往能够成功生成缺陷诱导用例。在上述结果的驱动下,作者开发了一种名为差分提示(Differential Prompting)的新技术,能够利用由推断意图合成的可编译代码来有效地找到缺陷诱导测试用例。作者在广泛使用的数据集QuixBugs和Codeforces上对本文提出的差分提示技术进行了评估。实验结果结果表明:对于QuixBugs中的程序,差分提示找到缺陷诱导测试用例的概率达75.0%,比最佳基线高出2.6倍;对于Codeforces上的程序,差分提示的成功率为66.7%,比最佳基线高出4.0倍。
1 引言
发现缺陷诱导测试用例(Failure-Inducing Test Cases)是软件测试的主要目标。然而,在实践中找到这样的测试用例是非常具有挑战性的。首先,现代软件系统十分复杂,导致测试用例的搜索空间十分巨大。其次,为了触发并暴露缺陷,测试人员通常需要构建合适的测试预言(Test Oracle),而测试预言的构建通常被认为是一个不可判定问题(Undecidable Problem)。
最近的研究表明:像ChatGPT这种的大语言模型(LLM)在面对程序自动修复等软件工程任务时往往能够发挥出惊人的能力。受到这些工作的启发,本文的作者着手研究调查大语言模型在生成缺陷诱导测试用例时的能力如何。然而,使用大语言模型生成缺陷诱发用例并不是一项简单的工作。作者在QuixBugs数据上直接使用ChatGPT进行了实验,分两阶段提示ChatGPT,旨在引导其生成缺陷诱导用例。对于每个程序,作者首先要求ChatGPT判定给定的程序是否包含错误;当ChatGPT回答“是”时,作者将进一步要求它生成一个缺陷诱导测试用例。作者的实验提供了两点发现:(1)ChatGPT为错误程序寻找缺陷诱导测试用例成功率很低,只有28.8%;(2)ChatGPT经常会错误地判定认为正确程序存在缺陷,并进而为其生成缺陷诱导测试用例。针对这两点发现,作者进行了分析并给出了可能的解释:ChatGPT本质上是一个Transformer(大语言模型通常采用的一种深度学习模型架构),而Transformer架构通常对两个相似的令牌(Token)序列之间的细微差异不敏感。换句话说,当输入的两组令牌序列进包含细微变化时,大语言模型通常倾向于将这两组令牌判定为“相似”。这一特性虽然能够帮助大语言模型容忍输入令牌中的一些噪音,但是也在一定程度上限制了大语言模型识别错误程序的能力,因为错误程序与其相对应的正确程序版本的差别通常也十分微小。
为了应对ChatGPT在寻找缺陷诱导测试用例方面的弱点,本文提出了两个见解:首先,如果程序的意图是已知的,那么寻找缺陷诱导测试用例就会容易得多。程序意图能够帮助ChatGPT将搜索测试用例的重点放在那些能够表现出与程序意图不同行为的测试用例上。其次,ChatGPT在识别细微差别方面的弱点反而可以促进ChatGPT推断程序的意图,因为这样的弱点能够帮助ChatGPT在微错误程序推断意图时忽略其中存在的微小错误。为了验证这一见解,作者同样在QuixBugs数据集上进行了一个实验,要求ChatGPT推断出所有错误程序的实际意图。实验结果表明,ChatGPT正确推断出91.0%错误程序的实际意图。
基于上述结果和提出的两种见解,作者设计并提出了差分提示(Different Prompt)。差分提示是一种能够帮助大语言模型寻找缺陷诱导用例的创新范式,它将缺陷诱导测试用例的搜索的任务划分为三个子任务:程序意图推断、程序生成和差分测试。具体来说,给定一个被测程序,差分提示首先要求ChatGPT推断被测程序的意图,接着通过提示引导ChatGPT生成与被测程序具有相同意图的多个可编译程序。最后,利用这些可编译程序,作者开展查差分测试(Differential Testing)以寻找缺陷诱导测试用例。通过这样做,差分提示绕过了ChatGPT在识别细微差别方面的弱点,同时利用了其推断程序意图的能力。本文的主要贡献包括:
首创工作:作者开展了有关ChatGPT在寻找缺陷诱导测试用例的第一项研究。本文的的发现能够帮助后续研究者理解ChatGPT在搜索缺陷诱导测试用例方面的局限性,并启发该领域未来的研究。创新技术:作者提出了差分提示,一种能够增强大语言模型寻找缺陷诱导测试用例的创新范例。差分提示解锁了ChatGPT在检测软件故障方面的能力,通过将查找导致故障的测试用例的任务表述为程序意图推理、程序生成和差分测试。通过这样做,差分提示将ChatGPT的弱点转变为查找缺陷诱导测试用例的优势。拓展评估:作者对差分提示进行了原型实现,并在QuixBugs和Codeforces上进行了评估。实验结果显示,差分提示帮助ChatGPT在QuixBugs和在Codeforces数据集上分别达成了比最佳基线高2.6倍、高4.0倍的成功率;作者还开放了代码和数据。2 技术介绍
图1展示了差分提示的工作流程,以被测程序为输入,以缺陷诱导测试用例或寻找缺陷诱导测试用例失败的日志信息为输出,差分提示依靠两个组件——程序生成器(第2.2节)和测试用例生器(第2.3节)——来帮助大语言模型准确地发现缺陷诱导测试用例。

图1:差分提示整体工作流程
2.1 术语定义
为避免歧义这里对后续使用到的与测试用例相关的术语进行统一定义。根据测试的结果和断言的类型不同,由差分提示、ChatGPT或Pynguin发现和生成的测试用例可以大致分成以下五类:
正确缺陷诱导测试用例(FT-IA):一个FT-IA包括:(1)一个能够导致程序运行失败的测试输入I,能够触发被测程序中的缺陷,从而给出一个不正确的输出;(2)一个正确的断言A,能够识别不正确的输出。换句话说,换一个FT-IA同时包含真实的缺陷诱导输入和正确的测试断言。碰巧缺陷诱导测试用例(FA-Ia):FT-Ia与FT-IA相似,二者的区别在于FT-Ia断言a中关于期望程序输出的定义是错误的。在FT-Ia中,由于被测程序产生的不正确输出恰好与断言中定义的不正确预期输出不同,从而“碰巧”组合形成了一个权限有道测试用例。换句话说,FT-Ia中的缺陷诱导输入是真实的,但断言是错误。错误缺陷诱导测试用例(FA-ia):FT-ia是测试生成中的误报。一个FT-ia用例由:(1)一个的测试输入不会导致程序运行失败的测试输入i和(2)定义了错误的预期输出的断言a组成。。通过测试(PT):PT表示驱动被测程序正确运行的测试用例。非法参数测试用例(IT):IT表示包含违反指定参数类型而无法完成测试执行的非法测试用例。2.2 程序生成器
程序生成器的主要功能是为被测程序的多个“参考版本”,每个参考版本都提供一个被测程序的替代实现。然而,作者通过在QuixBugs数据集上实验发现:当他们要求ChatGPT生成不包含Bug的参考版本时,生成的参考版本程序只有6.8%是正确的。由此可见大语言模型并不能直接胜任生成被测程序参考版本的工作。因此作者团队提出了一种改良的方案:
方案概述:正如前文提到的,ChatGPT通常对代码片段之间的细微差别不敏感。这一特点一方面阻碍了ChatGPT识别这些细微差别引入的错误,另一方面,又间接允许了ChatGPT为包含微笑错误被测程序推断意图。以这一见解为基础,作者将程序生成器的工作流程划分为两个阶段:首先,利用ChatGPT推断被测程序的意图。然后,根据推断的意图,利用ChatGPT生成被测程序的多个可编译的参考版本;这些参考版本将被用于后续的差分测试。
工作流程:图1左侧所示的的组件1展示了程序生成器的工作流程。假设一个实现了最大公约数计算功能的gcd(a,b)函数是被测程序,那么,针对这一程序,程序生成器将首先请求ChatGPT推断意图(图中所示“Prompt 1”)。在ChatGPT返回推断意图(图中所示“Response 1”)后,程序生成器将接着请求ChatGPT根据推断出的意图生成多个可编译的参考版本(图中所示“Prompt 2”),从而生成被测程序的若干参考版本(图中所示“Reference Version 1”和“Reference Version 2”)。
2.3 测试用例生成器
测试用例生成器的主要功能是利用程序生成器输出的参考版本开展差分测试,目的是找到能够使原被测程序和参考版本产生不同输出的失败测试用例。测试用例生成器的工作流程可以分为三个步骤:为被测程序生成测试输入,使用参考版本推断预期输出,执行差分测试。
步骤1:生成测试输入。测试用例生成器依托ChatGPT生成测试用例,提示ChatGPT生成多样化的测试输入(Diverse Test Input)。步骤1的工作过程可描述如下:给定一个被测程序,测试用例生成器请求ChatGPT为被测程序生成不同的测试(图1所示“Prompt 3”);相应地,ChatGPT会返回一组测试输入(图1所示“Response 3”)。值得注意的是,ChatGPT返回的测试输入的数量可能会随着对话的改变而产生不同变化。因此,在实验评估过程中,作者选择重复实验10次,以降低随机性的影响。接着,测试用例生成器依次选择测试输入并持续执行步骤2,直到找到一个缺陷诱导测试用例。如果选中的测试输入使得不同的程序参考版本产生了不一致的输出,那么这个用例将被抛弃。
步骤2:推断预期输出。在此步骤中,测试用例生成器将利用步骤1选中的测试输入推断被测程序的预期输出。步骤2的具体流程如下:首先,将步骤1筛选得到的测试输入依次传递给程序生成器生成的所有参考版本;接着,检查参考版本返回的输出的一致性。如果所有参考版本的输出都是相同的,那么测试用例生成器将这个的输出视为被测程序的预期输出。在步骤2中,测试用例生成器最多k(默认值为10)次预期输出推断。如果在k次尝试之后,差分提示仍无法找到缺陷诱导测试用例,那么就会报告“未找到缺陷诱导测试用例”。
步骤3:执行差分测试。在此步骤中,测试用例生成器检查被测程序的输出和参考版本的输出的一致性。如果不一致,那么这个测试用例就有可能揭示了被测程序的一个潜在缺陷。此时,测试用例生成器将结合步骤1生成的测试输入和步骤2生成的预期输出(作为断言)产生一个测试用例,并将这个测试用例视为一个缺陷诱导测试用例。如果输出结果一致,测试生成器将回滚到步骤1。在回滚到步骤1之前,测试用例生成器将记录当前测试输入执行到的代码行,用于计算测试执行过程中累积的分支覆盖率。当分支覆盖率达到饱和时,测试用例生成器将判定被测程序已经被充分测试,测试生成过程终止。
3 实验评估
为了评估差分提示的有效性,作者设计了四个研究问题,具体内容如下
RQ1(差分提示在QuixBugs数据集上寻找FT-IA的能力):差分提示能够有效地为QuixBugs程序找到正确缺陷诱导测试用例(FT-IA)吗?RQ2(大语言模型推断项目意图的能力):大语言模型能有效地推断项目意图吗?RQ3(差分提示生成参考版本的能力):差分提示可以有效地生成参考版本吗?RQ4(差分提示在Codeforces数据集上寻找FT-IA的能力):差分提示能够效地在最新的Codeforces数据集上找到正确的缺陷诱导测试用例吗?RQ1 差分提示在QuixBugs数据集上寻找FT-IA的能力
实验基线:作者在评估中考虑了两种基线来方法:(1)基线1:BASECHATGPT。基线1提示ChatGPT直接生成缺陷诱导测试用例,提示方法分为两步:首先,提示ChatGPT检查被测程序是否包含缺陷;在ChatGPT返回肯定响应之后,基线1进一步请求ChatGPT生成一个缺陷诱导测试用例。(2)基线2:PYNGUIN。第二个基线是PYNGUIN,是目前最先进的Python单元测试生成技术之一。
数据集:作者选择在QuixBugs数据上评估差分提示和基线方法的有效性。QuixBugs包含40组具备有缺陷和补丁的Python程序,每个程序实现了一个常用的算法。作者选择QuixBugs上所有80个程序作为评估对象。
比较方法:为了减少实验的随机性,作者重复差分提示和BASECHATGPT实验十次,同时记录在不同种类的缺陷诱导测试用例(FT)的数量。作者采用每种技术为有缺陷/正确的程序发现的正确缺陷诱导测试用例的数量与生成的测试用例总数的比率(400 = 40个程序× 10次运行)作为寻找FT的成功率。
实验结果:图3比较了差分提示和两项基线方法在寻找缺陷诱导测试用例方面的有效性。FT-IA列中的“×”标记表示三种技术在所有40个程序中发现的FT-IA的平均值。其中,平均值的计算方法是将40个程序找到的FT-IA总数除以40。总的来看,差分提示成功找到FT-IA的概率为75.0%,是BASECHATGPT的成功率的2.6倍(28.8%)、PYNGUIN的10.0倍(7.5%)。在准确性方面。
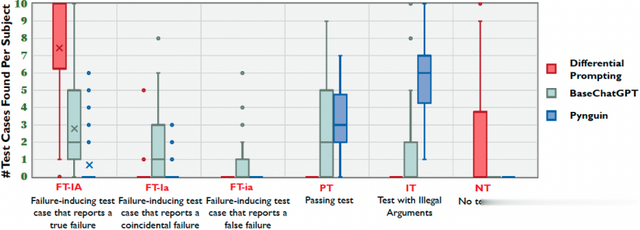
图2 差分提示和基线方法在QuixBugs数据机上程序发掘缺陷诱发测试用例的有效性统计
RQ2 大语言模型为错误程序推断正确程序意图的能力
实验设置:为了探究ChatGPT是否能够正确推断错误程序的意图,作者开展了手动分析。具体地,作者以QuixBugs的每个程序的注释中记录的问题描述作为基准评估ChatGPT推断所有400程序意图的正确性。作者请两位具有丰富软件开发经验的作者分别检查每个推断的意图是否与QuixBugs提供的文档化描述一致。结果显示,作者1认为有82.3%的文档准确描述了待测程序的意图,而作者2则认为“几乎程序的意图都和文档描述一致”。
实验结果:图3显示ChatGPT能够为大多数错误程序推断正确的意图。具体来说,差分提示能够正确推断40个中30个被测程序的10个错误版本的程序意图,ChatGPT在为错误程序推断意图方面的成功率达到了91.0%(364/400)。这个结果支撑了本文的关键见解,即:尽管存在错误,ChatGPT仍能够正确推断程序的意图。
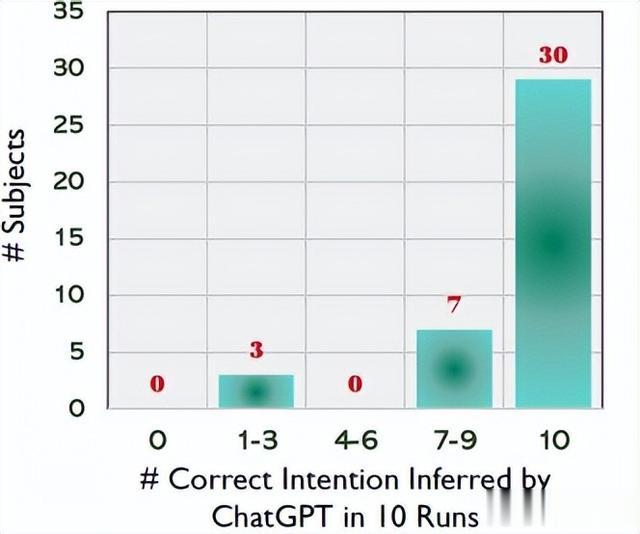
图3 ChatGPT在推断程序意图方面的有效性
RQ3 差分提示生成待测程序参考版本的能力
实验设置:为了评估差分提示是否能够有效生成良好的待测程序的参考版本,作者记录并研究了差分提示生成的良好参考版本的数量。具体地,如果参考版本不存在与被测程序相同的错误,那么作者就认为参考版本是好的。在本RQ中的基线方法(Strawman Approach)是直接提示ChatGPT生成参考版本,分为两个步骤:首先询问ChatGPT 被测程序是否有错误;在得到肯定的响应后,进一步要求ChatGPT生成两个修复了被测程序错误的实现(与每次执行时,差分提示也生成两个引用版本相同)。按照RQ1中的实验设置,作者重复基线方法10次,然后计算差分提示和基线方法生成良好参考版本的成功率,计算方法是用某个方法生成的全部良好参考版本的数量除以800。
实验结果:图4比较了差分提示和基线在生成参考版本方面的有效性。图中的×字标记表示这两种技术对所有40个程序对象产生的良好参考版本的平均数量。总体而言,差分提示的成功率为74.6%,比基线(6.8%)高出11.0倍。此外,差分提示为40个中20个被测程序生成20个良好的参考版本,而基线仅为两个被试生成20个良好的参考版本。这是因为差分提示利用被测程序的意图(而非它的实现)提示ChatGPT生成参考版本,从而绕过了ChatGPT在辨别程序片段细微差别方面的弱点。相反,基线方法则从被测程序的实现生成参考版本,从而限制了生成的有效性。

图4 差分提示和基线方法在生成良好参考版本方面的有效性
RQ4 差分提示在Codeforces数据集上寻找FT-IA的能力
实验设置:为了防止数据泄露影响实验的评估结果,作者在ChatGPT版本发布日期之后的Codeforces数据集上组织了又一组实验。具体地,作者从编程初学者竞赛(名为Codeforces Round 835,于2022年11月21日举行)中选择程序作为实验对象。Codeforces Round 835是ChatGPT推出日期(即2022年11月30日)之后的编程竞赛,包含七个不同难度的编程问题。对于每个编程问题,作者根据两重标准选择一个有缺陷的版本和一个正确的版本。标准1:程序的正确版本必须是错误版本的修复版本;标准2:两个程序版本都必须用Python实现。在本RQ中,作者采用RQ1中提到的两个基线,即BASECHATGPT和PYNGUIN。作者将差分提示和基线在每个程序上重复10次,记录不同方法生成的不同种类的缺陷诱导测试用例的个数,并采用RQ1中定义的成功率该RQ4的评估指标。
实验结果:表I显示,对于Codeforces的有Bug的程序,差分提示的成功率(41.0%)比最佳基线(7.0%)高出5.9倍。此外,对于有Bug的和正确的程序,差分提示仅在一个主题(Challenging Valleys)返回了不正确的缺陷诱导测试用例,而BASECHATGPT则在所有七个主题上返回不正确的缺陷诱导测试用例;而PYNGUIN在任何执行中都找不到正确的缺陷诱导测试用例。表I中展示了Codeforces每个程序配备的标签(字母A到G),表示程序的复杂程度。其中,标有A的程序是最简单的,标有G的程序是最难的。不难看出,差分提示在A类程序上的性能最好(能够找到10个FT-IA),随着难度的增加,其性能逐渐降低。
表1 差分提示和基线方法在Codeforces数据集上表现出的寻找缺陷诱发测试用例方面的有效性

转述:钱瑞祥
