就在最近,谷歌DeepMind围绕DeepSeek模型成果及其低成本所发表的看法再一次受到关注与热议。2月9日,谷歌DeepMind首席执行官Demis Hassabis在一场活动上表示,DeepSeek的人工智能模型 「可能是我见过的来自中国的最好作品」。该人工智能模型表明,DeepSeek可以完成 「极其出色的工程」,它 「在地缘政治层面上改变了一切」。
不过,他认为,从技术角度来看,DeepSeek「并未展示任何新的科学进步」。Hassabis称,「尽管炒作得很厉害,但实际上并没有什么新的科学进展。它使用的是已知的技术。实际上,很多技术都是我们在谷歌和DeepMind发明的。谷歌本周向所有人发布的公司Gemini 2.0 Flash模型比DeepSeek的模型更有效」。
此外,这位高管还驳斥了DeepSeek的出现颠覆了人工智能开发经济学的观点:「我们没有看到任何新的灵丹妙药技术,DeepSeek在效率曲线上并不是一个例外。」在这方面,Anthropic创始人Dario Amodei先前也称,「DeepSeek-V3没有从根本上改变大模型的经济模式,只是符合持续降低成本曲线上的一个预期节点。不同之处在于,率先实现的是一家中国公司。」
557.6万美元训练成本的「误会」
谈到DeepSeek所发布模型的训练成本数据,Hassabis强调,DeepSeek「似乎只报告了最后一轮训练的成本,而这只是总成本的一小部分」。
与Hassabis观点相似,独立研究机构SemiAnalysis也称,目前被宣传的DeepSeek成本价格「明显有误解」,仅计入了物料清单中的特定部分,并不能反映其全周期内的总体投入。具体来讲,「预训练投入远远不是DeepSeek花在模型身上的总体金额。通过估算,该公司单硬件支出就远高于5亿美元。而新架构的设计与创新、以及后续模型的实际开发都需要耗费大量资金,包括测试新想法、探索新架构的可行性和进行消融实验等。」
SemiAnalysis得出的结论是:DeepSeek论文中提到的557.6万美元成本仅仅是预训练阶段的GPU直接成本,只占模型总实现成本中的一小部分,此外还有硬件本身的研发以及总体拥有成本(TCO)等其他投入。SemiAnalysis还举了Claude的例子作为参考:Claude 3.5 Sonnet的训练成本为数千万美元,但如果Anthropic真的只需要这样的投入就能完成模型构建,那他们就不会急于从谷歌和亚马逊处数十筹集亿乃至数百亿美元。这多出来的部分,还要被用于进行探索性实验、新架构设计、数据收集与清洗、支付人员工资等。
但其实即使用DeepSeek 557.6万美元的训练成本与Claude更广泛的成本做对比,也并没有太大意义。对于557.6万美元的训练成本,DeepSeek在论文中已经有明确的解释:
我们再次强调下DeepSeek-V3的训练成本,总结在表1中。这是我们通过对算法、框架和硬件的优化协同设计实现的。在预训练阶段,在每万亿个token上训练DeepSeek-V3只需要180000个H800 GPU小时,即在我们拥有2048个H800 GPU的集群上需要3.7天。因此,我们的预训练阶段是在不到两个月的时间内完成的,成本为2664,000个GPU小时。再加上119000个GPU小时用于扩展上下文长度和5000个GPU小时的后训练,DeepSeek-V3的总训练成本仅为278.8万个GPU小时。假设H800 GPU的租赁价格为2美元/每GPU小时,那我们的总训练成本仅为557.6万美元。请注意,上述成本仅包括DeepSeek-V3的官方训练,不包括与先前研究、架构、算法、数据和消融实验相关的成本。

关于SemiAnalysis提到的结构、算法、消融实验等成本问题,DeepSeek在论文中也已经说明。不过,对于Hassabis「仅最后一轮训练成本」的猜测,论文中并未提及。

SemiAnalysis还对比了OpenAI成本下降幅度来证明成本下降是「自然」的。「目前运行在笔记本电脑上的小模型已经具备与GPT-3相当的性能,而当初后者可是需要一台超级计算机进行训练、再由多张GPU支撑推理;就GPT-3级别的推理成本而言,其当前成本已经下降至当初的1/1200;将目光投向GPT-4,其成本也出现了类似的下降幅度,只是这条曲线尚处于早期阶段。」
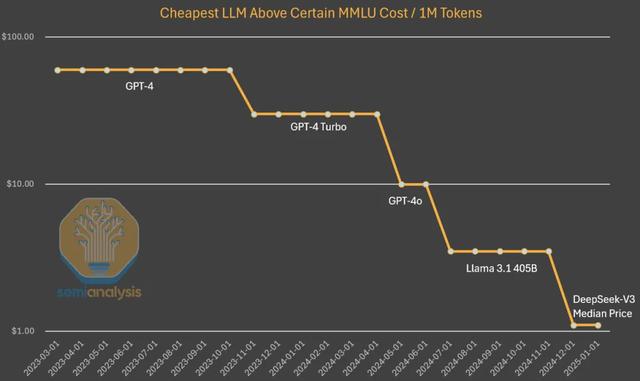
因此,在SemiAnalysis看来,「算法的改进使我们能够以更少的算力支持训练与推理,最终实现能力相同的模型,而且这样的情况仍在不断上演。(DeepSeek)之所以引发了全世界关注,是因为V3来自中国实验室,而小模型越来越强本身并不算什么新闻。」
据SemiAnalysis估计,算法的进步速度为每年4倍,就是说每过一年,实现相同功能所需要的算力资源就降低至四分之一。不过同时,SemiAnalysis也强调,DeepSeek的独特之处正在于他们率先实现了这种强大的成本与能力组合。而且虽然DeepSeek目前的成本水平已经相当低廉,但到今年年底,其服务成本可能会进一步降低至五分之一。
当前成果背后的更多投入
我们都知道,DeepSeek背后是「财大气粗」的对冲基金幻方量化,管理规模超600亿元。据了解,幻方量化也是在交易算法中引入AI技术的早期先驱之一。他们很早就意识到AI在金融业以外领域的巨大潜力与扩展空间,因此一直在持续增加GPU投入,在通过具有数千张GPU的集群运行模型实验之后,幻方量化在出口限制尚未落地的2021年决定一举将A100 GPU增加至1万张。
随着项目推进,他们决定在2023年5月拆分成立「DeepSeek」,旨在更专注于追求并塑造AI能力。幻方量化之所以选择自筹资金,是因为当时外部投资者对于AI兴趣不大,认为其缺乏有利可图的商业模式。如今,幻方量化与DeepSeek似乎始终在大量共享资源,包括算力及人力等方面。
GPU储备成本
DeepSeek现已发展成为一个紧密协同的严肃项目,绝非许多人声称的「附带探索」。根据独立研究机构SemiAnalysis的估算,即使考虑到出口管制,其GPU总投资额超过了5亿美元(合约36.5亿元人民币)。SemiAnalysis在分析报告中称,「预计DeepSeek共掌握约5万张Hopper GPU,而非部分评论人士所言的5万张H100。我们认为,DeepSeek拥有约1万张H800和约1万张H100。此外,他们还大量订购H20 GPU。」

目前,英伟达按照法规要求推出了多个H100版本(分为H800和H20),其中H20是专供中国模型服务商的型号。具体来讲,H800的算力水平与H100相同,但网络带宽较低。过去9个月内,英伟达共生产了超百万张专供中国的GPU H20。SemiAnalysis指出,这批GPU由幻方量化与DeepSeek共同使用,且分散在不同地理区域,主要用于交易、推理、训练和研究等用途。
通过分析认定,SemiAnalysis判断DeepSeek的总服务器资本支出约为16亿美元,这批集群的运营成本亦高达9.44亿美元。需要注意的是,设备分散化部署将带来资源集中挑战,这类情况的各AI实验室和超大规模基础设施运营商可能都必须采购更多GPU以支撑各地的研究和训练任务。现在只有X.AI的情况比较特殊,其全部GPU均集中在同一处设施之内。
人力成本
DeepSeek专门从中国国内招募人才,不考虑以往资历,重点关注能力和好奇心。据了解,DeepSeek定期在北大和浙江大学等顶尖高校举办校招活动,公司员工也多数毕业于这些大学。DeepSeek提供的工作岗位往往并非提前设定好,而是具有一定灵活性,且在招聘广告中称员工可随意使用多达1万张GPU。并且,DeepSeek开出的年薪不菲。有消息称,DeepSeek为顶尖申请者提供超过130万美元的年薪,远远高于其他中国科技巨头及月之暗面等竞争对手。
据公开资料显示,DeepSeek目前的员工数量大约为150人左右,且仍处于快速扩张阶段。在某招聘平台可以看到,截止今日(2月11日),DeepSeek放出了38个招聘职位,招聘的岗位涵盖客户端研发工程师、核心系统研发工程师、AGI数据百晓生、深度学习研发工程师、全栈开发工程师、自然语言处理算法、高级移动端开发工程师等多种不同的岗位,其中大部分岗位月薪3万元起步,最高至9万元,且都是「14 薪」,算下来年薪最高能达到百万级别。就连实习生,都开出了500-1000的日薪。其人力成本可见一斑。
但从DeepSeek的工商信息来看,杭州深度求索人工智能基础技术研究有限公司在缴社保员工仅4人,北京深度求索人工智能基础技术研究有限公司参保0人。也就是说,现在DeepSeek团队中的大部分人很可能都借调于母公司幻方量化。
此外,近日DeepSeek在北京的办公地址也被曝出位于北京北四环边上,这栋楼里还有AMD、百度风投、苹果智元公司、红帽软件、超威半导体等,租金应当也不菲。
参考链接:
https://semianalysis.com/2025/01/31/deepseek-debates/#deepseek%e2%80%99s-cost-and-performance
https://www.cnbc.com/2025/02/09/deepseeks-ai-model-the-best-work-out-of-china-google-deepmind-ceo.html
--AI前线

平凡
最不要脸=美国人