
在一个清晨,伴随着咖啡的香气,办公室里几位程序员正兴致勃勃地讨论刚刚发布的一个新测试。
这个测试名为ENIGMAEVAL,是最新的 AI 基准测试,很多人都对它寄予厚望。
某位程序员突然说道:“你们知道吗?
这次的ENIGMAEVAL测试有235个谜题,连最先进的 AI 模型都测过,可它们竟然完全答不出来!
”
这句话顿时引发了热烈的讨论,大家纷纷开始猜测这究竟是什么意思。
为什么这些被誉为当今最强大的 AI 模型,竟然在面对这些谜题时束手无策呢?

ENIGMAEVAL到底是什么?
简而言之,它是一个非常复杂的基准测试。
它由 Scale AI、Center for AI Safety 以及 MIT 的研究者联合推出,针对高难度问题的基准。
这个基准测试的设计非常巧妙,它包括了从解谜寻宝(Puzzle Hunts)中抽取的文本和图像难题。
Puzzle Hunts 是一种团队解谜竞赛,它不仅仅是游戏,而是一种非常严肃的考验。
参与者需要运用逻辑推理、创造性思维、以及多学科知识来解决问题。

可以想象,这对 AI 模型来说是一项巨大的挑战。
Puzzle Hunts:解谜竞赛的挑战为什么选Puzzle Hunts作为测试 AI 的内容?
原因很简单:Puzzle Hunts 涉及的领域广泛,从数学、密码学、图像分析、程序编写到文化常识,无所不包。
它们考验的不仅仅是知识储备,更是逻辑推理和创造性的运用。
在现实中,人类团队需要花费数小时甚至数天来解决这些谜题。
而 ENIGMAEVAL 把这些难题分成两种格式:一是原始 PDF 的图像版,一是结构化的文本和图像表示。

这两种格式针对不同的推理过程,全面考察 AI 的综合能力。
对于这些AI模型来说,能否正确理解和解决这些谜题,是对它们理解和推理能力的真正考验。
测试结果揭示AI的弱点当测试结果出来时,不少人都有些失望。
在普通谜题部分,哪怕是表现最好的模型,其准确率也只有7%。
而在困难谜题部分,这些先进的 AI 模型竟然完全失败,准确率为0%。
这让我们看到,当前的 AI 包括最先进的模型在面对真正复杂的谜题时,仍然表现不佳。
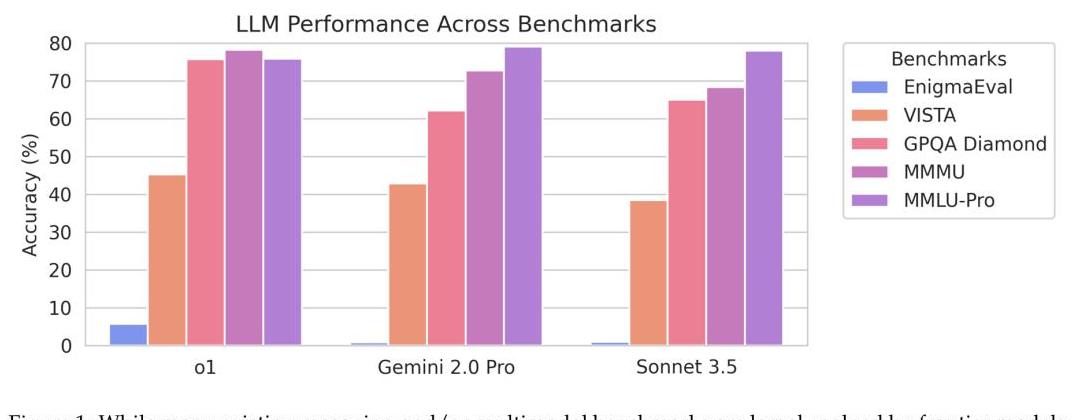
这也暴露了 AI 在深度理解和逻辑推理上的局限。
比如,在从转录的谜题到原始PDF版谜题时,AI的表现差别很大,说明它们在解析复杂文档和处理各种格式方面还存在很大问题。
其实,这些结果并不是AI模型本身的失败,反而是我们对于AI有了更清晰的理解。
这些失败的案例帮助研究者识别出了当前技术的局限,从而推动下一个阶段的改进。
从文本到图像:模式转换的难题还有一个有趣的发现:当转录的谜题变成原始 PDF 图像版后,AI 的性能会急剧下降。
这说明,当前的 AI 对于图像和文本的综合处理,还有很大的提升空间。

虽然很多人假设原始谜题格式会为AI增加额外的难度,但实际上,模型在处理复杂文档时已经有了一定优化,只是还不够好。
这些种种迹象表明,我们离真正智能的 AI 还有很长的一段路要走。
通过这样的测试,我们可以更加直观地看到AI的进步和短板,从而为未来的发展指明方向。
AI前路漫漫,人类充满希望这次的测试不仅仅是一次失败,也是一种鼓励。
它告诉我们,AI的前路依然漫长,但这也意味着更多的机会和希望。
就像许多技术革新一样,AI的发展也是一个不断试验和改进的过程。

每次的测试失败,都是推动技术进步的一次契机。
面对这些挑战,不仅是AI模型需要继续进步,我们也需要不断寻找新的方法和角度,去突破当前的技术瓶颈。
或许某天,当我们再次坐在办公室的咖啡桌前,谈论着AI的新挑战时,会发现这些曾经难倒AI的谜题,已经成为激励它不断进化的动力。
而我们,也将在这条前行的道路上,看到更多的创新和可能。
在那个未来的早晨,当AI真正能够破解这些难题时,我们或许会怀念今天的这份激动和期待。
每一次的失败,都是成功必须跨越的一步。
让我们拭目以待,见证AI的下一次飞跃。

