
作者 | 程茜
编辑 | 心缘
智东西3月1日消息,DeepSeek的开源周竟然还有彩蛋!开源第六天,DeepSeek不仅放出了DeepSeek-V3/R1推理系统技术秘籍,还公开了每日成本和理论收入!
DeepSeek统计了2月27日24点到2月28日24点,计算出其每日总成本为87072美元(折合人民币约63万元)。如果所有Token都以DeepSeek-R1的价格计费,每日总收入将为562027美元(折合人民币约409万元),成本利润率达到545%。也就是说,理论上DeepSeek每日净赚474955美元(折合人民币约346万元)。
但实际情况是,DeepSeek的收入大幅下降。由于DeepSeek-V3定价低于R1;网页端和应用程序免费,只有部分服务有收入;非高峰时段还有夜间折扣,使得其实际收入并没有这么高。
此外,DeepSeek还公开了DeepSeek-V3/R1推理系统概述:为了达到推理更高的吞吐量和更低的延迟,研究人员采用了跨节点的专家咨询(EP),并且利用EP增大batch size、将通信延迟隐藏在计算之后、执行负载均衡,应对EP的系统复杂性挑战。
发布一小时,GitHub Star数已超过5600。

评论区的网友频频cue OpenAI,直呼“被抢劫”了!
还有网友以OpenAI的定价帮DeepSeek算账:
GitHub地址:
https://github.com/deepseek-ai/open-infra-index/blob/main/202502OpenSourceWeek/day_6_one_more_thing_deepseekV3R1_inference_system_overview.md
一、每日总成本为87072美元,利润率理论上最高545%DeepSeek V3和R1的所有服务均使用H800 GPU,使用和训练一致的精度,即矩阵计算和dispatch传输采用和训练一致的FP8格式,core-attention计算和combine传输采用和训练一致的BF16,最大程度保证了服务效果。
此外,由于白天的高服务负载和晚上的低负载,DeepSeek在白天高峰时段跨所有节点部署推理服务。在低负载的夜间时段减少了推理节点,并将资源分配给研究和训练。在过去的24小时内(2月27日24点到2月28日24点),V3和R1推理服务的合并峰值节点占用率达到278,平均占用率为226.75个节点(每个节点包含8个H800 GPU)。假设一个H800 GPU的租赁成本为每小时2美元,则每日总成本为87072美元。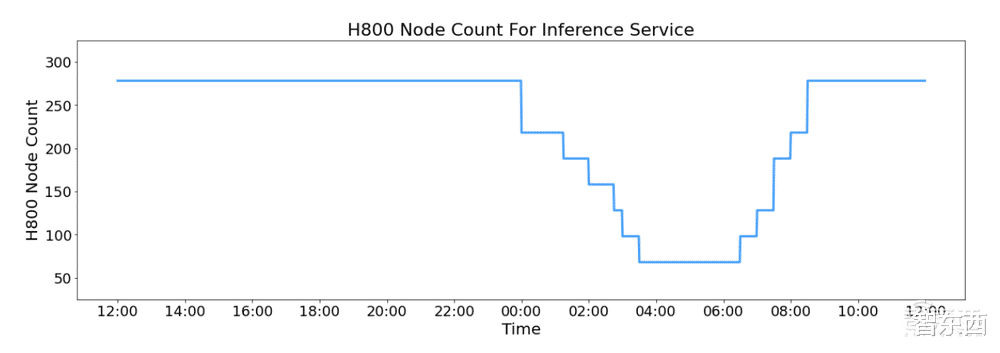
▲推理服务的H800节点计数
在24小时统计周期内(2月27日24点到2月28日24点),V3和R1:
总输入Token 608B,其中342B Token(56.3%)命中KVCache硬盘缓存。
总输出Token 168B,平均输出速度为每秒20-22 tps,每个输出Token的平均kvcache长度为4989个Token。
每个H800节点在prefill期间提供约73.7k token/s输入(包括缓存命中)的平均吞吐量,或在解码期间提供约14.8k token/s输出。
以上统计数据包括所有来自web、APP、API的用户请求。如果所有Token都以DeepSeek-R1的价格计费,每日总收入将为562027美元,成本利润率为545%。*R1的定价:0.14美元输入Token(缓存命中),0.55美元输入令牌(缓存未命中),2.19美元输出令牌。然而,DeepSeek的实际收入并没有这么多,其原因是DeepSeek-V3的定价明显低于R1;网页端和应用程序免费,所有只有一部分服务被货币化;夜间折扣在非高峰时段自动适用。
▲成本和理论收入
二、EP增加系统复杂性,三大策略应对DeepSeek的解决方案采用了跨节点的专家并行(EP)。
首先,EP显著扩展了批处理大小,增强了GPU矩阵计算效率并提高了吞吐量;其次,EP将专家分布在不同GPU上,每个GPU只处理专家的一小部分(减少内存访问需求),从而降低延迟。
然而,EP在两个方面增加了系统复杂性:EP引入跨节点的传输,为了优化吞吐,需要设计合适的计算流程使得传输和计算可以同步进行;EP涉及多个节点,因此天然需要Data Parallelism(DP),不同的DP之间需要进行负载均衡。
DeepSeek通过三种方式应对了这些挑战:
利用EP增大batch size、将通信延迟隐藏在计算之后、执行负载均衡。
1、大规模跨节点专家并行(EP)
由于DeepSeek-V3/R1的专家数量众多,并且每层256个专家中仅激活其中8个。模型的高度稀疏性决定了其必须采用很大的overall batch size,才能给每个专家提供足够的expert batch size,从而实现更大的吞吐、更低的延时。需要大规模跨节点专家并行(Expert Parallelism/EP)。
DeepSeek采用多机多卡间的专家并行策略来达到以下目的:
Prefill:路由专家EP32、MLA和共享专家DP32,一个部署单元是4节点,32个冗余路由专家,每张卡9个路由专家和1个共享专家
Decode:路由专家EP144、MLA和共享专家DP144,一个部署单元是18节点,32个冗余路由专家,每张卡2个路由专家和1个共享专家
2、计算-通信重叠多机多卡的专家并行会引入比较大的通信开销,所以使用了双batch重叠来掩盖通信开销,提高整体吞吐。对于prefill阶段,两个batch的计算和通信交错进行,一个batch在进行计算的时候可以去掩盖另一个batch的通信开销。
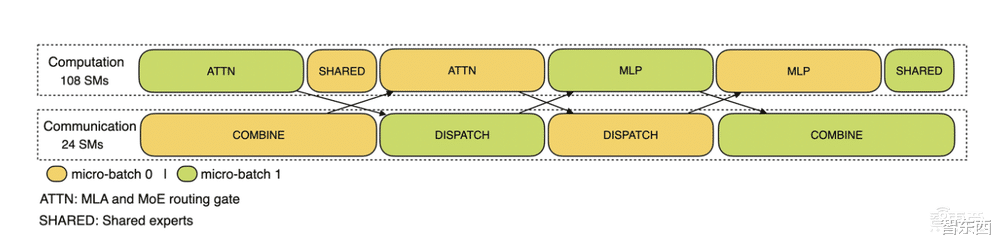
▲预充阶段的通信-计算重叠
对于decode阶段,不同阶段的执行时间有所差别,所以DeepSeek把attention部分拆成了两个stage,共计5个stage的流水线来实现计算和通信的重叠。

▲解码阶段的通信-计算重叠
3、实现最佳负载均衡
由于采用了很大规模的并行(包括数据并行和专家并行),如果某个GPU的计算或通信负载过重,将成为性能瓶颈,拖慢整个系统;同时其他GPU因为等待而空转,造成整体利用率下降。因此我们需要尽可能地为每个 GPU 分配均衡的计算负载、通信负载。
Prefill Load Balancer的核心问题:不同数据并行(DP)实例上的请求个数、长度不同,导致core-attention计算量、dispatch发送量也不同。
其优化目标是,各GPU的计算量尽量相同(core-attention计算负载均衡)、输入的token数量也尽量相同(dispatch发送量负载均衡),避免部分GPU处理时间过长。
Decode Load Balancer的关键问题是,不同数据并行(DP)实例上的请求数量、长度不同,导致core-attention计算量(与KVCache占用量相关)、dispatch发送量不同。
其优化目标是,各GPU的KVCache占用量尽量相同(core-attention计算负载均衡)、请求数量尽量相同(dispatch发送量负载均衡)。
专家并行负载均衡器的核心问题:对于给定MoE模型,存在一些天然的高负载专家(expert),导致不同GPU的专家计算负载不均衡。
其优化目标是,每个GPU上的专家计算量均衡(即最小化所有GPU的dispatch接收量的最大值)。

▲DeepSeek在线推理系统图


coponada
open ai的API价格快有deepseek的两百倍了吧,这样看来卷白菜价是有用的,因为不卷到白菜价,这天价也都被openai这种公司赚走了,卷到白菜价,普通人至少能得利
暮尘
开源,你倒是公开标准数据啊。标注数据才是AI的核心的核心。
深蓝,我是浅蓝
其实永远叫不醒装睡的人,当年我老师也苦口婆心的把高考知识都告诉我们了,结果也只有我同桌听懂了
9527
我朋友说下载一个来玩双色球
♂傻小子☆☆☆ 回复 03-02 08:54
没用的。
梦一回╭♀丶 回复 03-02 14:47
股票还能分析一下,双色球就算了吧
龍鳯呈祥
梁文峰说:DS主要是服务大众,赚够用算了。
松冈mayu
关键是。。。。目前600亿美元做到和GPT同等级。。。我先不超越你,我先看看[笑着哭][笑着哭][笑着哭]
黯淡之光
咱们把AI牌DeepSeek 拿出来说明背后有更强大的潜能在手里没放出来,所以咱们把牌打出来说明还隐藏更强的牌在背后。时间会告诉全人类。
一粒沙
梁文峰将是中国的马斯克,走着瞧[红脸笑]
天外侠影 回复 03-02 15:18
梁忽悠也就一低配版许皮带!只顾吹,根本没想维护下它那屌丝系统!
小女孩
这个……工程上的开发量绝对没有它开源的那么点儿,很多核心的没拿出来。
一芦江湖
怎么样可以买到这公司股票。
2-20个字符支持中英文数字
一天63万元,基本是电费开销,太浪费电能了
猪先森
已经充值100,希望五月份发布R2版本,继续吊打openai
樱兰
请问大佬 不明白呀🤔他不是开源免订阅吗 他靠啥收入的呀?
abracadabra
你敢信我一个纯编程小白现在能利用DeepSeek帮我用python建模分析数据了[捂脸哭]
巴拉巴拉超级棒
open ai:你这样搞,显得我是个小丑🤡让我怎么跟投资人交代,有什么脸再拉投资[哭哭]
邈邈
有人想离职把技术拿走,那我干脆就直接发布出来,我不好,大家都别想好
结婚
初期就差不多年赚百亿了!中国又要诞生一家万亿级别的科技公司![呲牙笑]
南蛮阿奴
deepseek这么做到底为什么?
你橘
这是要把Chatgpt祖坟都刨了啊 [捂脸哭] [捂脸哭] [捂脸哭] [捂脸哭]
家有挑食怪
OpenAI:“钱和我,哪个对你重要”deepseek:“没有你,对我很重要”--让AI再飞一会[爱心][爱心]
蛋卷来一口
核心价值己到极限,随阿里等巨头入场会很快失去竞争力,终极的对决仍是算力
贝多芬故居
前几天有润[doge]说deepseek每月亏4亿
2-20个字符支持中英文数字 回复 03-02 18:15
是接入ds的公司亏,他自己的怎可能亏