在当今IT应用领域,大模型无疑是最受瞩目也是最能带来生产力提升的明星。然而,大多数开发者出于gpu太过于昂贵的原因而一般在使用大模型时依赖于云端服务,这不仅可能涉及隐私及安全合规问题,还经常因受限于token的费用和调用频率的限制而苦恼。本文我将带大家探索在本地电脑部署调试llm大模型并完成一个基本的调用。
总体上来说本文所演示的方案是通过 Ollama搭建属于自己的本地 LLM服务,虽然模型参数不是很大,但和gpt openapi,以及meta 的llm的开发调试原理完全一致,我们完全可以先用本地llm调试没问题之后,再尝试切换连接llm云服务,为自己节省资金和提升开发效率

Ollama-本地LLM利器
1.安装 Ollama:开启本地 LLM 之旅安装 Ollama 简单易行,无论你是 Windows 用户、Mac 用户还是 Linux 爱好者,都能轻松上手。本文以 Windows 系统为例,只需前往 Ollama 的官方网站,下载对应的安装包,然后按照提示一步步完成安装即可。安装完成后,打开命令行工具,输入 ollama 命令,如果看到相关的版本信息和帮助提示,那就说明你已经成功安装了 Ollama

Ollama官网下载

安装Ollama
2.运行指定的版本的LLM大模型Ollama 本身并不自带模型,但是它为我们提供了丰富的模型获取渠道。我们可以通过 Ollama 的命令行界面轻松下载各种知名的大模型,我们要做的只是在命令行中输入 ollama pull [模型名称],Ollama 就会迅速从模型仓库中下载并安装指定的模型到本地。本文演示的方案是基于Google DeepMind团队开发的gemma:2b模型,当然你可以获取meta旗下的llama某个版本的模型。
注:如果本地没有检测到模型文件,Ollama会自动进行pull操作来拉取llm大模型数据和文件。

Ollama拉取大模型
3.安装python的ollama库Ollama python库是由 Ollama 团队开发的一个强大的工具库,它能够让开发者仅用几行代码,便将 Python 项目与 Ollama 平台无缝集成,从而在应用程序中充分利用 Ollama 的功能,轻松实现本地大语言模型(LLM)的调用和应用开发.
该库具备以下特点:模型交互功能强大(轻松实现聊天等应用),支持多种模型(Llama 2、Code Llama, gemma,quen等),流式响应处理,模型管理便捷,错误处理机制完善,支持同步和异步客户端

安装ollama库
运行一个简单的本地llm模型的调用实例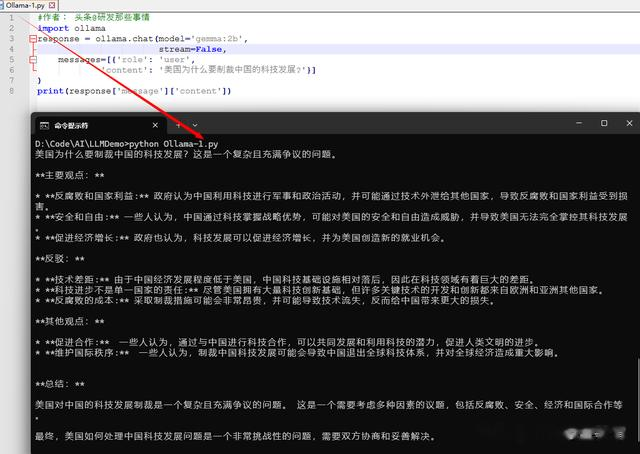
本地llm大模型调试
注:从此,你无需担心token问题,墙的问题,gpu买不起的问题......,尽情的去探索AI应用的无限可能吧
写在最后:你的点赞和关注是对我最大的鼓励,后续将分阶段慢慢实现基于llm大模型+langchain开发的Google 搜索优化方面的工具
