为什么微服务容器化的运维又成了新问题?
在大部分业务团队中,进行容器化之前,服务通常部署于物理机或者虚拟机上,而运维一般会有一套既定的运维平台来发布服务。以微博的运维平台 JPool 为例,当有服务要发布时,JPool 会依据服务所属的集群(通常一个业务线对应一个集群)以及运行在哪个服务池(一般一个业务线有多个服务池),确定对应的物理机或者虚拟机 IP,接着通过 Puppet 等工具将最新的应用程序代码分批逐次地发布到这些物理机或者虚拟机上,随后重新启动服务,如此便完成了一个服务的发布流程。
然而,现在情况发生了变化。业务容器化后,运维所面对的不再是一台台实实在在的物理机或者虚拟机,而是一个个 Docker 容器,它们可能没有固定的 IP。在这种情况下,要进行服务发布该如何操作呢?此时就需要一个面向容器的新型运维平台,它能够在现有的物理机或者虚拟机上创建容器,并且可以像运维物理机或者虚拟机一样,对容器的生命周期进行管理,通常我们将其称为 “容器运维平台”。
根据我的经验,一个容器运维平台通常包含以下几个组成部分:镜像仓库、资源调度、容器调度和服务编排。
镜像仓库Docker 容器的运行依赖于 Docker 镜像,所以要发布服务,首先得把镜像发布到各个机器上。此时就产生了问题,这个镜像该放在哪里呢?又如何将镜像发布到各个机器上去呢?在这种情况下,就得依靠镜像仓库了。镜像仓库的概念与 Git 代码仓库类似,即有一个集中存储的地方,将镜像存储于此。在服务发布时,各个服务器都访问这个集中存储来拉取镜像,然后启动容器。Docker 官方提供了一个镜像仓库地址:https://hub.docker.com/,对于测试应用或者小规模的业务可以直接使用。但对于大部分业务团队而言,出于安全和访问速度的考虑,都会搭建一套私有的镜像仓库。
那么,具体该如何搭建一套私有的镜像仓库呢?下面我就结合微博的实践,和你聊聊这里面的门道。
权限控制镜像仓库首先面临的是权限控制问题,即确定哪些用户可以拉取镜像,哪些用户可以修改镜像。
一般来说,镜像仓库设有两层权限控制。其一,必须登录才可以访问,这是最外层的控制,规定了哪些人能够访问镜像仓库。其二,对镜像按照项目的方式进行划分,每个项目拥有自己的镜像仓库目录,并为每个项目设置项目管理员、开发者以及客人三个角色。只有项目管理员和开发者拥有自己镜像仓库目录下镜像的修改权限,客人只拥有访问权限,且项目管理员可以设置哪些人是开发者。
个权限控制与大厦办公楼的管理类似。要进入大厦里的一个办公室,首先必须具备进入大厦的权限,这是在大厦里所有办公的人都有的。然后还得具备大厦里办公室所在楼层的门禁,才能进入办公室。不同楼层的人权限不同,只能进入自己楼层的办公室。如果某个办公室有新来的员工,首先要给他分配大厦的进入权限,然后由这个办公室的管理员给他分配办公室的权限。这样讲解权限控制,是不是更好理解一些呢?
镜像同步在实际的生产环境中,常常需要把镜像同时发布到几十台甚至上百台集群节点上。单个镜像仓库实例往往由于带宽原因限制,无法同时满足大量节点的下载需求。此时,就需要配置多个镜像仓库实例来进行负载均衡,同时也会产生镜像在多个镜像仓库实例之间同步的问题。显然,通过手工维护十分繁琐,那有什么好的办法呢?一般来说,有两种方案。一种是一主多从、主从复制的方案,比如开源镜像仓库 Harbor 就采用了这种方案。另一种是 P2P 的方案,比如阿里的容器镜像分发系统蜻蜓采用了 P2P 方案。微博的镜像仓库是基于 Harbor 搭建的,所以这里我就以 Harbor 为例,介绍镜像同步机制。Harbor 所采取的主从复制的方案是,将镜像传到一个主镜像仓库实例上,然后其他从镜像仓库实例都从主镜像仓库实例同步。它的实现就像下图所描述的一样。

图片
除此之外,Harbor 还支持层次型的发布方式,如果集群部署在多个 IDC,可以先从一个主 IDC 的镜像仓库同步到其他从 IDC 的镜像仓库,再从各个从 IDC 同步给下面的分 IDC,它的实现就像下图所描述的一样。

图片
高可用性既然 Docker 镜像是 Docker 容器运行的基础,那么镜像仓库的高可用性便不言而喻。一般来说,高可用性设计无非是将服务部署在多个 IDC,这样即便有 IDC 出现问题,也可以把服务迁移到其他正常的 IDC 中。同样,对于镜像仓库的搭建,也可以采用多 IDC 部署,此时需要做到不同 IDC 之间的镜像同步。以微博的镜像仓库为例,就如下图所示,镜像仓库会部署在永丰、土城两个内网 IDC 内。两个 IDC 内的镜像同步采用 Harbor 的双主复制策略,互相复制镜像。这样一来,即使有一个 IDC 出现问题,另外一个 IDC 仍然能够提供服务,并且不会丢失数据。
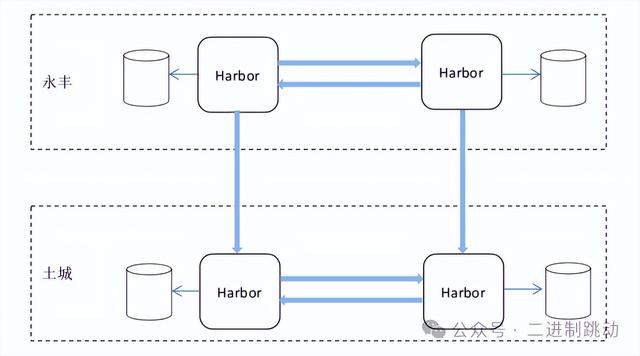
图片
资源调度解决了 Docker 镜像存储和访问的问题后,新问题又随之而来了,Docker 镜像要分发到哪些机器上去?这些机器是从哪里来的?这其实涉及的是资源调度的问题。
物理机集群大部分中小团队通常拥有自己的物理机集群,且大多按照集群 - 服务池 - 服务器的模式进行运维。物理机集群面临的问题主要是服务器配置不统一。尤其对于计算节点而言,普遍存在这样一种情况:几年前采购的机器配置可能是 12 核 16G 内存,而近些年采购的机器至少是 32 核 32G 内存的配置。对于这两种机器往往需要区别对待,比如旧机器用于跑一些非核心、占用资源量不大的业务,新采购的机器则用于跑一些核心且服务调用量高的业务。虚拟机集群不少业务团队在使用物理机集群后,发现物理机集群存在使用率不高、业务迁移不灵活的问题,于是纷纷转向虚拟化方向,构建自己的私有云。比如以 OpenStack 技术为主的私有云集群在国内外不少业务团队中都有大规模的应用。它的最大好处就是可以整合企业内部的服务器资源,通过虚拟化技术进行按需分配,提高集群的资源使用率,节省成本。公有云集群现在越来越多的业务团队,尤其是初创公司,由于公有云快速灵活的特性,纷纷在公有云上搭建自己的业务。公有云最大的好处除了快速灵活、分钟级即可实现上百台机器的创建,还有一个好处就是配置统一、便于管理,不存在机器配置碎片化问题为了解决资源调度的问题,Docker 官方提供了 Docker Machine 功能。通过 Docker Machine,可以在企业内部的物理机集群、虚拟机集群(如 OpenStack 集群)或者公有云集群(如 AWS 集群)等上面创建机器并且直接部署容器。
虽然 Docker Machine 的功能很不错,但是对于大部分已经发展了一段时间的业务团队来说,并不能直接拿来使用。这主要是因为资源调度最大的难点并不在于机器的创建和容器的部署,而在于如何对接各个不同的集群,统一管理来自不同集群的机器权限管理、成本核算以及环境初始化等操作。在这种情况下,就需要有一个统一的层来完成这个操作。对于有历史包袱的团队,比如公司内网的物理机集群已经有一套运维体系的团队来说,这是一个不小的挑战,需要针对新的模式重新开发这套运维平台。
以微博的业务为例,为了满足内部三种不同集群资源的统一管理,专门研发了容器运维平台 DCP,来实现对接多个不同的集群。它的难点在于不仅对外要对接不同的云厂商,针对不同云厂商提供的 ECS 创建的 API,统一封装一层 API 来实现机器管理;对内也要针对私有云上不同集群的机器进行管理,进行上下线和配置初始化等操作。以 DCP 配置初始化操作为例,在创建完主机后,还需要在主机上进行安装 NTP 服务、修改 sysctl 配置、安装 Docker 软件等操作。这时候就需要借助配置管理软件来向主机上进行分发。因为微博内网的主机之前都是通过 Puppet 进行分发的,考虑到稳定性并没有对这一部分进行修改;而针对阿里云上创建的主机,则使用的是编程功能更为强大的 Ansible 进行分发
更多资讯,点击
