一位在科技公司工作的朋友最近和我吐槽,说她的工作几乎被大型语言模型“ChatGPT”占领了。
她担心这些智能系统会逐渐取代她。
也有人觉得,这些技术就只是炒作,根本不可能真正理解人类的语言和思维。
无论是哪种观点,问题的核心其实都在于:到底 Transformer 是怎么工作的?
就在几天前,我们一帮老朋友聚在一起,有人提出这个话题,瞬间点燃了大家的兴趣。
一番热烈讨论后,我决定来给大家仔细讲讲 Transformer 背后的故事和原理。
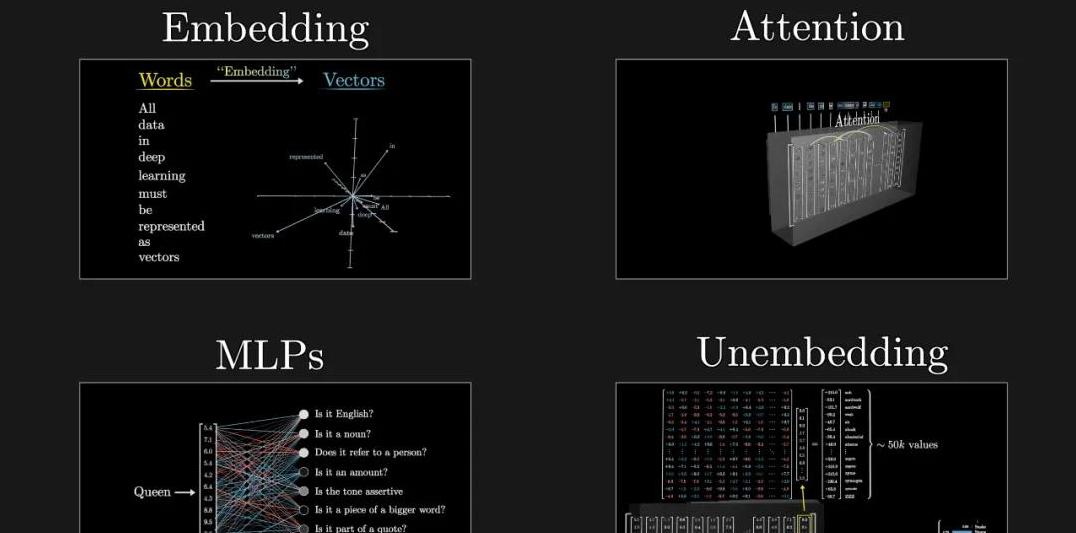
输入分词与嵌入矩阵先来说说输入分词。
当一个句子被输入时,它并不是以一整串字符进入系统的。

技术的“魔法”在这里开始运作:它会把输入文本拆分成一个个小单元,称为“token”,每个 token 都代表一个词或一个子词。
通过这种方式,系统可以更好地理解句子的组成部分。
接下来,每个 token 被映射成一个数值向量,这就是所谓的“嵌入矩阵”。
你可以把嵌入矩阵想象成一张非常大的表格,每一列代表一个 token,每一行代表它在高维空间中的位置。
相似意思的词语会聚集在一起,比如“国王”和“女王”会更靠近,而“苹果”和“计算机”则相对远一些。
注意力模块的重要性有了这些向量,接下来就进入了大名鼎鼎的“注意力模块”。
这部分是 Transformer 的核心,也是它如此强大的关键。
它让系统能够“注意”到哪部分信息是最重要的。

想象一下,你在听一个复杂的故事,一会儿提到主角,然后又跳到了另一个情节。
你必须不断调整自己的注意力以跟上故事的进展。
Transformer 中的注意力模块也做类似的事情。
它通过权重矩阵来决定某个词在句子中的重要性。
换句话说,它会特殊对待那些更有信息量的部分,让整体理解更清晰。
MLP 模块与输出生成接下来是多层感知机模块(MLP)。
这些模块就像是筛子,把信息进一步细化和优化。
它们通过一系列复杂的数学运算,保证每个向量表示出的语义尽量精准,这样模型在做预测时会更可靠。

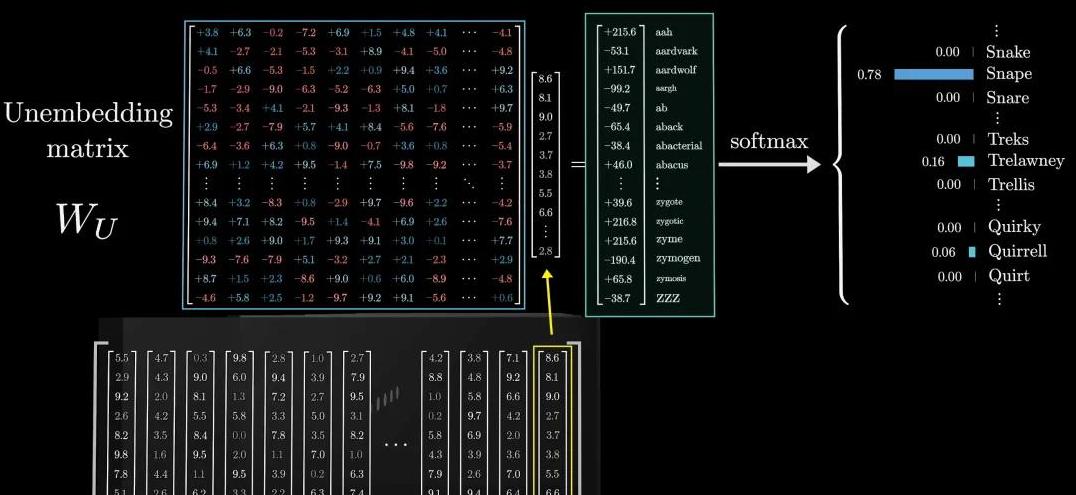
所有的这些信息被汇总,用来预测下一个 token。
这一步就是所谓的输出生成。
系统会根据上下文,给出所有可能的下一个词的概率分布,然后随机选择一个。
这种方式确保了生成的文本不仅是逻辑连贯的,还可能具有一定的创造性和多样性。
理解上下文与训练细节说到上下文理解,可以说是 Transformer 的拿手好戏。
传统的方法可能只能看有限的几个词,而 Transformer 可以处理更长的上下文。
这意味着它在理解语言时,可以考虑到更远的语义关系,就像你在一场长篇谈话中努力记住先前提到的点那样。
训练过程同样重要。
通过大量的文本数据进行训练,模型学会优化自身的参数,包括嵌入矩阵、注意力权重和 MLP 参数。
这个过程类似于小孩学说话,反复听、说、纠正,最终掌握语言的规律。
在这个过程中,反向传播算法发挥了关键作用。
简单来说,这种算法会在每次预测错误时调整模型的参数,以降低下一次出错的可能性。
可以说,这种持续改进的机制让 Transformer 能够不断进化,变得越来越聪明。
最后的调整是通过 Softmax 函数,它会将输出的值归一化为一个概率分布,确保所有值的总和为 1。
这一步有点像把一堆随机分散的意见汇总成一个集中的结论。
结尾那么,到底是什么让 Transformer 如此与众不同呢?
仔细想想,我们在理解语言时,也是在不断从周围的语境中吸取信息、不断调整自己的理解。
Transformer 模仿了这种人类的自然思维方式,使用注意力机制和多层感知机,确保能处理复杂的语言任务。
这样的技术究竟会带来什么样的未来?
无论是应用在自动翻译、文本生成,还是其他更多我们尚未想象到的领域,显然它为我们打开了新世界的大门。
我们可以选择拥抱这个时代的变革,也可以在应用中发现其局限并提出改进。
总之,了解这些技术的运作方式,无疑是我们在新时代立于不败之地的重要一步。
通过这次详尽讲解,希望能让大家对 Transformer 有了更清晰的认识。
当你下次使用 ChatGPT 或其他智能系统时,也能更加理解它背后的科学魔法。
让我们一起期待,未来还有更多的惊喜等待着我们。