田丰/文乔布斯认为,科技创新就像是地壳中的沉积岩,一层以一层为基础堆积起来,但每一层都很快被新的一层所覆盖,过去的创新工作很快会被新的技术和发现所取代,成为科技行业越来越庞大的“遗产”的一部分——更快的国产大模型科研创新“加速度”,成为国家综合科技实力的体现,同时作为“国之重器”,新一代人工智能技术引领国际前沿发展成为每一家中国原创AI团队的责任使命。笔者认为,2023年大模型产业将有以下十大趋势:
趋势一:人机交互越自然,使用人数越海量
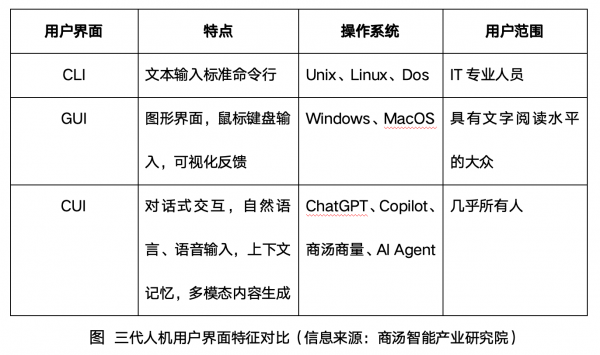
基于大语言模型的对话式交互,降低全民对AI工具的开发与使用门槛,将极大刺激AI市场需求的爆发。人机交互界面意味着人类指挥终端的效率和体验,早期专业技术人员使用的命令行界面(CLI),是让人说“机器的语言”,之后Windows和iPhone上受教育大众使用的图形界面(GUI),以人类操作图形来控制机器,再到如今众多模型、软件采用对话式交互界面(CUI),让机器、程序使用“人类的母语”(自然语言、方言)交流,包括多模态交互方式,让冷冰冰的机器“拟人化”,变身数字人伴侣、生产力助手,走入服务行业,智商与情感的双轨进步,让AI突破“图灵测试”,成为人类社会的“新成员”。
趋势二:智能云+智能端协同计算,AI设备嵌入“小模型”
AI云负责训练,AI终端负责推理,算力格局初显。目前AI写作、AI绘画、AI编程、AI生成视频、AI数字人、AI办公助手、AI营销助手、AI虚拟角色、智能驾驶等层出不穷的AIGC应用,预计将成为未来5年数字经济的新动能。每一次模型应用都是一次推理计算,虽然单次推理算力成本很低,但数亿用户进行数亿次推理时,推理算力的总成本,将超过训练算力总成本。伴随爆款AIGC应用的出现,庞大的用户访问量持续推高推理计算成本,将带来“AI云-AI端”的算力分工与转移。
同时,小模型正在拥有大模型的效果,以及硬件终端算力的良好适配性与功耗。法国创业公司研发的Mixtral8x7B模型凭借70亿参数量,在大多数国际标准基准测试中与GPT3.5相匹配甚至更优(1750亿参数量)。而另一方面,微软凭借27亿参数量的Phi-2,在各种综合基准测试中,其性能超过了Mistral(70亿参数)和Llama-2模型(130亿参数)。在多步推理任务(即编码和数学)上,它比25倍大的Llama-2-70B模型具有更好的性能。
趋势三:多模态大模型,成为“生产力遥控器”
多模态大模型降低生产成本,激活指数级市场需求,通信革命将开启新一轮工业革命。大语言模型被视为新一代人机通信革命,当新一代“应用软件”(AI模型)与新一代“硬件终端”(机器人、AR眼镜等)加速融合后,下一轮工业革命大幕拉开。在供给侧,基于大模型的智能体变成人类的“生产力遥控器”。伴随AI芯片嵌入智能车、智能机器人、智能AR眼镜、智能家电等所有终端,人类个体在“人机协同”模式下能够同时指挥的生产资料规模大幅上升。
趋势四:智能基建重资产投入,发展空间巨大
大模型、大计算、大数据都具有重资产投入的发展特征。智能计算基础设施在长周期建设过程中,具有“资本密度”、“算力密度”、“数据密度”持续增加的特征,目前投资总额尚具有极大提升空间,将不断增强我国经济的比较优势。
传统经济学理论中,新型社会基础设施的重大意义在于促进技术进步、提高生产率、加速内生经济增长,具有良好的“正外部性”与“网络效应”。数字中国建设,与“数字基础设施互联互通”、“数据资源规模和质量”紧密相关。在中国“智能计算基建化,传统基建智能化”的过程中,科技创新是推动经济增长、社会基础设施高质量发展的源动力,而智能计算基础设施具有边际成本持续下降、边际效益持续增长的特征。
趋势五:更便宜的AI芯片价格,将加速AIGC应用创新规模化扩张
AI芯片已成为AI从业者的沉重“税负”,让AI算力成本回归社会公共服务的平民价格,是数字经济3.0可持续发展的关键。市场上AI算力的稀缺为少数芯片制造商带来巨大的市场控制权,并享受涨价带来的高额利润。据美国金融机构RaymondJames透露,头部AI芯片公司的利润率可能高达1000%。在《埃隆·马斯克传》中,马斯克提出“白痴指数”,从第一性原理(物理学)出发,计算成品总成本与基本原材料成本的比值,如果一个产品的白痴指数非常高,则可通过设计更高效的制造技术来大幅降低成本,例如传统火箭上一个组件的成本是1000美元,而其铝材料成本只有100美元,那么可能因为设计过于复杂或制造工艺过于低效。虽然我们不知道GPU的生产成本,但经济学原理来看,在如此高额利润的刺激下,更多低价格的竞争对手(含国产AI芯片)将会涌现,让AI芯片回归公共基础设施的本质,因为水电基础服务不会比金子更贵,在AI芯片架构研发与生产工艺创新中,更多价值将逐步从芯片释放出来,向算力服务、模型服务、AI2.0应用转移。反之,长期过于昂贵的AI芯片价格,会让面向大众市场(toConsumer)的所有AIGC创新应用,因昂贵的“芯片税”而衰败,无法形成“数字经济3.0”的创新浪潮。
趋势六:更便宜的能源,更大的模型产能
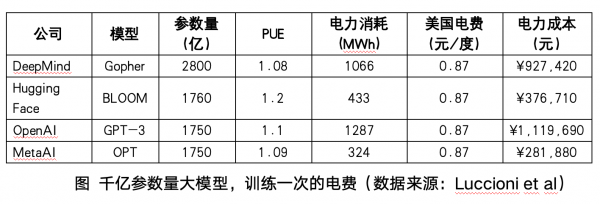
算力消耗的能源是另一半AIGC创新应用必须分摊的成本,持续降低的能源成本,对AI2.0应用生态健康良性发展至关重要。
以Meta研发的语言大模型LLaMA为例,训练LLaMA-65B(650亿参数量,属于中等规模)的耗电,以美国电价0.87元/度估算,需要449W*1022362h*0.87=408944800元,约40万元人民币。而OpenAI的GPT-3耗电量高达1287兆瓦时,伴随大模型参数量、数据量的上涨,能源支出成本将会急剧上升,产业链最终将成本分摊到每一个AIGC应用、AIforScience科研项目、智能制造系统上,引发AI2.0应用的“成本门槛”压抑大众创新需求。大模型产业数据分析显示,大语言模型的训练成本中,电力费用占比高达65%。当“万亿参数量”的GPT-4,以及更大规模参数量的GPT-5到来时,能源与算力成本将会扭曲商业逻辑,或让很多应用创业者望而却步。
趋势七:跨语言、跨时空的全球知识传播速度,史无前例提高
博古通今的大模型,引发“知识生产力变革”,大模型是知识工程的生产力变革,天然具有跨领域知识的连接性。据多方研究数据表明,大型语言模型显著提高知识学习速度、知识检索速度、知识传播速度、知识推荐准确性,具有跨语言、跨学科领域、跨信源的独特优势。在人机协同模式下,大型语言模型将人类科学论文的阅读时间缩短40%,知识搜索时间缩短20%,而这仅仅是ChatGPT出现一周年的“起点”,鉴于大型语言模型远超人类的超高速学习能力,预计将在2026年学习完所有人类历史上的高质量文本数据。人类的知识革命大幕刚刚开启,高新科研、三大类产业、公共服务的知识型工作范式正在遵循“计算->数据->模型->服务”链条重构。
趋势八:每一次软件革新,都孕育“新一代超级平台”
大模型引发“软件变革”,每一次软件大革新,都会诞生新的超级平台企业,颠覆原有的数字经济霸主,从Windows、AppStore到GPTs都不例外,当前智能编程助手改变代码生产流程,大型语言模型成为新一代AGI服务入口、软件调度枢纽。多篇权威论文显示,大型语言模型能够面对复杂任务,灵活自动实现多软件串行、多模型协同组合,例如AIAgent、MoE架构(Mixture-of-Experts)、综合型智能客服、GitHubCopilot等,能在日常使用中跨模型共享成果、快速学习迭代、增强安全性与伦理性保障。在庞大AI算力规模、训练数据集基础上,新一代AI原生软件应用,导致“传统软件智能化,智能软件枢纽化”全面普及,尤其是那些能满足目前还难以预知需求的新工具,新一代青少年将在新兴AI软件与MaaS模型化创新思维逻辑上成长起来,并将新型生产力软件带入办公室与家庭。
趋势九:新一代AI计算架构革新,即将到来
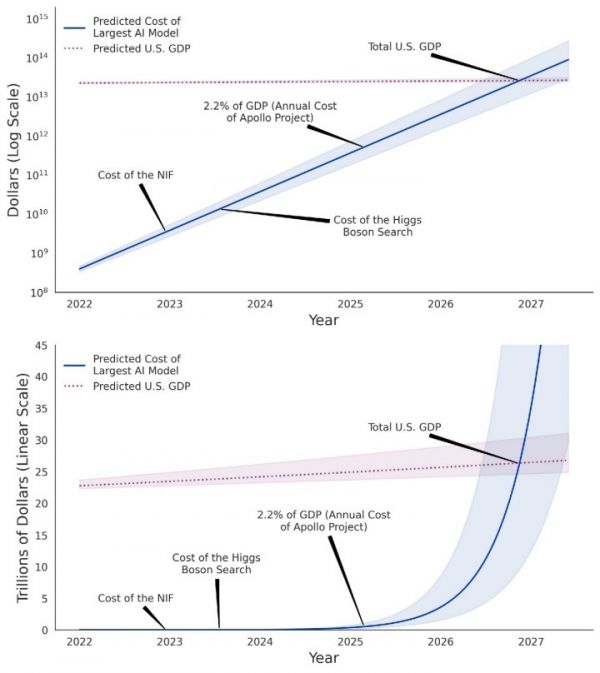
大模型成为社会型公共服务的前提,是“AI计算变革”,在大型语言模型的ScalingLaw(规模定律)指数级算力需求,与线性增长的区域基建投入矛盾下,AI算力基础设施将迎来大量技术工程创新,持续降本增效,普惠优势让AI真正成为赋能千行百业的通用型基础设施,同时“百模大战”变为AI产业专业化分工。据AINow《计算能力和人工智能》报告指出,早期AI模型算力需求是每21.3个月翻一番,而2010年深度学习后(小模型时代),模型对AI算力需求缩短至5.7个月翻一番,而2023年,大模型需要的AI算力需求每1-2个月就翻一番,摩尔定律的增速显著落后于社会对AI算力的指数级需求增长速度,即“AI超级需求曲线”遥遥领先传统架构的AI算力供给,带来了AI芯片产能瓶颈、涨价等短期市场现象。
趋势十:全球AI人才能力培养,成为大国责任
中美构建起全球大模型技术创新的“双螺旋”,新一代人工智能人才培养首当其冲。据科技部发布的《中国人工智能大模型地图研究报告》显示,上海市通过发布《上海市推动人工智能大模型创新发展的若干措施》等一系列政策,孵化出17个国产大模型。纵观国际格局,在AMiner大数据平台、智谱研究发布的《全球人工智能创新城市500强分析报告》中提出“2023年全球人工智能最具创新力城市排名”,上海的人工智能创新指数进入全球TOP10。在全球AI创新力城市TOP100中美国33个城市入选,在TOP500里中国42个城市入选。如何缩小中美之间的差距,需要从K12中小学生、社会职业培训两个方面入手,让大模型走入所有中国学校的课堂和家庭,让每一位中国人都能接触到学习调优、使用国产大模型的课程,着力培养当前和未来的AI工程师。
(作者系商汤科技智能产业研究院院长)
