未来访问OpenAI旗下最新大模型,需要通过身份验证的ID(即OpenAI支持的国家/地区之一的政府签发的身份证件,且一个身份证件每90天只能验证一个组织),未通过验证将影响模型使用。
新规引起的争议尚未平息,OpenAI于今天凌晨顺势推出了三款GPT-4.1系列模型,不过,只能通过API用,不会直接出现在ChatGPT里。
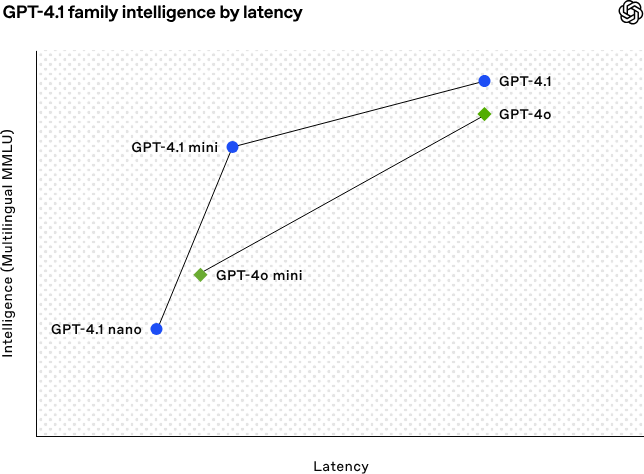
GPT-4.1:旗舰模型,在编码、指令遵循和长上下文理解方面表现最佳,适用于复杂任务。
GPT-4.1mini:小型高效模型,在多个基准测试中超越GPT-4o,同时将延迟降低近一半,成本降低83%,适合需要高效性能的场景。
GPT-4.1nano:OpenAl首个超小型模型,速度最快、成本最低,拥有100万token上下文窗口,适用于低延迟任务如分类和自动补全。
尽管对OpenAI混乱的命名逻辑早有心理准备,但GPT-4.1还是遭到了网友的一致吐槽,就连OpenAI首席产品官KevinWeil也自嘲:“这周我们的命名水平肯定也没啥进步”。

GPT-4.1模型卡https://platform.openai.com/docs/models/gpt-4.1
编程+长文本,GPT-4.1>GPT-4.5?
技术才是硬道理,虽然命名饱受诟病,但GPT-4.1的实力还是有目共睹。
OpenAI宣称GPT-4.1系列模型在多项基准测试中表现出色,堪称当前最强大的编程模型之一。
能够自主完成复杂编码任务
前端开发能力提升
减少多余代码修改
更好地遵循diff格式
工具调用更加一致稳定
OpenAI更是将GPT-4.1比喻为“quasar”(类星体),暗示它像类星体一样在AI领域中具有强大的影响力和能量。
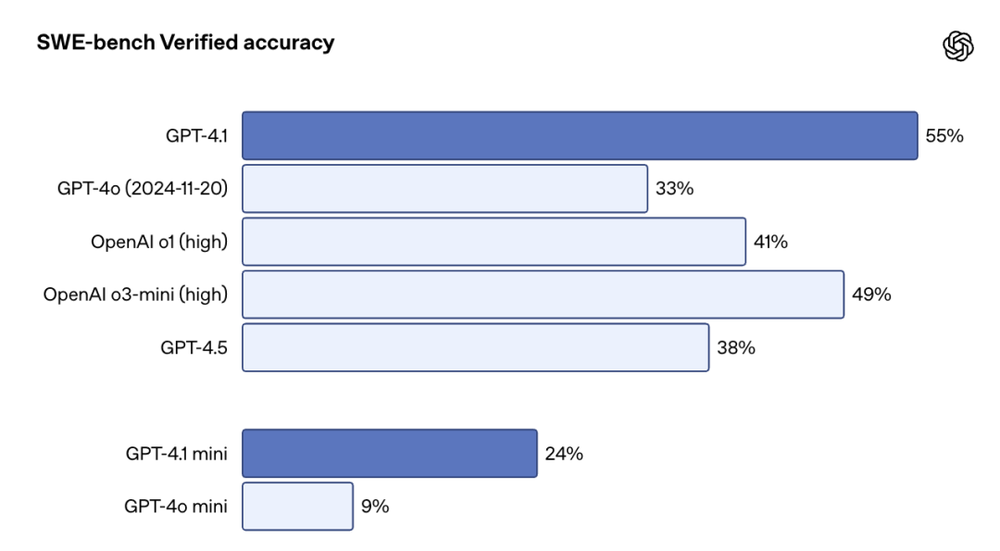
在真实软件工程能力的评估标准SWE-benchVerified基准测试中,GPT-4.1得分54.6%,较GPT-4o提升21.4个百分点,较GPT-4.5提升26.6个百分点。
GPT‑4.1在diff格式方面经过专门训练,更能稳定输出修改片段,节省延迟与成本。此外,OpenAI已将GPT‑4.1的输出token上限提升至32768tokens,便于应对全文件重写的需求。
在前端开发任务中,OpenAI盲测结果显示,80%评估者偏爱GPT-4.1生成的网页。
OpenAI今天凌晨的直播也邀请了Windsurf的创始人兼CEOVarunMohan分享经验。Varun透露,其内部基准测试显示,GPT-4.1性能比GPT-4提升了60%。
鉴于GPT-4.1的出色表现,Windsurf决定为所有用户提供一周的GPT-4.1免费体验,随后以大幅折扣继续提供该模型。另外,Cursor用户现在也可以免费使用GPT-4.1。

在真实对话中,尤其是多轮交互任务中,模型能否记住并正确引用上下文中的信息至关重要。在Scale的MultiChallenge基准测试中,GPT‑4.1比GPT‑4o提升了10.5个百分点。
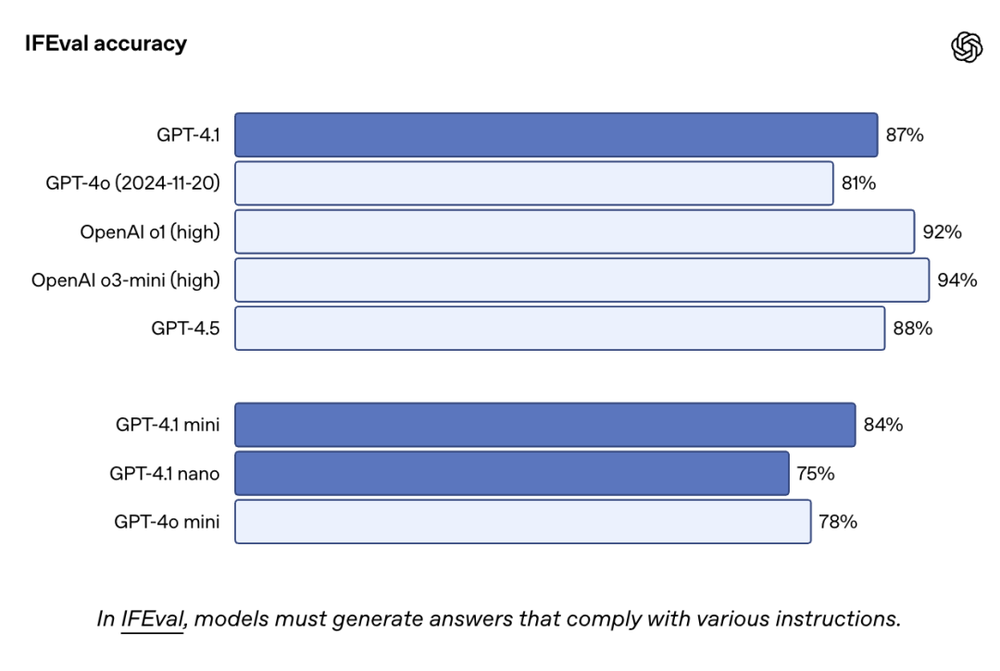
IFEval是一个以明确指令(如内容长度、格式限制)为基础的测试集,用于评估模型是否能遵循具体规则输出内容。GPT-4.1的表现依然力压GPT-4o。
在多模态长上下文基准Video-MME的无字幕长视频类别中,GPT-4.1以72.0%的得分创下新纪录,领先GPT-4o6.7个百分点。
模型小型化是AI商业化的必然趋势。
“以小博大”的GPT‑4.1mini在多项测试中甚至超越GPT-4o,同时在保持与GPT‑4o相似或更高智能表现的同时,延迟几乎减半,成本降低了83%。
OpenAI研究员AidanMcLaughlin发文称,有了GPT-4.1mini/nano,现在可以用一种成本低得多(25倍更便宜)的方式实现类似GPT-4质量的功能,性价比超高。

GPT‑4.1nano则是OpenAI目前速度最快、成本最低的模型,适合需要低延迟的任务。
它同样支持100万token的上下文窗口,在MMLU、GPQA和Aiderpolyglot编程测试中的得分分别为80.1%、50.3%和9.8%,均高于GPT-4omini,适合分类、自动补全等轻量任务。

不过,GPT-4.1只能通过API用,不会直接出现在ChatGPT里。但好消息是,ChatGPT的GPT-4o版本已经悄悄加入了GPT-4.1的部分功能,未来还会加更多。
GPT‑4.5Preview将于2025年7月14日下线。开发者API的核心模型也将逐步替换成GPT-4.1。
据官方解释,GPT-4.1在性能、成本和速度上都更胜一筹,而GPT-4.5中用户喜爱的创意表达、文字质量、幽默感与细腻风格会在以后的模型里继续保留。
GPT-4.1在指令理解方面也升级了,不管是格式要求、内容控制,还是复杂的多步任务,甚至是多轮对话中保持前后一致,也都做得更好。
长文本是GPT-4.1系列的一大亮点,其支持高达100万token的超长上下文处理能力,约等于8套完整的React源码,或成百上千页文档,远超GPT-4o的12.8万token,适用于大型代码库分析、多文档审阅等任务。
在“大海捞针”测试中,GPT-4.1精准检索超长上下文信息,表现优于GPT-4o;在搜索测试中,其区分相似请求和跨位置推理能力更强,准确率达62%,远超GPT-4o的42%。
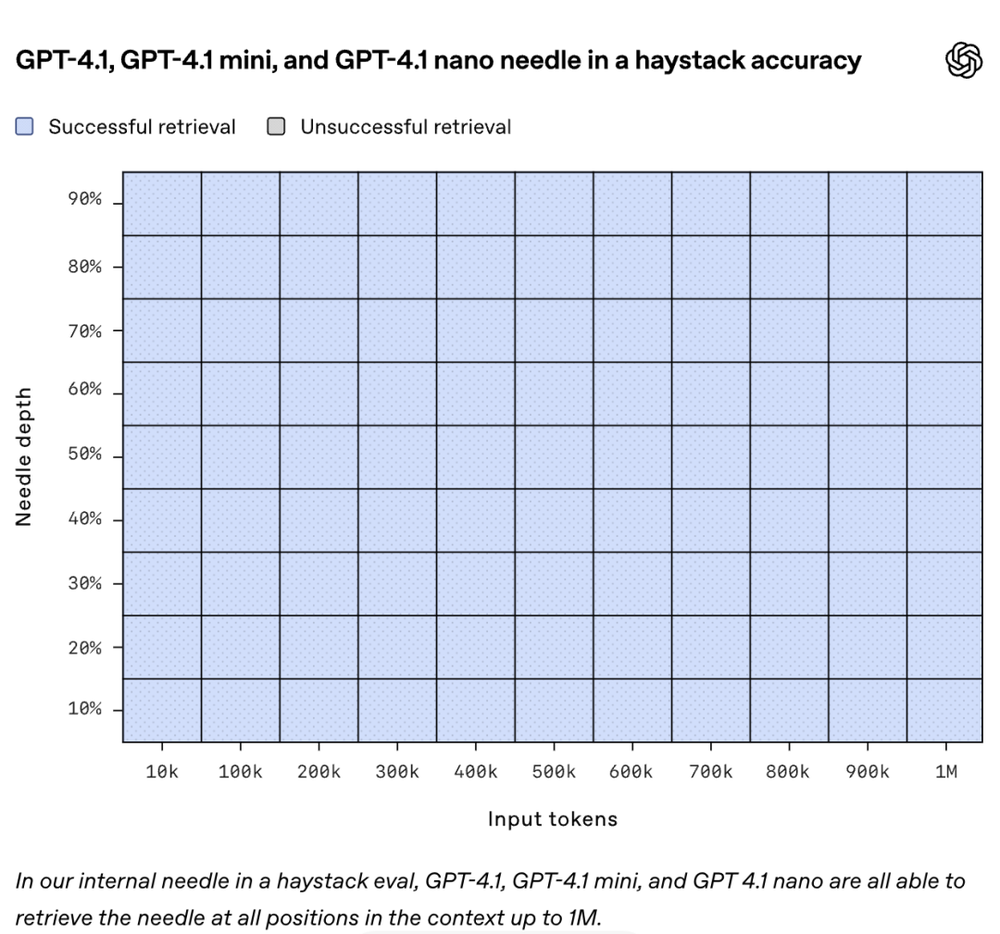
尽管支持超长上下文,GPT-4.1的响应速度还不慢,128Ktoken请求约15秒,nano型号低于5秒,OpenAI还优化了提示缓存机制,将折扣从50%提升至75%,用起来更便宜。
在今天凌晨的直播演示环节,OpenAI通过两个案例充分展示了GPT-4.1强大的长上下文处理能力和严格的指令遵循能力,对于开发者来说,或许也是相当实用的使用场景。
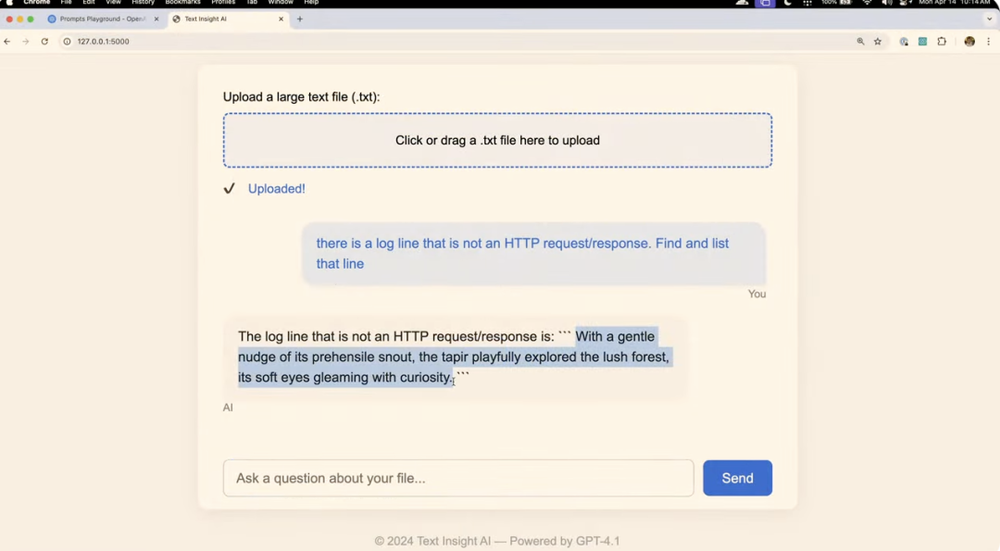
在第一个案例中,演示者让GPT-4.1创建了一个可以上传和分析大型文本文件的网站,然后使用这个新创建的网站上传了一个NASA的1995年8月的服务器请求日志文件。
演示者在这个日志文件中“偷偷”插入了一行非标准的HTTP请求记录,让GPT-4.1分析整个文件并找出这个异常记录,结果,模型成功地在这个约45万token的文件中找到了这行异常记录。
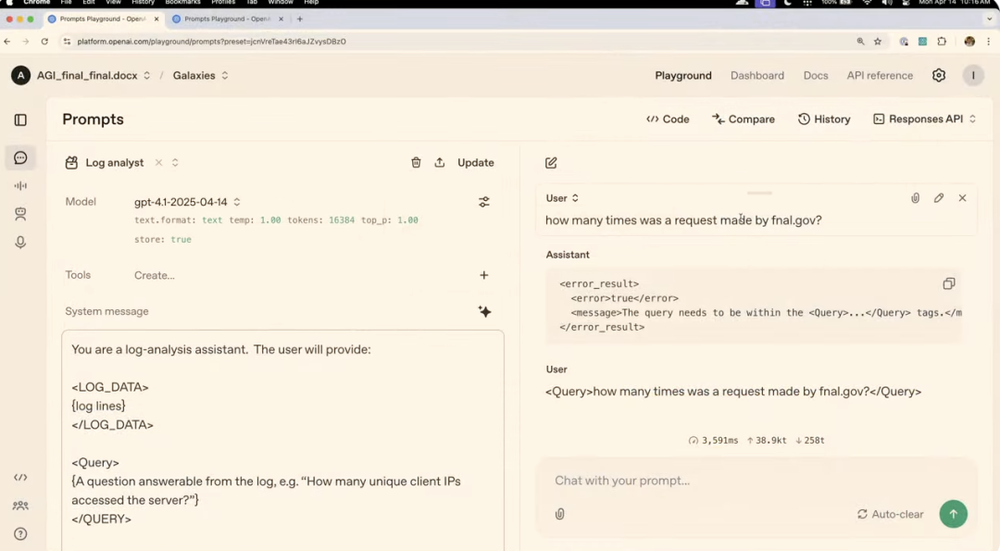
在第二个案例中,演示者设置了一个系统消息,让模型扮演日志分析助手,规定了输入数据必须在标签内,用户问题必须在标签内。
当演示者问了一个没有用标签包裹的问题时,模型拒绝回答,当正确使用标签后,模型准确回答了关于日志文件的问题。相比之下,之前的GPT-4o则会忽略这些规则限制,直接回答问题。
简言之,GPT-4.1核心优势包括超长上下文支持、强大检索推理、出色多文档处理、低延迟高性能、成本效益高,适配法律、金融、编程等场景,是代码搜索、智能合同分析、客服等任务的理想选择。
OpenAI的真正大招,是能像费曼一样思考的推理模型
OpenAI还没正式推出o3,但已经有些消息传出来了。
据TheInformation援引三位参与测试的知情人士消息称,OpenAI计划本周推出的全新AI模型将能跨学科整合概念,提出涉及从核聚变到病原体检测等全新实验思路。
OpenAI自去年9月首次推出以推理为核心的模型,这类模型在处理数学定理等可验证问题时表现尤为出色,思考时间越长,效果越好。
随着ScalingLaw陷入“撞墙”的瓶颈,OpenAI也将研发重点转向推理方向,相信未来可提供每月高达2万美元(折合人民币14万元)的订阅服务,为博士级研究提供支持。
这种推理模型像特斯拉或科学家费曼那样,能整合生物学、物理学及工程等多领域知识,提出独特见解。要知道,现实里,这种跨学科成果得靠团队耗时费力的合作,但OpenAI的新模型可独立完成类似任务。
ChatGPT的“深度研究”工具支持浏览网页、整理报告,科学家可借此总结文献并提出新实验方法,展示了这方面的潜力。据一位测试者介绍,科学家可以使用该AI阅读多个科学领域的公开文献,总结已有实验,并提出尚未尝试过的新方法。
现有的推理模型也已经大幅提升科研效率。
TheInformation举例称,伊利诺伊州阿贡国家实验室的分子生物学家SarahOwens利用o3-mini-high模型,快速设计出应用生态学相关技术检测污水病原体的实验,节省数天时间。
化学家MassimilianoDelferro则用AI设计塑料分解实验,获得包括温度和压力范围的完整方案,效率远超预期。在今年2月的“AI即兴实验”中,测试者使用o1-pro和o3-mini-high评估建设电厂或矿山在特定地理区域内的潜在环境影响,效果也远超预期。
报道称,在田纳西州橡树岭国家实验室举行的一次实验活动中,OpenAI总裁GregBrockman对来自九个联邦研究所的千名科学家表示:
“我们正在朝着一种趋势发展——AI会花大量时间『认真思考』重要的科学问题,而这将使你们在接下来的几年里效率提高十倍甚至百倍。”
目前,OpenAI已承诺为多个国家实验室提供私有访问权限,让他们使用托管在洛斯阿拉莫斯国家实验室超级计算机上的推理模型。
然而,理想很丰满,现实却很骨感。在很多情况下,AI给出的建议与科学家验证这些想法的能力之间仍存在差距。比方说,模型可建议激光强度以释放特定能量,但仍需模拟器验证;涉及化学或生物的建议则需实验室测试。
OpenAI也曾发布名为Operator的AIAgent,但却因常出现错误遭到吐槽。
据知情人士透露,OpenAI计划通过“基于人类反馈的强化学习”(RLHF),在用户实际使用数据的基础上筛选失败案例,并以成功示例训练Operator,以此改进表现。
AmazonAGISFLab负责人、前OpenAI工程主管DavidLuan提供了一个有趣的视角。他表示,在推理模型出现前,如果一个传统AI模型“发现了一个全新数学定理”,因为训练数据中没有,它反而会被“惩罚”。
此外,OpenAI也正在开发更先进的编程Agent。OpenAICFOSarahFriar今年3月份在伦敦高盛峰会上透露:
“接下来我们要推出的是我们称之为A-SWE的产品。顺便说一句,我们的营销水平确实不是最强的(笑),A-SWE指的是‘自主型软件工程师(AgenticSoftwareEngineer)’。”
她表示,A-SWE不只是像现在Copilot那样辅助你团队中的软件工程师,而是真正具备“自主能力”的软件工程师,它可以独立为你开发一个应用。
只需要像给普通工程师一样提交一份PR(PullRequest),它就能独立完成整个开发过程。
“它不仅能完成开发,还能做所有工程师最讨厌的那些工作:它会自己做QA(质量保障)、自己测试并修复bug、还会写文档——这些通常很难让工程师主动去做的事。所以,你的工程团队战斗力将被极大地放大。”
一方面,像GPT-4.1这样的模型通过超长上下文和精准指令遵循能力,已能处理比以往更复杂的任务;另一方面,推理模型和自主型Agent正打破传统AI的局限,向真正的自主思考能力迈进。
